Big Data: Alat dan Teknologi yang Harus Diketahui
Diterbitkan: 2018-03-09Kami juga melihat bagaimana domain atau industri mana pun (sebutkan saja!) dapat meningkatkan operasinya dengan memanfaatkan Big Data dengan baik . Organisasi menyadari fakta ini dan mencoba untuk bergabung dengan sekelompok orang yang tepat, melengkapi mereka dengan seperangkat alat dan teknologi yang benar, dan memahami Big Data mereka .
Karena semakin banyak organisasi yang menyadari fakta ini, pasar Ilmu Data tumbuh semakin cepat bersama. Semua orang menginginkan sepotong kue ini – yang telah menghasilkan pertumbuhan besar-besaran dalam alat dan teknologi data besar.
Tonton video youtubenya.
Dalam artikel ini, kita akan berbicara tentang alat dan teknologi yang tepat yang harus Anda miliki dalam perangkat Anda saat Anda mengikuti kereta musik big data. Keakraban dengan alat-alat ini juga akan membantu Anda setiap wawancara mendatang yang mungkin Anda hadapi.
Daftar isi
Ekosistem Hadoop
Anda tidak mungkin berbicara tentang Big Data tanpa menyebutkan gajah di dalam ruangan (pun intended!) – Hadoop. Singkatan dari 'Platform berorientasi objek terdistribusi dengan ketersediaan tinggi', Hadoop pada dasarnya adalah kerangka kerja yang digunakan untuk memelihara, menyembuhkan diri sendiri, menangani kesalahan, dan mengamankan kumpulan data besar. Namun, selama bertahun-tahun, Hadoop telah mencakup seluruh ekosistem alat terkait . Tidak hanya itu, sebagian besar solusi Big Data komersial didasarkan pada Hadoop.

Tumpukan platform Hadoop yang khas terdiri dari HDFS, Hive, HBase, dan Pig.
HDFS
Itu singkatan dari Hadoop Distributed Filesystem. Ini dapat dianggap sebagai sistem penyimpanan file untuk Hadoop. HDFS berurusan dengan distribusi dan penyimpanan kumpulan data besar.

PetaKurangi
MapReduce memungkinkan kumpulan data besar untuk diproses dengan cepat secara paralel. Ini mengikuti ide sederhana – untuk menangani banyak data dalam waktu yang sangat singkat, cukup mempekerjakan lebih banyak pekerja untuk pekerjaan itu. Pekerjaan MapReduce tipikal diproses dalam dua fase: Map dan Reduce. Fase "Peta" mengirimkan kueri untuk diproses ke berbagai node dalam kluster Hadoop, dan fase "Pengurangan" mengumpulkan semua hasil untuk dikeluarkan menjadi satu nilai. MapReduce menangani pekerjaan penjadwalan, pekerjaan pemantauan, dan menjalankan kembali tugas yang gagal.
Sarang lebah
Hive adalah alat pergudangan data yang mengubah bahasa kueri menjadi perintah MapReduce. Ini diprakarsai oleh Facebook. Bagian terbaik tentang menggunakan Hive adalah pengembang dapat menggunakan pengetahuan SQL yang ada karena Hive menggunakan HQL (Hive Query Language) yang memiliki sintaks yang mirip dengan SQL klasik.
HBase
HBase adalah DBMS berorientasi kolom yang menangani data tidak terstruktur secara real time dan berjalan di atas Hadoop. SQL tidak dapat digunakan untuk kueri di HBase karena tidak menangani data terstruktur. Untuk itu, Java adalah bahasa yang disukai. HBase sangat efisien dalam membaca dan menulis kumpulan data besar secara real-time.
Babi
Pig adalah bahasa pemrograman prosedural tingkat tinggi yang diprakarsai oleh Yahoo! Dan menjadi open source pada tahun 2007. Seaneh kedengarannya, ini disebut Pig karena dapat menangani semua jenis data yang Anda lemparkan!
Percikan
Apache Spark layak disebutkan secara khusus dalam daftar ini karena merupakan mesin tercepat untuk pemrosesan Big Data . Ini digunakan oleh pemain utama termasuk Amazon, Yahoo!, eBay, dan Flipkart. Lihatlah semua organisasi yang didukung oleh Spark, dan Anda akan terpesona!
Spark dalam banyak hal telah ketinggalan zaman karena Hadoop memungkinkan Anda menjalankan program hingga seratus kali lebih cepat di memori, dan sepuluh kali lebih cepat di disk. 
Ini melengkapi niat yang diperkenalkan Hadoop . Ketika berhadapan dengan kumpulan data besar, salah satu perhatian utama adalah kecepatan pemrosesan, jadi, ada kebutuhan untuk mengurangi waktu tunggu antara eksekusi setiap kueri. Dan Spark melakukan hal itu – berkat modul bawaannya untuk streaming, pemrosesan grafik, pembelajaran mesin, dan dukungan SQL. Ini juga mendukung bahasa pemrograman yang paling umum – Java, Python, dan Scala.

Motif utama di balik pengenalan Spark adalah untuk mempercepat proses komputasi Hadoop. Namun, itu tidak boleh dilihat sebagai perpanjangan dari yang terakhir. Faktanya, Spark menggunakan Hadoop hanya untuk dua tujuan utama — penyimpanan dan pemrosesan. Selain itu, ini adalah alat yang cukup mandiri.
Tanpa SQL
Database tradisional (RDBMS) menyimpan informasi secara terstruktur dengan mendefinisikan baris dan kolom. Dimungkinkan di sana karena data yang disimpan tidak terstruktur atau semi terstruktur. Tetapi ketika kita berbicara tentang berurusan dengan Big Data , kita berbicara tentang kumpulan data yang sebagian besar tidak terstruktur. Dalam kumpulan data seperti itu, kueri menggunakan SQL tidak akan berfungsi, karena S (struktur) tidak ada di sini. Jadi, untuk mengatasinya, kami memiliki database NoSQL.

Basis data NoSQL dibangun untuk mengkhususkan diri dalam menyimpan data tidak terstruktur dan menyediakan pengambilan data yang cepat. Namun, mereka tidak memberikan tingkat konsistensi yang sama seperti database tradisional – Anda tidak bisa menyalahkan mereka untuk itu, salahkan datanya!
Basis data NoSQL yang paling populer termasuk MongoDB, Cassandra, Redis, dan Couchbase. Bahkan Oracle dan IBM – vendor RDBMS terkemuka – sekarang menawarkan database NoSQL, setelah melihat pertumbuhan pesat dalam penggunaannya.
Danau Data
Data lake telah mengalami peningkatan terus-menerus dalam penggunaannya selama beberapa tahun terakhir. Namun, banyak orang masih berpikir bahwa Data Lakes hanyalah Data Warehouse yang dikunjungi kembali – tetapi itu tidak benar. Satu-satunya kesamaan di antara keduanya adalah keduanya adalah repositori penyimpanan data. Terus terang, itu saja. 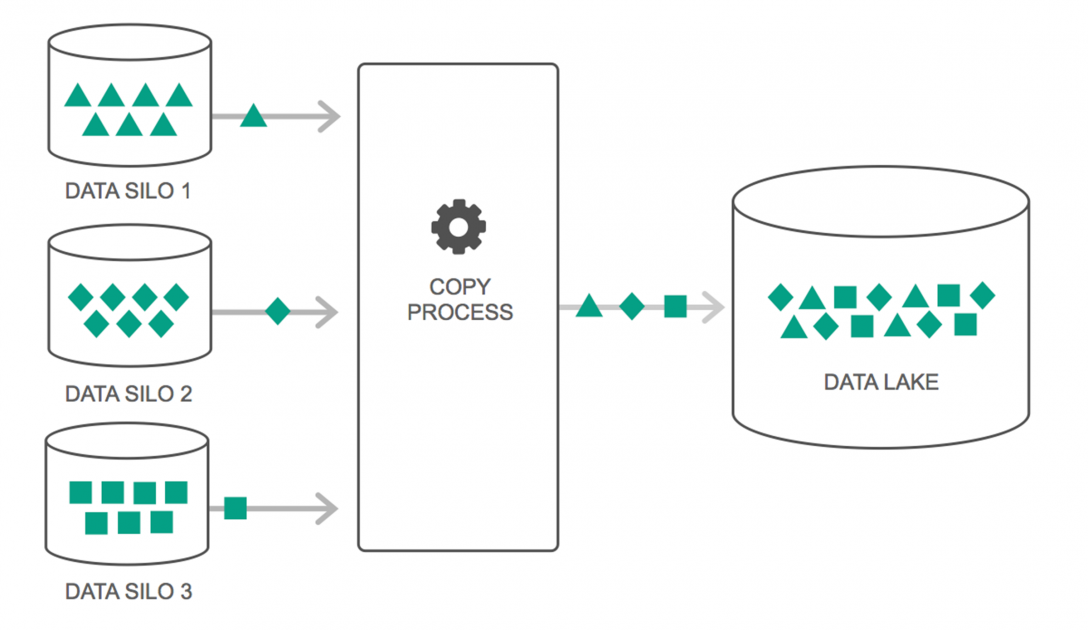
Data Lake dapat didefinisikan sebagai tempat penyimpanan yang menyimpan sejumlah besar data mentah dari berbagai sumber, dalam berbagai format, hingga dibutuhkan. Anda harus menyadari bahwa gudang data menyimpan data dalam struktur folder hierarkis, tetapi tidak demikian halnya dengan Data Lakes. Data Lakes menggunakan arsitektur datar untuk menyimpan kumpulan data.
Banyak perusahaan beralih ke Data Lakes untuk menyederhanakan pemrosesan mengakses Big Data mereka . Data Lakes menyimpan data yang dikumpulkan dalam keadaan alaminya – tidak seperti gudang data yang memproses data sebelum disimpan. Itulah mengapa metafora "danau" dan "gudang" sangat tepat. Jika Anda melihat data sebagai air, danau data dapat dianggap sebagai danau air – menyimpan air tanpa filter dan dalam bentuk alaminya, dan gudang data dapat dianggap sebagai air yang disimpan dalam botol dan disimpan di rak.

Database dalam memori
Dalam sistem komputer mana pun, RAM, atau Random Access Memory, bertanggung jawab untuk mempercepat pemrosesan. Menggunakan filosofi serupa, database dalam memori dikembangkan sehingga Anda dapat memindahkan Data ke sistem Anda, alih-alih membawa sistem ke data. Yang pada dasarnya berarti bahwa jika Anda menyimpan data dalam memori, itu akan mengurangi waktu pemrosesan dengan margin yang cukup besar. Pengambilan dan pengambilan data tidak akan merepotkan lagi karena semua data akan disimpan dalam memori.
Namun secara praktis, jika Anda menangani kumpulan data yang sangat besar, tidak mungkin untuk memasukkan semuanya ke dalam memori. Namun, Anda dapat menyimpan sebagian di dalam memori, memprosesnya, dan kemudian membawa bagian lain di dalam memori untuk diproses lebih lanjut. Untuk membantu itu, Hadoop menyediakan beberapa alat yang berisi database di disk dan di memori untuk mempercepat pemrosesan.
Membungkus…
Daftar yang disediakan dalam artikel ini sama sekali bukan “daftar lengkap alat dan teknologi Big Data ”. Sebaliknya, ini berfokus pada alat dan teknologi Big Data yang "harus diketahui" . Bidang Big Data terus berkembang dan teknologi baru mengungguli yang lama dengan sangat cepat. Ada banyak lagi teknologi di luar tumpukan Hadoop-Spark, seperti Finch, Kafka, Nifi, Samza, dan banyak lagi. Alat - alat ini memberikan hasil yang mulus tanpa cegukan. Masing-masing memiliki kasus penggunaan khusus, tetapi sebelum Anda mengerjakannya, penting untuk mengetahui yang kami sebutkan di artikel.
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.
Pelajari gelar Rekayasa Perangkat Lunak secara online dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.