Big Data: ferramentas e tecnologias obrigatórias
Publicados: 2018-03-09Também vimos como qualquer domínio ou setor (é só nomear!) poderia melhorar suas operações colocando o Big Data em bom uso . As organizações estão percebendo esse fato e estão tentando integrar o conjunto certo de pessoas, blindá-las com o conjunto correto de ferramentas e tecnologias e entender seu Big Data .
À medida que mais e mais organizações despertam para esse fato, o mercado de Data Science cresce cada vez mais rapidamente. Todo mundo quer um pedaço desse bolo – o que resultou em um crescimento maciço em ferramentas e tecnologias de big data.
Assista ao vídeo do youtube.
Neste artigo, falaremos sobre as ferramentas e tecnologias certas que você deve ter em seu kit de ferramentas ao entrar na onda do big data. A familiaridade com essas ferramentas também o ajudará nas próximas entrevistas que você enfrentar.
Índice
Ecossistema Hadoop
Você não pode falar sobre Big Data sem mencionar o elefante na sala (trocadilho intencional!) – Hadoop. Um acrônimo para 'plataforma orientada a objetos distribuídos de alta disponibilidade', o Hadoop é essencialmente uma estrutura usada para manutenção, autocorreção, tratamento de erros e proteção de grandes conjuntos de dados. No entanto, ao longo dos anos, o Hadoop abrangeu todo um ecossistema de ferramentas relacionadas . Além disso, a maioria das soluções comerciais de Big Data são baseadas no Hadoop.

Uma pilha de plataforma Hadoop típica consiste em HDFS, Hive, HBase e Pig.
HDFS
Significa Hadoop Distributed Filesystem. Pode ser considerado o sistema de armazenamento de arquivos do Hadoop. O HDFS lida com distribuição e armazenamento de grandes conjuntos de dados.

MapReduce
O MapReduce permite que grandes conjuntos de dados sejam processados rapidamente em paralelo. Segue uma ideia simples – para lidar com muitos dados em muito pouco tempo, basta empregar mais trabalhadores para o trabalho. Um trabalho MapReduce típico é processado em duas fases: Mapear e Reduzir. A fase “Map” envia uma consulta para processamento para vários nós em um cluster Hadoop, e a fase “Reduce” coleta todos os resultados para gerar um único valor. O MapReduce cuida do agendamento de trabalhos, monitoramento de trabalhos e reexecução da tarefa com falha.
Colmeia
Hive é uma ferramenta de armazenamento de dados que converte a linguagem de consulta em comandos MapReduce. Foi iniciado pelo Facebook. A melhor parte de usar o Hive é que os desenvolvedores podem usar seu conhecimento SQL existente, pois o Hive usa HQL (Hive Query Language), que possui uma sintaxe semelhante ao SQL clássico.
HBase
O HBase é um DBMS orientado a colunas que lida com dados não estruturados em tempo real e é executado em cima do Hadoop. O SQL não pode ser usado para consultar no HBase, pois não lida com dados estruturados. Para isso, Java é a linguagem preferida. O HBase é extremamente eficiente na leitura e gravação de grandes conjuntos de dados em tempo real.
Porco
Pig é uma linguagem de programação procedural de alto nível que foi iniciada pelo Yahoo! E tornou-se open source em 2007. Por mais estranho que possa parecer, chama-se Pig porque pode lidar com qualquer tipo de dados que você jogue nele!
Fagulha
O Apache Spark merece uma menção especial nesta lista, pois é o mecanismo mais rápido para processamento de Big Data . É usado por grandes players, incluindo Amazon, Yahoo!, eBay e Flipkart. Dê uma olhada em todas as organizações que são alimentadas pelo Spark e você ficará impressionado!
O Spark desatualizou o Hadoop de várias maneiras, pois permite executar programas até cem vezes mais rápido na memória e dez vezes mais rápido no disco. 
Ele complementa as intenções com as quais o Hadoop foi introduzido. Ao lidar com grandes conjuntos de dados, uma das maiores preocupações é a velocidade de processamento, por isso, houve a necessidade de diminuir o tempo de espera entre a execução de cada consulta. E o Spark faz exatamente isso – graças aos seus módulos integrados para streaming, processamento de gráficos, aprendizado de máquina e suporte a SQL. Ele também suporta as linguagens de programação mais comuns – Java, Python e Scala.

O principal motivo por trás da introdução do Spark foi acelerar os processos computacionais do Hadoop. No entanto, não deve ser visto como uma extensão deste último. Na verdade, o Spark usa o Hadoop apenas para duas finalidades principais: armazenamento e processamento. Fora isso, é uma ferramenta bastante autônoma.
NoSQL
Os bancos de dados tradicionais (RDBMS) armazenam informações de forma estruturada, definindo linhas e colunas. Isso é possível porque os dados armazenados não são desestruturados ou semiestruturados. Mas quando falamos sobre lidar com Big Data , estamos falando de conjuntos de dados amplamente não estruturados. Nesses conjuntos de dados, a consulta usando SQL não funcionará, porque o S (estrutura) não existe aqui. Então, para lidar com isso, temos bancos de dados NoSQL.

Os bancos de dados NoSQL são criados para se especializar no armazenamento de dados não estruturados e fornecer recuperações rápidas de dados. No entanto, eles não fornecem o mesmo nível de consistência que os bancos de dados tradicionais – você não pode culpá-los por isso, culpe os dados!
Os bancos de dados NoSQL mais populares incluem MongoDB, Cassandra, Redis e Couchbase. Mesmo Oracle e IBM – os principais fornecedores de RDBMS – agora oferecem bancos de dados NoSQL, depois de ver o rápido crescimento em seu uso.
Lagos de dados
Os data lakes tiveram um aumento contínuo em seu uso nos últimos dois anos. No entanto, muitas pessoas ainda pensam que Data Lakes são apenas Data Warehouse revisitados – mas isso não é verdade. A única semelhança entre os dois é que ambos são repositórios de armazenamento de dados. Francamente, é isso. 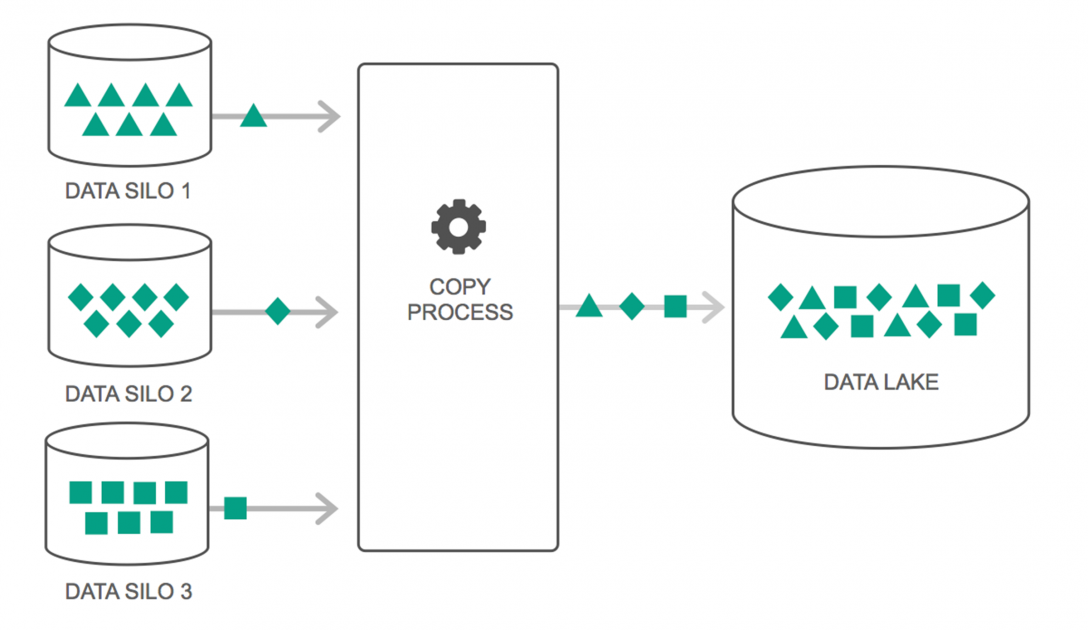
Um Data Lake pode ser definido como um repositório de armazenamento que contém uma enorme quantidade de dados brutos de várias fontes, em vários formatos, até que seja necessário. Você deve estar ciente de que os data warehouses armazenam os dados em uma estrutura hierárquica de pastas, mas esse não é o caso dos Data Lakes. Os Data Lakes usam uma arquitetura simples para salvar os conjuntos de dados.
Muitas empresas estão mudando para Data Lakes para simplificar o processamento de acesso ao Big Data . Os Data Lakes armazenam os dados coletados em seu estado natural – ao contrário de um data warehouse que processa os dados antes de armazená-los. É por isso que a metáfora do “lago” e do “armazém” é adequada. Se você vê os dados como água, um data lake pode ser pensado como um lago de água – armazenando água não filtrada e em sua forma natural, e um data warehouse pode ser pensado como água armazenada em garrafas e mantida na prateleira.

Bancos de dados na memória
Em qualquer sistema de computador, a RAM, ou Random Access Memory, é responsável por agilizar o processamento. Usando uma filosofia semelhante, os bancos de dados na memória foram desenvolvidos para que você possa mover seus dados para seu sistema, em vez de levar seu sistema para os dados. O que isso significa essencialmente é que, se você armazenar dados na memória, reduzirá bastante o tempo de processamento. A busca e recuperação de dados não será mais uma dor, pois todos os dados estarão na memória.
Mas, na prática, se você estiver lidando com um conjunto de dados muito grande, não será possível obter tudo na memória. No entanto, você pode manter uma parte dela na memória, processá-la e, em seguida, trazer outra parte na memória para processamento adicional. Para ajudar com isso, o Hadoop fornece várias ferramentas que contêm bancos de dados em disco e na memória para acelerar o processamento.
Empacotando…
A lista fornecida neste artigo não é de forma alguma uma “lista abrangente de ferramentas e tecnologias de Big Data”. Em vez disso, concentra-se nas ferramentas e tecnologias de Big Data “obrigatórias” . O campo do Big Data está em constante evolução e as novas tecnologias estão ultrapassando as mais antigas muito rapidamente. Existem muitas outras tecnologias além da pilha Hadoop-Spark, como Finch, Kafka, Nifi, Samza e muito mais. Essas ferramentas fornecem resultados perfeitos sem soluços. Cada um deles tem seus casos de uso específicos, mas antes de começar a trabalhar em qualquer um deles, é importante estar ciente dos que mencionamos no artigo.
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.
Aprenda os graus de Engenharia de Software online das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.