Big Data: Werkzeuge und Technologien, die man kennen muss
Veröffentlicht: 2018-03-09Wir haben auch gesehen, wie jede Domäne oder Branche (Sie nennen es nur!) ihre Abläufe verbessern kann, indem sie Big Data sinnvoll nutzt . Organisationen sind sich dieser Tatsache bewusst und versuchen, die richtigen Mitarbeiter einzubinden, sie mit den richtigen Tools und Technologien auszustatten und ihre Big Data zu verstehen .
Da sich immer mehr Organisationen dieser Tatsache bewusst werden, wächst der Data-Science-Markt umso schneller. Jeder möchte ein Stück von diesem Kuchen – was zu einem massiven Wachstum von Big-Data- Tools und -Technologien geführt hat.
YouTube-Video ansehen.
In diesem Artikel sprechen wir über die richtigen Tools und Technologien, die Sie in Ihrem Toolkit haben sollten, wenn Sie auf den Big-Data-Zug aufspringen. Die Vertrautheit mit diesen Tools wird Ihnen auch bei bevorstehenden Vorstellungsgesprächen helfen.
Inhaltsverzeichnis
Hadoop-Ökosystem
Sie können unmöglich über Big Data sprechen, ohne den Elefanten im Raum zu erwähnen (Wortspiel beabsichtigt!) – Hadoop. Ein Akronym für „High-Availability Distributed Object-Oriented Platform“, Hadoop ist im Wesentlichen ein Framework, das zur Wartung, Selbstheilung, Fehlerbehandlung und Sicherung großer Datenmengen verwendet wird. Im Laufe der Jahre hat Hadoop jedoch ein ganzes Ökosystem verwandter Tools umfasst . Darüber hinaus basieren die meisten kommerziellen Big-Data- Lösungen auf Hadoop.

Ein typischer Hadoop-Plattform-Stack besteht aus HDFS, Hive, HBase und Pig.
HDFS
Es steht für Hadoop Distributed Filesystem. Es kann als Dateispeichersystem für Hadoop betrachtet werden. HDFS befasst sich mit der Verteilung und Speicherung großer Datensätze.

Karte verkleinern
MapReduce ermöglicht die schnelle parallele Verarbeitung massiver Datensätze. Es folgt einer einfachen Idee – um viele Daten in sehr kurzer Zeit zu bewältigen, stellen Sie einfach mehr Mitarbeiter für den Job ein. Ein typischer MapReduce-Job wird in zwei Phasen verarbeitet: Map und Reduce. Die „Map“-Phase sendet eine Abfrage zur Verarbeitung an verschiedene Knoten in einem Hadoop-Cluster, und die „Reduce“-Phase sammelt alle Ergebnisse, um sie in einem einzigen Wert auszugeben. MapReduce kümmert sich um die Planung von Jobs, die Überwachung von Jobs und die erneute Ausführung der fehlgeschlagenen Aufgabe.
Bienenstock
Hive ist ein Data-Warehousing-Tool, das die Abfragesprache in MapReduce-Befehle umwandelt. Es wurde von Facebook initiiert. Das Beste an der Verwendung von Hive ist, dass Entwickler ihr vorhandenes SQL-Wissen nutzen können, da Hive HQL (Hive Query Language) verwendet, das eine ähnliche Syntax wie klassisches SQL hat.
HBase
HBase ist ein spaltenorientiertes DBMS, das mit unstrukturierten Daten in Echtzeit umgeht und auf Hadoop aufsetzt. SQL kann nicht für Abfragen auf HBase verwendet werden, da es nicht mit strukturierten Daten umgeht. Dafür ist Java die bevorzugte Sprache. HBase ist äußerst effizient beim Lesen und Schreiben großer Datensätze in Echtzeit.
Schwein
Pig ist eine höhere prozedurale Programmiersprache, die von Yahoo! Und wurde 2007 Open Source. So seltsam es auch klingen mag, es heißt Pig, weil es mit jeder Art von Daten umgehen kann, die Sie darauf werfen!
Funke
Apache Spark verdient eine besondere Erwähnung auf dieser Liste, da es die schnellste Engine für die Verarbeitung von Big Data ist. Es wird von großen Akteuren wie Amazon, Yahoo!, eBay und Flipkart eingesetzt. Werfen Sie einen Blick auf alle Organisationen , die von Spark unterstützt werden, und Sie werden begeistert sein!
Spark hat Hadoop in vielerlei Hinsicht überholt, da Sie Programme bis zu hundertmal schneller im Arbeitsspeicher und zehnmal schneller auf der Festplatte ausführen können. 
Es ergänzt die Absichten, mit denen Hadoop eingeführt wurde. Beim Umgang mit großen Datensätzen ist die Verarbeitungsgeschwindigkeit eines der Hauptanliegen, daher bestand die Notwendigkeit, die Wartezeit zwischen der Ausführung jeder Abfrage zu verkürzen. Und Spark tut genau das – dank seiner integrierten Module für Streaming, Graphverarbeitung, maschinelles Lernen und SQL-Unterstützung. Es unterstützt auch die gängigsten Programmiersprachen – Java, Python und Scala.

Das Hauptmotiv hinter der Einführung von Spark war die Beschleunigung der Rechenprozesse von Hadoop. Es sollte jedoch nicht als Erweiterung des letzteren angesehen werden. Tatsächlich verwendet Spark Hadoop nur für zwei Hauptzwecke – Speicherung und Verarbeitung. Abgesehen davon ist es ein ziemlich eigenständiges Tool.
NoSQL
Herkömmliche Datenbanken (RDBMS) speichern Informationen strukturiert, indem sie Zeilen und Spalten definieren. Dort ist dies möglich, da die gespeicherten Daten nicht unstrukturiert oder halbstrukturiert sind. Aber wenn wir über den Umgang mit Big Data sprechen, sprechen wir von weitgehend unstrukturierten Datensätzen. In solchen Datensätzen funktioniert die Abfrage mit SQL nicht, weil das S (Struktur) hier nicht existiert. Um damit fertig zu werden, haben wir NoSQL-Datenbanken.

NoSQL-Datenbanken sind darauf ausgelegt, sich auf die Speicherung unstrukturierter Daten zu spezialisieren und einen schnellen Datenabruf zu ermöglichen. Sie bieten jedoch nicht das gleiche Maß an Konsistenz wie herkömmliche Datenbanken – das können Sie ihnen nicht vorwerfen, geben Sie den Daten die Schuld!
Zu den beliebtesten NoSQL-Datenbanken gehören MongoDB, Cassandra, Redis und Couchbase. Sogar Oracle und IBM – die führenden RDBMS-Anbieter – bieten jetzt NoSQL-Datenbanken an, nachdem sie das schnelle Wachstum ihrer Nutzung gesehen haben.
Datenseen
Die Nutzung von Data Lakes hat in den letzten Jahren kontinuierlich zugenommen. Viele Leute denken jedoch immer noch, dass Data Lakes nur eine Neuinterpretation von Data Warehouse sind – aber das stimmt nicht. Die einzige Ähnlichkeit zwischen den beiden besteht darin, dass es sich bei beiden um Datenspeicherungs-Repositories handelt. Ehrlich gesagt, das ist es. 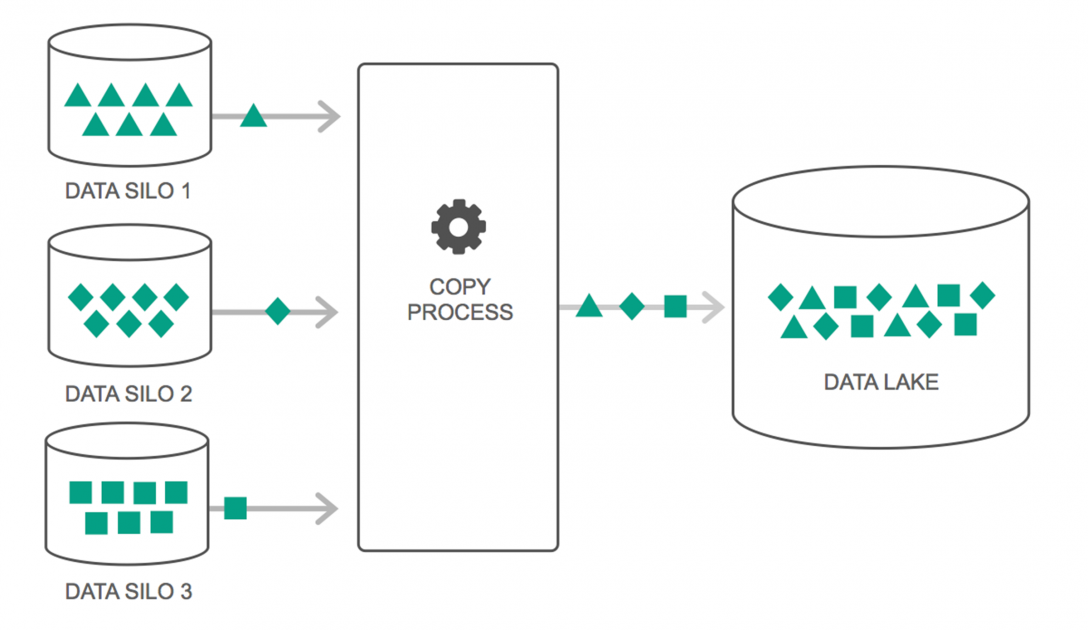
Ein Data Lake kann als Speicherort definiert werden, der eine riesige Menge an Rohdaten aus einer Vielzahl von Quellen in einer Vielzahl von Formaten enthält, bis sie benötigt werden. Sie müssen sich bewusst sein, dass Data Warehouses die Daten in einer hierarchischen Ordnerstruktur speichern, aber das ist bei Data Lakes nicht der Fall. Data Lakes verwenden eine flache Architektur, um die Datensätze zu speichern.
Viele Unternehmen wechseln zu Data Lakes, um die Verarbeitung des Zugriffs auf ihre Big Data zu vereinfachen . Die Data Lakes speichern die gesammelten Daten in ihrem natürlichen Zustand – im Gegensatz zu einem Data Warehouse, das die Daten vor dem Speichern verarbeitet. Deshalb ist die Metapher „See“ und „Lagerhaus“ treffend. Wenn Sie Daten als Wasser betrachten, können Sie sich einen Datensee wie einen Wassersee vorstellen – Wasser wird ungefiltert und in seiner natürlichen Form gespeichert, und ein Data Warehouse kann als Wasser betrachtet werden, das in Flaschen gespeichert und im Regal aufbewahrt wird.

In-Memory-Datenbanken
In jedem Computersystem ist der RAM oder Random Access Memory für die Beschleunigung der Verarbeitung verantwortlich. Mit einer ähnlichen Philosophie wurden In-Memory-Datenbanken entwickelt, damit Sie Ihre Daten auf Ihr System verschieben können, anstatt Ihr System zu den Daten zu bringen. Das bedeutet im Wesentlichen, dass die Speicherung von Daten im Arbeitsspeicher die Verarbeitungszeit erheblich verkürzt. Das Abrufen und Abrufen von Daten ist kein Problem mehr, da sich alle Daten im Speicher befinden.
Wenn Sie jedoch mit einem wirklich großen Datensatz arbeiten, ist es praktisch nicht möglich, alles in den Arbeitsspeicher zu bekommen. Sie können jedoch einen Teil davon im Speicher behalten, ihn verarbeiten und dann einen anderen Teil zur weiteren Verarbeitung in den Speicher bringen. Um dabei zu helfen, bietet Hadoop mehrere Tools , die sowohl On-Disk- als auch In-Memory-Datenbanken enthalten, um die Verarbeitung zu beschleunigen.
Abschluss…
Die in diesem Artikel bereitgestellte Liste ist keineswegs eine „umfassende Liste von Big-Data-Tools und -Technologien“. Stattdessen konzentriert es sich auf die „must-know“ Big-Data-Tools und -Technologien. Der Bereich Big Data entwickelt sich ständig weiter und neue Technologien überholen die älteren sehr schnell. Neben dem Hadoop-Spark-Stack gibt es viele weitere Technologien wie Finch, Kafka, Nifi, Samza und mehr. Diese Tools liefern nahtlose Ergebnisse ohne Schluckauf. Jeder von ihnen hat seine spezifischen Anwendungsfälle, aber bevor Sie an einem von ihnen arbeiten, ist es wichtig, sich derjenigen bewusst zu sein, die wir im Artikel erwähnt haben.
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.
Lernen Sie Software-Engineering-Abschlüsse online von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.