Big Data: strumenti e tecnologie da conoscere
Pubblicato: 2018-03-09Abbiamo anche visto come qualsiasi dominio o settore (basta nominarlo!) potrebbe migliorare le proprie operazioni facendo buon uso dei Big Data . Le organizzazioni si stanno rendendo conto di questo fatto e stanno cercando di integrare il giusto gruppo di persone, di equipaggiarle con il corretto insieme di strumenti e tecnologie e dare un senso ai loro Big Data .
Man mano che sempre più organizzazioni si rendono conto di questo fatto, il mercato della scienza dei dati sta crescendo sempre più rapidamente. Tutti vogliono un pezzo di questa torta, che ha portato a un'enorme crescita di strumenti e tecnologie per big data.
Guarda il video di YouTube.
In questo articolo parleremo degli strumenti e delle tecnologie giusti che dovresti avere nel tuo kit di strumenti mentre salti sul carro dei big data. La familiarità con questi strumenti ti aiuterà anche a qualsiasi colloquio imminente che potresti dover affrontare.
Sommario
Ecosistema Hadoop
Non puoi assolutamente parlare di Big Data senza menzionare l'elefante nella stanza (gioco di parole!) – Hadoop. Acronimo di "Piattaforma orientata agli oggetti distribuita ad alta disponibilità", Hadoop è essenzialmente un framework utilizzato per il mantenimento, l'auto-guarigione, la gestione degli errori e la protezione di grandi set di dati. Tuttavia, nel corso degli anni, Hadoop ha abbracciato un intero ecosistema di strumenti correlati . Non solo, la maggior parte delle soluzioni commerciali per Big Data si basano su Hadoop.

Un tipico stack di piattaforma Hadoop è costituito da HDFS, Hive, HBase e Pig.
HDFS
Sta per Hadoop Distributed Filesystem. Può essere considerato il sistema di archiviazione file per Hadoop. HDFS si occupa della distribuzione e dell'archiviazione di grandi set di dati.

Riduci mappa
MapReduce consente di elaborare rapidamente insiemi di dati di grandi dimensioni in parallelo. Ne consegue un'idea semplice: per gestire molti dati in pochissimo tempo, è sufficiente impiegare più lavoratori per il lavoro. Un tipico lavoro MapReduce viene elaborato in due fasi: Mappa e Riduci. La fase "Mappa" invia una query per l'elaborazione a vari nodi in un cluster Hadoop e la fase "Riduci" raccoglie tutti i risultati per l'output in un unico valore. MapReduce si occupa della pianificazione dei lavori, del monitoraggio dei lavori e della riesecuzione dell'attività non riuscita.
Alveare
Hive è uno strumento di data warehousing che converte il linguaggio di query in comandi MapReduce. È stato avviato da Facebook. La parte migliore dell'utilizzo di Hive è che gli sviluppatori possono utilizzare la loro conoscenza SQL esistente poiché Hive utilizza HQL (Hive Query Language) che ha una sintassi simile all'SQL classico.
Base H
HBase è un DBMS orientato alle colonne che gestisce dati non strutturati in tempo reale e viene eseguito su Hadoop. SQL non può essere utilizzato per eseguire query su HBase poiché non gestisce dati strutturati. Per questo, Java è la lingua preferita. HBase è estremamente efficiente nella lettura e nella scrittura di grandi set di dati in tempo reale.
Maiale
Pig è un linguaggio di programmazione procedurale di alto livello avviato da Yahoo! Ed è diventato open source nel 2007. Per quanto strano possa sembrare, si chiama Pig perché può gestire qualsiasi tipo di dato che gli viene lanciato!
Scintilla
Apache Spark merita una menzione speciale in questo elenco in quanto è il motore più veloce per l' elaborazione di Big Data . Viene utilizzato dai principali attori tra cui Amazon, Yahoo!, eBay e Flipkart. Dai un'occhiata a tutte le organizzazioni che sono alimentate da Spark e rimarrai sbalordito!
Spark ha superato Hadoop per molti versi in quanto ti consente di eseguire programmi fino a cento volte più veloci in memoria e dieci volte più veloci su disco. 
Completa le intenzioni con cui è stato introdotto Hadoop . Quando si ha a che fare con set di dati di grandi dimensioni, una delle principali preoccupazioni è la velocità di elaborazione, quindi era necessario ridurre il tempo di attesa tra l'esecuzione di ciascuna query. E Spark fa esattamente questo, grazie ai suoi moduli integrati per lo streaming, l'elaborazione dei grafici, l'apprendimento automatico e il supporto SQL. Supporta anche i linguaggi di programmazione più comuni: Java, Python e Scala.

Il motivo principale dietro l'introduzione di Spark è stato quello di accelerare i processi computazionali di Hadoop. Tuttavia, non dovrebbe essere visto come un'estensione di quest'ultimo. In effetti, Spark utilizza Hadoop solo per due scopi principali: archiviazione ed elaborazione. A parte questo, è uno strumento piuttosto autonomo.
NoSQL
I database tradizionali (RDBMS) memorizzano le informazioni in modo strutturato definendo righe e colonne. È possibile lì perché i dati archiviati non sono non strutturati o semi-strutturati. Ma quando si parla di gestione dei Big Data , si parla di set di dati in gran parte non strutturati. In tali set di dati, l'esecuzione di query tramite SQL non funzionerà, poiché la S (struttura) non esiste qui. Quindi, per affrontarlo, abbiamo database NoSQL.

I database NoSQL sono creati per specializzarsi nell'archiviazione di dati non strutturati e fornire un rapido recupero dei dati. Tuttavia, non forniscono lo stesso livello di coerenza dei database tradizionali: non puoi biasimarli per questo, dai la colpa ai dati!
I database NoSQL più popolari includono MongoDB, Cassandra, Redis e Couchbase. Anche Oracle e IBM, i principali fornitori di RDBMS, ora offrono database NoSQL, dopo aver visto la rapida crescita del loro utilizzo.
Laghi di dati
I data lake hanno visto un continuo aumento del loro utilizzo negli ultimi due anni. Tuttavia, molte persone pensano ancora che i Data Lakes siano solo Data Warehouse rivisitati, ma non è vero. L'unica somiglianza tra i due è che sono entrambi repository di archiviazione dati. Francamente, questo è tutto. 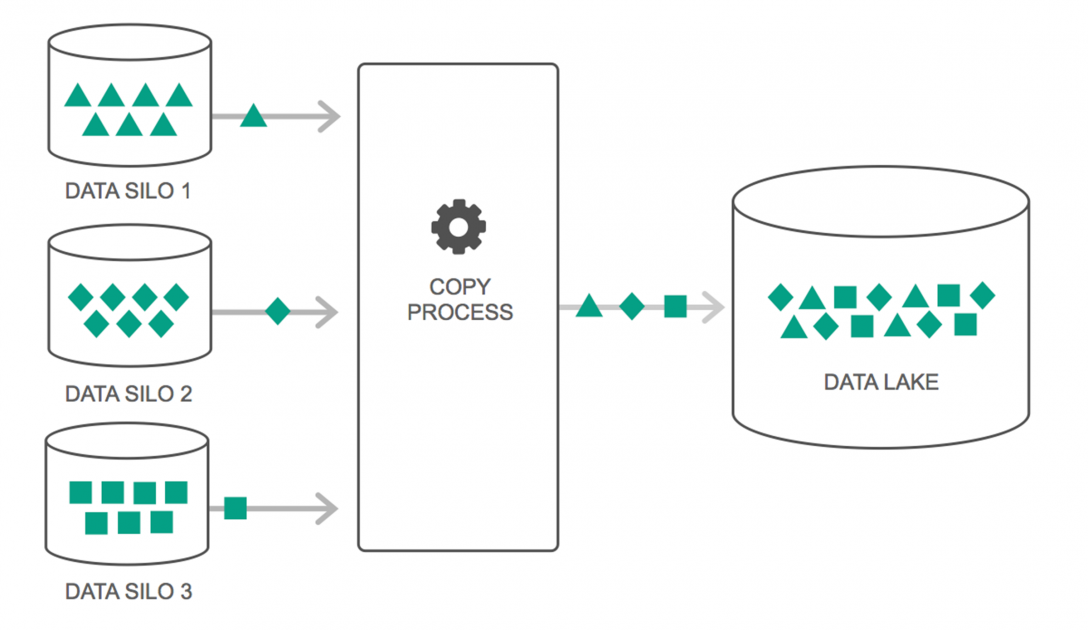
Un Data Lake può essere definito come un repository di archiviazione che contiene un'enorme quantità di dati grezzi da una varietà di origini, in una varietà di formati, fino a quando non è necessario. È necessario essere consapevoli del fatto che i data warehouse archiviano i dati in una struttura di cartelle gerarchica, ma non è il caso di Data Lakes. Data Lakes utilizza un'architettura piatta per salvare i set di dati.
Molte aziende stanno passando a Data Lakes per semplificare l'elaborazione dell'accesso ai propri Big Data . I Data Lake archiviano i dati raccolti nel loro stato naturale, a differenza di un data warehouse che elabora i dati prima di archiviarli. Ecco perché la metafora “lago” e “magazzino” è azzeccata. Se vedi i dati come acqua, un data lake può essere pensato come un water lake, che immagazzina acqua non filtrata e nella sua forma naturale, e un data warehouse può essere pensato come acqua immagazzinata in bottiglie e conservata sullo scaffale.

Database in memoria
In qualsiasi sistema informatico, la RAM, o memoria ad accesso casuale, è responsabile dell'accelerazione dell'elaborazione. Utilizzando una filosofia simile, i database in memoria sono stati sviluppati in modo da poter spostare i dati sul sistema, invece di trasferire il sistema ai dati. Ciò significa essenzialmente che se si archiviano i dati in memoria, il tempo di elaborazione sarà ridotto di un certo margine. Il recupero e il recupero dei dati non saranno più un problema poiché tutti i dati saranno in memoria.
Ma in pratica, se stai gestendo un set di dati davvero grande, non è possibile tenerlo tutto in memoria. Tuttavia, puoi conservarne una parte in memoria, elaborarla e quindi portarne un'altra parte in memoria per un'ulteriore elaborazione. Per aiutare in questo, Hadoop fornisce diversi strumenti che contengono database sia su disco che in memoria per accelerare l'elaborazione.
Avvolgendo…
L'elenco fornito in questo articolo non è affatto un "elenco completo di strumenti e tecnologie per Big Data ". Invece, si concentra sugli strumenti e sulle tecnologie Big Data "da sapere" . Il campo dei Big Data è in continua evoluzione e le nuove tecnologie stanno superando molto rapidamente quelle più vecchie. Ci sono molte altre tecnologie oltre allo stack Hadoop-Spark, come Finch, Kafka, Nifi, Samza e altre ancora. Questi strumenti forniscono risultati senza interruzioni senza singhiozzi. Ognuno di questi ha i suoi casi d'uso specifici, ma prima di iniziare a lavorare su uno di essi, è importante essere a conoscenza di quelli menzionati nell'articolo.
Se sei interessato a saperne di più sui Big Data, dai un'occhiata al nostro PG Diploma in Software Development Specialization nel programma Big Data, progettato per professionisti che lavorano e fornisce oltre 7 casi di studio e progetti, copre 14 linguaggi e strumenti di programmazione, pratiche pratiche workshop, oltre 400 ore di apprendimento rigoroso e assistenza all'inserimento lavorativo con le migliori aziende.
Impara le lauree in ingegneria del software online dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.