Большие данные: инструменты и технологии, которые необходимо знать
Опубликовано: 2018-03-09Мы также увидели, как любая область или отрасль (просто назовите!) могут улучшить свою деятельность, эффективно используя большие данные . Организации осознают этот факт и пытаются нанять правильную группу людей, снабдить их правильным набором инструментов и технологий и разобраться в своих больших данных .
По мере того, как все больше и больше организаций осознают этот факт, рынок Data Science растет все быстрее. Каждый хочет получить кусок этого пирога, что привело к огромному росту инструментов и технологий для работы с большими данными.
Посмотрите видео на ютубе.
В этой статье мы поговорим о правильных инструментах и технологиях, которые должны быть в вашем наборе инструментов, когда вы прыгаете на подножку больших данных. Знакомство с этими инструментами также поможет вам на предстоящих собеседованиях.
Оглавление
Экосистема Hadoop
Вы не можете говорить о больших данных , не упомянув слона в комнате (каламбур!) — Hadoop. Аббревиатура от «Распределенная объектно-ориентированная платформа с высокой доступностью». Hadoop — это, по сути, инфраструктура, используемая для обслуживания, самовосстановления, обработки ошибок и защиты больших наборов данных. Однако за прошедшие годы Hadoop охватил целую экосистему связанных инструментов . Мало того, большинство коммерческих решений для работы с большими данными основаны на Hadoop.

Типичный стек платформы Hadoop состоит из HDFS, Hive, HBase и Pig.
HDFS
Это расшифровывается как распределенная файловая система Hadoop. Его можно рассматривать как систему хранения файлов для Hadoop. HDFS занимается распространением и хранением больших наборов данных.

Уменьшение карты
MapReduce позволяет быстро обрабатывать массивные наборы данных параллельно. Это следует простой идее — чтобы обрабатывать большое количество данных за очень короткое время, просто наймите больше работников для этой работы. Типичное задание MapReduce выполняется в два этапа: Map и Reduce. На этапе «Сопоставление» запрос для обработки отправляется на различные узлы в кластере Hadoop, а на этапе «Сокращение» все результаты собираются для вывода в одно значение. MapReduce позаботится о планировании заданий, мониторинге заданий и повторном выполнении невыполненной задачи.
Улей
Hive — это инструмент для хранения данных, который преобразует язык запросов в команды MapReduce. Его инициатором выступил Facebook. Лучшая часть использования Hive заключается в том, что разработчики могут использовать свои существующие знания SQL, поскольку Hive использует HQL (язык запросов Hive), синтаксис которого аналогичен классическому SQL.
HBase
HBase — это СУБД, ориентированная на столбцы, которая работает с неструктурированными данными в режиме реального времени и работает поверх Hadoop. SQL нельзя использовать для запросов к HBase, поскольку он не работает со структурированными данными. Для этого Java является предпочтительным языком. HBase чрезвычайно эффективно читает и записывает большие наборы данных в режиме реального времени.
свинья
Pig — это язык процедурного программирования высокого уровня, разработанный Yahoo! И стал открытым исходным кодом в 2007 году. Как бы странно это ни звучало, он называется Pig, потому что он может обрабатывать любые типы данных, которые вы ему подбрасываете!
Искра
Apache Spark заслуживает особого упоминания в этом списке, так как это самый быстрый движок для обработки больших данных . Его используют крупные игроки, включая Amazon, Yahoo!, eBay и Flipkart. Взгляните на все организации , использующие Spark, и вы будете поражены!
Spark во многом устарел от Hadoop, поскольку позволяет запускать программы в памяти в сто раз быстрее, а на диске — в десять раз быстрее. 
Он дополняет намерения, с которыми был представлен Hadoop . При работе с большими наборами данных одной из основных проблем является скорость обработки, поэтому возникла необходимость уменьшить время ожидания между выполнением каждого запроса. И Spark делает именно это — благодаря встроенным модулям для потоковой передачи, обработки графов, машинного обучения и поддержки SQL. Он также поддерживает наиболее распространенные языки программирования — Java, Python и Scala.

Основным мотивом внедрения Spark было ускорение вычислительных процессов Hadoop. Однако его не следует рассматривать как расширение последнего. На самом деле Spark использует Hadoop только для двух основных целей — хранения и обработки. Кроме того, это довольно автономный инструмент.
NoSQL
Традиционные базы данных (RDBMS) хранят информацию структурированным образом, определяя строки и столбцы. Там это возможно, поскольку хранимые данные не являются неструктурированными или полуструктурированными. Но когда мы говорим о работе с большими данными , мы имеем в виду в основном неструктурированные наборы данных. В таких наборах данных запросы с использованием SQL не будут работать, потому что S (структура) здесь не существует. Итак, чтобы справиться с этим, у нас есть базы данных NoSQL.

Базы данных NoSQL предназначены для хранения неструктурированных данных и обеспечения быстрого извлечения данных. Однако они не обеспечивают такой же уровень согласованности, как традиционные базы данных — вы не можете винить их за это, вините данные!
Самые популярные базы данных NoSQL включают MongoDB, Cassandra, Redis и Couchbase. Даже Oracle и IBM — ведущие поставщики СУБД — теперь предлагают базы данных NoSQL, увидев быстрый рост их использования.
Озера данных
За последние пару лет наблюдается непрерывный рост использования озер данных. Тем не менее, многие люди по-прежнему думают, что озера данных — это просто новое хранилище данных, но это не так. Единственное сходство между ними заключается в том, что они оба являются репозиториями для хранения данных. Честно говоря, это все. 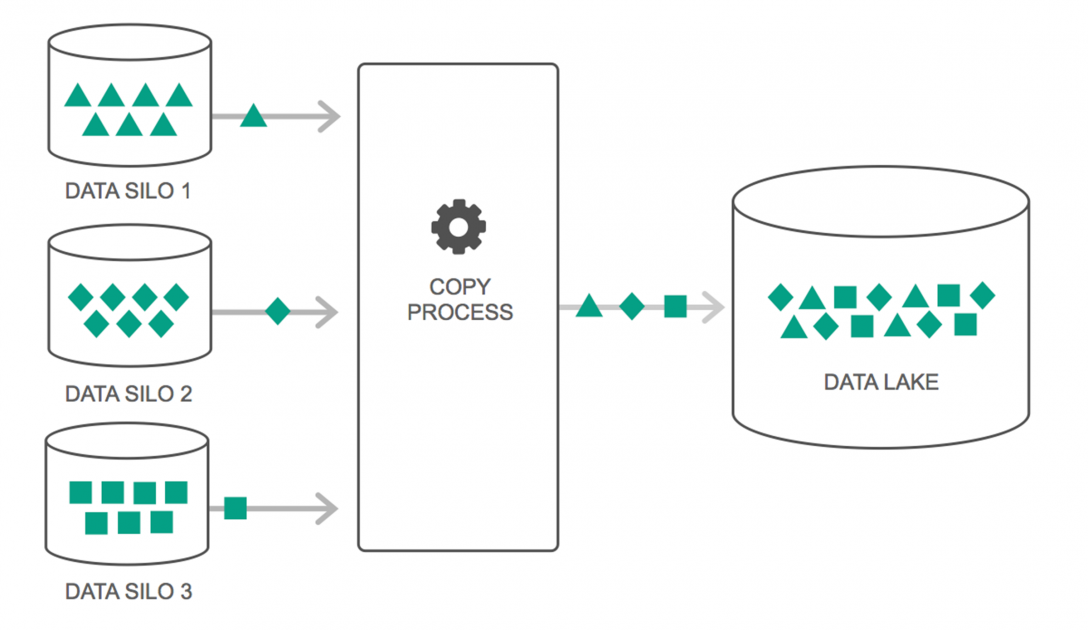
Озеро данных можно определить как репозиторий, в котором хранится огромное количество необработанных данных из различных источников в различных форматах до тех пор, пока они не потребуются. Вы должны знать, что хранилища данных хранят данные в иерархической структуре папок, но это не относится к озерам данных. Озера данных используют плоскую архитектуру для сохранения наборов данных.
Многие предприятия переходят на озера данных, чтобы упростить обработку доступа к своим большим данным . Озера данных хранят собранные данные в их естественном состоянии, в отличие от хранилища данных, которое обрабатывает данные перед сохранением. Вот почему метафора «озеро» и «склад» уместна. Если рассматривать данные как воду, то озеро данных можно представить себе как водное озеро, хранящее нефильтрованную воду в ее естественной форме, а хранилище данных можно представить как воду, хранящуюся в бутылках и хранящуюся на полке.

Базы данных в памяти
В любой компьютерной системе за ускорение обработки отвечает оперативная память или оперативная память. Используя аналогичную философию, базы данных в памяти были разработаны, чтобы вы могли перемещать свои данные в свою систему, вместо того, чтобы переносить вашу систему к данным. По сути, это означает, что если вы храните данные в памяти, это значительно сократит время обработки. Извлечение и извлечение данных больше не будет проблемой, поскольку все данные будут храниться в памяти.
Но на практике, если вы работаете с действительно большим набором данных, невозможно получить все это в памяти. Однако вы можете сохранить часть этого в памяти, обработать ее, а затем перенести в память другую часть для дальнейшей обработки. Чтобы помочь в этом, Hadoop предоставляет несколько инструментов , которые содержат базы данных как на диске, так и в памяти, чтобы ускорить обработку.
Завершение…
Список, представленный в этой статье, ни в коем случае не является «полным списком инструментов и технологий больших данных ». Вместо этого он фокусируется на «обязательных» инструментах и технологиях больших данных . Сфера больших данных постоянно развивается, и новые технологии очень быстро устаревают от старых. Помимо стека Hadoop-Spark существует множество других технологий, таких как Finch, Kafka, Nifi, Samza и другие. Эти инструменты обеспечивают плавные результаты без сбоев. У каждого из них есть свои конкретные варианты использования, но прежде чем вы начнете работать над любым из них, важно знать о тех, которые мы упомянули в статье.
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma в области разработки программного обеспечения со специализацией в области больших данных, которая предназначена для работающих профессионалов и включает более 7 тематических исследований и проектов, охватывает 14 языков и инструментов программирования, практические занятия. семинары, более 400 часов интенсивного обучения и помощь в трудоустройстве в ведущих фирмах.
Изучайте степени по программной инженерии онлайн в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.