Big Data : outils et technologies indispensables
Publié: 2018-03-09Nous avons également vu comment n'importe quel domaine ou industrie (vous n'avez qu'à le nommer !) pourrait améliorer ses opérations en utilisant le Big Data à bon escient . Les organisations prennent conscience de ce fait et essaient d'intégrer le bon groupe de personnes, de les doter du bon ensemble d' outils et de technologies et de donner un sens à leur Big Data .
Alors que de plus en plus d'organisations prennent conscience de ce fait, le marché de la science des données se développe d'autant plus rapidement. Tout le monde veut une part de ce gâteau, ce qui a entraîné une croissance massive des outils et technologies du Big Data.
Regardez la vidéo youtube.
Dans cet article, nous parlerons des bons outils et technologies que vous devriez avoir dans votre boîte à outils lorsque vous sautez dans le train du big data. La connaissance de ces outils vous aidera également dans les entretiens à venir auxquels vous pourriez être confronté.
Table des matières
Écosystème Hadoop
Vous ne pouvez pas parler de Big Data sans mentionner l'éléphant dans la pièce (jeu de mots !) - Hadoop. Acronyme de "plate-forme orientée objet distribuée à haute disponibilité", Hadoop est essentiellement un cadre utilisé pour la maintenance, l'auto-réparation, la gestion des erreurs et la sécurisation de grands ensembles de données. Cependant, au fil des ans, Hadoop a englobé tout un écosystème d' outils connexes . De plus, la plupart des solutions Big Data commerciales sont basées sur Hadoop.

Une pile de plate-forme Hadoop typique se compose de HDFS, Hive, HBase et Pig.
HDFS
Il signifie Hadoop Distributed Filesystem. Il peut être considéré comme le système de stockage de fichiers pour Hadoop. HDFS traite de la distribution et du stockage de grands ensembles de données.

CarteRéduire
MapReduce permet de traiter rapidement des ensembles de données massifs en parallèle. Il suit une idée simple - pour traiter beaucoup de données en très peu de temps, il suffit d'employer plus de travailleurs pour le travail. Une tâche MapReduce typique est traitée en deux phases : mapper et réduire. La phase "Map" envoie une requête à traiter à différents nœuds d'un cluster Hadoop, et la phase "Reduce" collecte tous les résultats à générer en une seule valeur. MapReduce prend en charge la planification des tâches, la surveillance des tâches et la réexécution de la tâche ayant échoué.
Ruche
Hive est un outil d'entreposage de données qui convertit le langage de requête en commandes MapReduce. Il a été initié par Facebook. La meilleure partie de l'utilisation de Hive est que les développeurs peuvent utiliser leurs connaissances SQL existantes puisque Hive utilise HQL (Hive Query Language) qui a une syntaxe similaire au SQL classique.
HBase
HBase est un SGBD orienté colonne qui traite les données non structurées en temps réel et s'exécute au-dessus de Hadoop. SQL ne peut pas être utilisé pour interroger sur HBase car il ne traite pas les données structurées. Pour cela, Java est le langage préféré. HBase est extrêmement efficace pour lire et écrire de grands ensembles de données en temps réel.
Porc
Pig est un langage de programmation procédurale de haut niveau initié par Yahoo! Et est devenu open source en 2007. Aussi étrange que cela puisse paraître, il s'appelle Pig car il peut gérer n'importe quel type de données que vous lui lancez !
Étincelle
Apache Spark mérite une mention spéciale sur cette liste car c'est le moteur le plus rapide pour le traitement du Big Data . Il est utilisé par des acteurs majeurs tels qu'Amazon, Yahoo!, eBay et Flipkart. Jetez un coup d'œil à toutes les organisations alimentées par Spark et vous serez époustouflé !
Spark a à bien des égards dépassé Hadoop car il vous permet d'exécuter des programmes jusqu'à cent fois plus rapidement en mémoire et dix fois plus rapidement sur disque. 
Il complète les intentions avec lesquelles Hadoop a été introduit. Lorsqu'il s'agit de grands ensembles de données, l'une des principales préoccupations est la vitesse de traitement, il était donc nécessaire de réduire le temps d'attente entre l'exécution de chaque requête. Et Spark fait exactement cela - grâce à ses modules intégrés pour le streaming, le traitement de graphes, l'apprentissage automatique et la prise en charge de SQL. Il prend également en charge les langages de programmation les plus courants - Java, Python et Scala.

Le motif principal derrière l'introduction de Spark était d'accélérer les processus de calcul de Hadoop. Cependant, il ne doit pas être considéré comme une extension de ce dernier. En fait, Spark n'utilise Hadoop qu'à deux fins principales : le stockage et le traitement. En dehors de cela, c'est un outil assez autonome.
NoSQL
Les bases de données traditionnelles (RDBMS) stockent les informations de manière structurée en définissant des lignes et des colonnes. C'est possible parce que les données stockées ne sont ni non structurées ni semi-structurées. Mais lorsque nous parlons de Big Data , nous parlons d'ensembles de données largement non structurés. Dans de tels ensembles de données, l'interrogation à l'aide de SQL ne fonctionnera pas, car le S (structure) n'existe pas ici. Donc, pour faire face à cela, nous avons des bases de données NoSQL.

Les bases de données NoSQL sont conçues pour se spécialiser dans le stockage de données non structurées et fournir des extractions de données rapides. Cependant, elles n'offrent pas le même niveau de cohérence que les bases de données traditionnelles - vous ne pouvez pas les en blâmer, blâmez les données !
Les bases de données NoSQL les plus populaires incluent MongoDB, Cassandra, Redis et Couchbase. Même Oracle et IBM - les principaux fournisseurs de RDBMS - proposent désormais des bases de données NoSQL, après avoir constaté la croissance rapide de son utilisation.
Lacs de données
Les lacs de données ont connu une augmentation continue de leur utilisation au cours des deux dernières années. Cependant, beaucoup de gens pensent encore que les Data Lakes ne sont que des entrepôts de données revisités - mais ce n'est pas vrai. La seule similitude entre les deux est qu'ils sont tous deux des référentiels de stockage de données. Franchement, c'est ça. 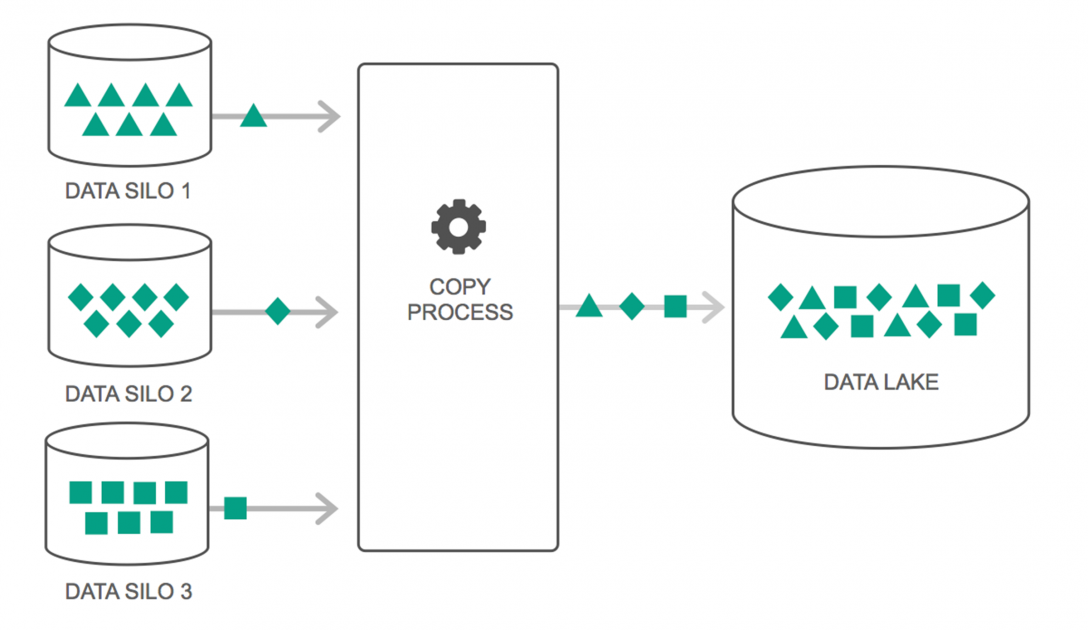
Un lac de données peut être défini comme un référentiel de stockage qui contient une énorme quantité de données brutes provenant de diverses sources, dans une variété de formats, jusqu'à ce qu'elles soient nécessaires. Vous devez savoir que les entrepôts de données stockent les données dans une structure de dossiers hiérarchique, mais ce n'est pas le cas avec les lacs de données. Les lacs de données utilisent une architecture plate pour enregistrer les jeux de données.
De nombreuses entreprises se tournent vers les Data Lakes pour simplifier le traitement d'accès à leurs Big Data . Les Data Lakes stockent les données collectées dans leur état naturel – contrairement à un entrepôt de données qui traite les données avant de les stocker. C'est pourquoi la métaphore du « lac » et de « l'entrepôt » est pertinente. Si vous voyez les données comme de l'eau, un lac de données peut être considéré comme un lac d'eau - stockant de l'eau non filtrée et sous sa forme naturelle, et un entrepôt de données peut être considéré comme de l'eau stockée dans des bouteilles et conservée sur une étagère.

Bases de données en mémoire
Dans tout système informatique, la RAM, ou Random Access Memory, est chargée d'accélérer le traitement. En utilisant une philosophie similaire, des bases de données en mémoire ont été développées afin que vous puissiez déplacer vos données vers votre système, au lieu d'amener votre système vers les données. Cela signifie essentiellement que si vous stockez des données en mémoire, cela réduira considérablement le temps de traitement. La récupération et la récupération des données ne seront plus une corvée car toutes les données seront en mémoire.
Mais pratiquement, si vous manipulez un ensemble de données très volumineux, il n'est pas possible de tout obtenir en mémoire. Cependant, vous pouvez en conserver une partie en mémoire, la traiter, puis mettre une autre partie en mémoire pour un traitement ultérieur. Pour vous aider, Hadoop fournit plusieurs outils qui contiennent à la fois des bases de données sur disque et en mémoire pour accélérer le traitement.
Emballer…
La liste fournie dans cet article n'est en aucun cas une "liste complète des outils et technologies Big Data". Au lieu de cela, il se concentre sur les outils et technologies Big Data "incontournables" . Le domaine du Big Data est en constante évolution et les nouvelles technologies obsolètes très rapidement les plus anciennes. Il existe de nombreuses autres technologies au-delà de la pile Hadoop-Spark, comme Finch, Kafka, Nifi, Samza, etc. Ces outils fournissent des résultats homogènes sans accrocs. Chacun d'entre eux a ses cas d'utilisation spécifiques, mais avant de commencer à travailler sur l'un d'entre eux, il est important de connaître ceux que nous avons mentionnés dans l'article.
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.
Apprenez des diplômes en génie logiciel en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.