Büyük Veri: Bilmeniz Gereken Araçlar ve Teknolojiler
Yayınlanan: 2018-03-09Ayrıca, herhangi bir etki alanı veya endüstrinin (sadece adını verin!) Büyük Veriyi iyi bir şekilde kullanarak operasyonlarını nasıl iyileştirebileceğini gördük . Kuruluşlar bu gerçeği anlıyor ve doğru insan grubunu işe almaya, onları doğru araç ve teknolojilerle donatmaya ve Büyük Verilerini anlamlandırmaya çalışıyor .
Gittikçe daha fazla kuruluş bu gerçeği fark ettikçe, Veri Bilimi pazarı da onunla birlikte daha hızlı büyüyor. Büyük veri araçları ve teknolojilerinde muazzam bir büyümeyle sonuçlanan bu pastadan herkes pay almak istiyor .
youtube videosunu izleyin.
Bu yazıda, büyük veri vagonuna atlarken araç setinizde olması gereken doğru araçlar ve teknolojiler hakkında konuşacağız . Bu araçlara aşina olmak, karşılaşabileceğiniz yaklaşan görüşmelerde de size yardımcı olacaktır.
İçindekiler
Hadoop Ekosistemi
Odadaki filden bahsetmeden Büyük Veri hakkında konuşamazsınız (kelime anlamı!) – Hadoop. 'Yüksek kullanılabilirlikli dağıtılmış nesne yönelimli platform'un kısaltması olan Hadoop, esasen bakım, kendi kendini iyileştirme, hata işleme ve büyük veri kümelerinin güvenliğini sağlamak için kullanılan bir çerçevedir. Bununla birlikte, yıllar içinde Hadoop, ilgili araçlardan oluşan tüm bir ekosistemi kapsadı . Sadece bu değil, çoğu ticari Büyük Veri çözümü Hadoop'a dayanmaktadır.

Tipik bir Hadoop platform yığını, HDFS, Hive, HBase ve Pig'den oluşur.
HDFS
Hadoop Dağıtılmış Dosya Sistemi anlamına gelir. Hadoop için dosya depolama sistemi olarak düşünülebilir. HDFS, büyük veri kümelerinin dağıtımı ve depolanmasıyla ilgilenir.

Harita indirgeme
MapReduce, büyük veri kümelerinin paralel olarak hızla işlenmesine olanak tanır. Basit bir fikri takip ediyor - çok az zamanda çok fazla veriyle uğraşmak, sadece iş için daha fazla işçi istihdam etmek. Tipik bir MapReduce işi iki aşamada işlenir: Eşle ve Küçült. "Harita" aşaması, bir Hadoop kümesindeki çeşitli düğümlere işlenmek üzere bir sorgu gönderir ve "Küçült" aşaması, tüm sonuçları tek bir değerde çıktı almak için toplar. MapReduce işleri planlamak, işleri izlemek ve başarısız olan görevi yeniden yürütmekle ilgilenir.
kovan
Hive, sorgu dilini MapReduce komutlarına dönüştüren bir veri ambarı aracıdır. Facebook tarafından başlatıldı. Hive kullanmanın en iyi yanı, Hive klasik SQL'e benzer bir sözdizimine sahip HQL (Hive Query Language) kullandığından geliştiricilerin mevcut SQL bilgilerini kullanabilmeleridir.
HBase
HBase, yapılandırılmamış verilerle gerçek zamanlı olarak ilgilenen ve Hadoop'un üzerinde çalışan, sütun odaklı bir DBMS'dir. SQL, yapılandırılmış verilerle ilgilenmediği için HBase'de sorgulama yapmak için kullanılamaz. Bunun için Java tercih edilen dildir. HBase, büyük veri kümelerini gerçek zamanlı olarak okuma ve yazma konusunda son derece verimlidir.
Domuz
Pig, Yahoo! tarafından başlatılan üst düzey bir prosedürel programlama dilidir. Ve 2007'de açık kaynak oldu. Kulağa ne kadar garip gelse de buna Pig deniyor çünkü üzerine attığınız her türlü veriyi işleyebiliyor!
Kıvılcım
Apache Spark, Büyük Veri işleme için en hızlı motor olduğu için bu listede özel olarak anılmayı hak ediyor . Amazon, Yahoo!, eBay ve Flipkart gibi büyük oyuncular tarafından kullanılmaya başlandı. Spark tarafından desteklenen tüm organizasyonlara bir göz atın , şaşıracaksınız!
Spark, programları bellekte yüz kata kadar ve diskte on kata kadar daha hızlı çalıştırmanıza izin verdiği için birçok yönden Hadoop'u eski haline getirdi. 
Hadoop'un tanıtıldığı niyetleri tamamlar . Büyük veri kümeleriyle uğraşırken, en büyük endişelerden biri işlem hızıdır, bu nedenle, her sorgunun yürütülmesi arasındaki bekleme süresini kısaltmaya ihtiyaç vardı. Ve Spark, akış, grafik işleme, makine öğrenimi ve SQL desteği için yerleşik modülleri sayesinde tam olarak bunu yapar. Ayrıca en yaygın programlama dillerini de destekler – Java, Python ve Scala.

Spark'ı tanıtmanın arkasındaki ana sebep, Hadoop'un hesaplama süreçlerini hızlandırmaktı. Ancak, ikincisinin bir uzantısı olarak görülmemelidir. Aslında Spark, Hadoop'u yalnızca iki ana amaç için kullanır: depolama ve işleme. Bunun dışında, oldukça bağımsız bir araçtır.
NoSQL
Geleneksel veritabanları (RDBMS), satırları ve sütunları tanımlayarak bilgileri yapılandırılmış bir şekilde depolar. Orada mümkündür çünkü depolanan veriler yapılandırılmamış veya yarı yapılandırılmış değildir. Ancak Büyük Veri ile uğraşmaktan bahsettiğimizde, büyük ölçüde yapılandırılmamış veri kümelerinden bahsediyoruz. Bu tür veri kümelerinde, S (yapı) burada bulunmadığından SQL kullanarak sorgulama çalışmaz. Bununla başa çıkmak için NoSQL veritabanlarımız var.

NoSQL veritabanları, yapılandırılmamış verilerin depolanmasında uzmanlaşmak ve hızlı veri alımı sağlamak için oluşturulmuştur. Ancak, geleneksel veritabanlarıyla aynı düzeyde tutarlılık sağlamazlar - bunun için onları suçlayamazsınız, verileri suçlayın!
En popüler NoSQL veritabanları MongoDB, Cassandra, Redis ve Couchbase'dir. Önde gelen RDBMS satıcıları olan Oracle ve IBM bile, kullanımındaki hızlı büyümeyi gördükten sonra artık NoSQL veritabanları sunuyor.
Veri Gölleri
Veri gölleri, son birkaç yılda kullanımlarında sürekli bir artış gördü. Bununla birlikte, birçok insan hala Veri Göllerinin yalnızca Veri Ambarı'nın yeniden ziyaret edildiğini düşünüyor - ancak bu doğru değil. İkisi arasındaki tek benzerlik, ikisinin de veri depolama havuzları olmasıdır. Açıkçası, bu kadar. 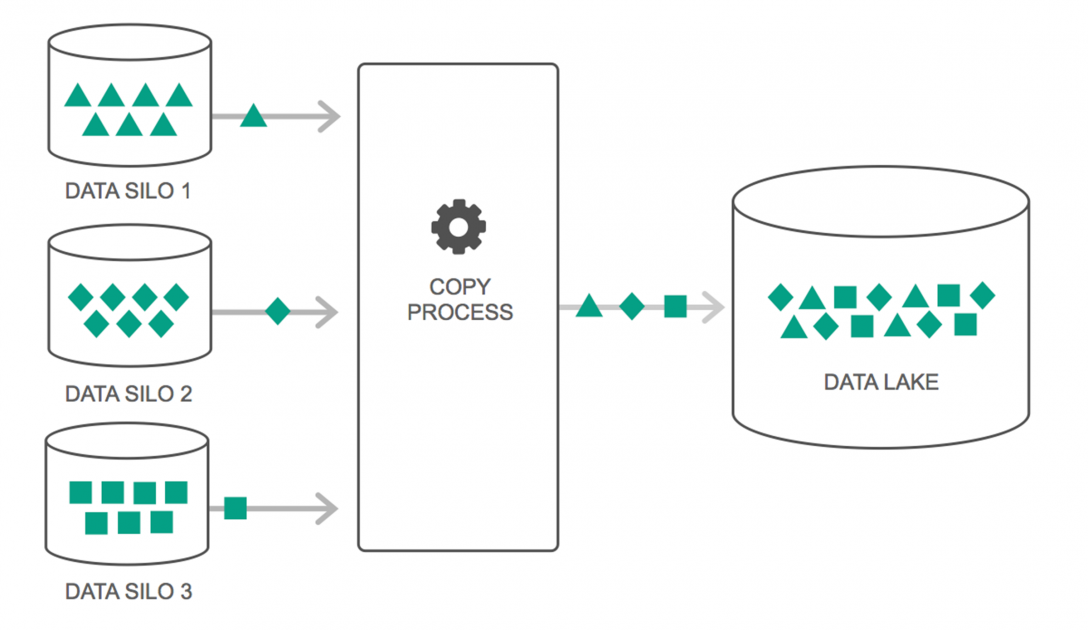
Veri Gölü, çeşitli kaynaklardan çok miktarda ham veriyi çeşitli biçimlerde, ihtiyaç duyulana kadar tutan bir depolama havuzu olarak tanımlanabilir. Veri ambarlarının verileri hiyerarşik bir klasör yapısında sakladığını bilmelisiniz, ancak Data Lakes'te durum böyle değil. Veri Gölleri, veri kümelerini kaydetmek için düz bir mimari kullanır.
Birçok kuruluş, Büyük Verilerine erişim sürecini basitleştirmek için Veri Göllerine geçiş yapıyor . Veri Gölleri, verileri depolamadan önce işleyen bir veri ambarının aksine, toplanan verileri doğal hallerinde saklar. Bu yüzden “göl” ve “depo” metaforu uygundur. Veriyi su olarak görüyorsanız, bir veri gölü, suyu filtrelenmemiş ve doğal haliyle saklayan bir su gölü olarak düşünülebilir ve bir veri ambarı, şişelerde depolanan ve rafta tutulan su olarak düşünülebilir.

Bellek İçi Veritabanları
Herhangi bir bilgisayar sisteminde, RAM veya Rastgele Erişim Belleği, işlemi hızlandırmaktan sorumludur. Benzer bir felsefe kullanılarak, sisteminizi verilere götürmek yerine Verilerinizi sisteminize taşıyabilmeniz için bellek içi veritabanları geliştirildi. Bunun esas olarak anlamı, verileri bellekte saklarsanız, işlem süresini oldukça azalacaktır. Tüm veriler bellekte olacağından, veri alma ve alma artık zahmetli olmayacak.
Ancak pratikte, gerçekten büyük bir veri kümesiyle uğraşıyorsanız, hepsini bellekte almak mümkün değildir. Ancak, bunun bir kısmını bellekte tutabilir, işleyebilir ve daha sonra işlemek üzere başka bir bölümünü bellekte getirebilirsiniz. Buna yardımcı olmak için Hadoop , işlemeyi hızlandırmak için hem diskte hem de bellekte veritabanlarını içeren çeşitli araçlar sağlar.
Kapatılıyor…
Bu makalede verilen liste hiçbir şekilde “kapsamlı bir Büyük Veri araçları ve teknolojileri listesi” değildir. Bunun yerine, “bilinmesi gereken” Büyük Veri araçlarına ve teknolojilerine odaklanır . Büyük Veri alanı sürekli gelişiyor ve yeni teknolojiler eskileri çok hızlı bir şekilde güncelliğini yitiriyor. Hadoop-Spark yığınının ötesinde Finch, Kafka, Nifi, Samza ve daha pek çok teknoloji var. Bu araçlar , hıçkırık olmaksızın kusursuz sonuçlar sağlar. Bunların her birinin kendine özgü kullanım durumları vardır, ancak bunlardan herhangi biri üzerinde çalışmaya başlamadan önce, makalede bahsettiklerimizden haberdar olmanız önemlidir.
Büyük Veri hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 7+ vaka çalışması ve proje sağlayan, 14 programlama dili ve aracını kapsayan, pratik uygulamalı Büyük Veride Yazılım Geliştirme Uzmanlığı programında PG Diplomamıza göz atın çalıştaylar, en iyi firmalarla 400 saatten fazla titiz öğrenim ve işe yerleştirme yardımı.
Yazılım Mühendisliği derecelerini dünyanın en iyi üniversitelerinden çevrimiçi öğrenin . Kariyerinizi hızlandırmak için Yönetici PG Programları, Gelişmiş Sertifika Programları veya Yüksek Lisans Programları kazanın.