Big Data: narzędzia i technologie trzeba znać
Opublikowany: 2018-03-09Widzieliśmy również, jak każda domena lub branża (wystarczy ją nazwać!) może usprawnić swoje działanie, dobrze wykorzystując Big Data . Organizacje zdają sobie z tego sprawę i starają się zatrudnić odpowiednią grupę ludzi, wyposażyć ich w odpowiedni zestaw narzędzi i technologii oraz nadać sens swoim Big Data .
Ponieważ coraz więcej organizacji zdaje sobie z tego sprawę, rynek Data Science rośnie wraz z nim jeszcze szybciej. Każdy chce kawałek tego tortu – co zaowocowało ogromnym rozwojem narzędzi i technologii Big Data.
Obejrzyj wideo na youtube.
W tym artykule porozmawiamy o właściwych narzędziach i technologiach, które powinieneś mieć w swoim zestawie narzędzi, gdy wskoczysz na modę big data. Znajomość tych narzędzi pomoże Ci również w nadchodzących rozmowach kwalifikacyjnych, z którymi możesz się spotkać.
Spis treści
Ekosystem Hadoop
Nie można rozmawiać o Big Data bez wspomnienia o słoniu w pokoju (gra słów zamierzona!) – Hadoop. Skrót od „High-availability rozproszona platforma obiektowa” Hadoop jest zasadniczo strukturą używaną do utrzymywania, samonaprawiania, obsługi błędów i zabezpieczania dużych zbiorów danych. Jednak przez lata Hadoop obejmował cały ekosystem powiązanych narzędzi . Mało tego, większość komercyjnych rozwiązań Big Data opiera się na Hadoop.

Typowy stos platformy Hadoop składa się z HDFS, Hive, HBase i Pig.
HDFS
Oznacza rozproszony system plików Hadoop. Można go traktować jako system przechowywania plików dla Hadoop. HDFS zajmuje się dystrybucją i przechowywaniem dużych zbiorów danych.

MapaReduce
MapReduce umożliwia szybkie równoległe przetwarzanie ogromnych zestawów danych. Wynika to z prostego pomysłu – aby poradzić sobie z dużą ilością danych w bardzo krótkim czasie, po prostu zatrudnij więcej pracowników do pracy. Typowe zadanie MapReduce jest przetwarzane w dwóch fazach: Mapowanie i Redukcja. Faza „Map” wysyła zapytanie do przetworzenia do różnych węzłów w klastrze Hadoop, a faza „Reduce” zbiera wszystkie wyniki w celu uzyskania pojedynczej wartości. MapReduce zajmuje się planowaniem zadań, monitorowaniem zadań i ponownym wykonywaniem nieudanego zadania.
Ul
Hive to narzędzie do hurtowni danych, które konwertuje język zapytań na polecenia MapReduce. Został zainicjowany przez Facebooka. Najlepsze w korzystaniu z Hive jest to, że programiści mogą korzystać z istniejącej wiedzy na temat SQL, ponieważ Hive używa HQL (Hive Query Language), który ma składnię podobną do klasycznego SQL.
HBase
HBase to DBMS zorientowany na kolumny, który zajmuje się nieustrukturyzowanymi danymi w czasie rzeczywistym i działa na platformie Hadoop. SQL nie może być używany do wykonywania zapytań w HBase, ponieważ nie obsługuje danych strukturalnych. W tym celu preferowanym językiem jest Java. HBase niezwykle wydajnie odczytuje i zapisuje duże zestawy danych w czasie rzeczywistym.
Świnia
Pig to proceduralny język programowania wysokiego poziomu, który został zainicjowany przez Yahoo! I stał się open source w 2007. Choć może to zabrzmieć dziwnie, nazywa się Pig, ponieważ może obsłużyć każdy rodzaj danych, które na niego wrzucisz!
Iskra
Na szczególną wzmiankę na tej liście zasługuje Apache Spark, który jest najszybszym silnikiem do przetwarzania Big Data . Jest używany przez głównych graczy, w tym Amazon, Yahoo!, eBay i Flipkart. Przyjrzyj się wszystkim organizacjom , które są zasilane przez Spark, a będziesz zachwycony!
Spark pod wieloma względami jest przestarzały, ponieważ umożliwia uruchamianie programów do stu razy szybciej w pamięci i dziesięć razy szybciej na dysku. 
Uzupełnia intencje, z jakimi wprowadzono Hadoop . W przypadku dużych zbiorów danych jednym z głównych problemów jest szybkość przetwarzania, dlatego zaistniała potrzeba skrócenia czasu oczekiwania między wykonaniem każdego zapytania. Spark robi dokładnie to — dzięki wbudowanym modułom do przesyłania strumieniowego, przetwarzania wykresów, uczenia maszynowego i obsługi SQL. Obsługuje również najpopularniejsze języki programowania – Java, Python i Scala.

Głównym motywem wprowadzenia Sparka było przyspieszenie procesów obliczeniowych Hadoopa. Nie należy go jednak postrzegać jako przedłużenie tego ostatniego. W rzeczywistości Spark używa Hadoop tylko do dwóch głównych celów — przechowywania i przetwarzania. Poza tym jest to całkiem samodzielne narzędzie.
NoSQL
Tradycyjne bazy danych (RDBMS) przechowują informacje w uporządkowany sposób, definiując wiersze i kolumny. Jest to możliwe, ponieważ przechowywane dane nie są nieustrukturyzowane ani częściowo ustrukturyzowane. Ale kiedy mówimy o radzeniu sobie z Big Data , mamy na myśli w dużej mierze nieustrukturyzowane zbiory danych. W takich zestawach danych zapytania za pomocą SQL nie będą działać, ponieważ S (struktura) tutaj nie istnieje. Aby sobie z tym poradzić, mamy bazy danych NoSQL.

Bazy danych NoSQL zostały stworzone, aby specjalizować się w przechowywaniu nieustrukturyzowanych danych i zapewniać szybkie pobieranie danych. Jednak nie zapewniają one takiego samego poziomu spójności jak tradycyjne bazy danych — nie można ich za to winić, obwiniaj dane!
Najpopularniejsze bazy danych NoSQL to MongoDB, Cassandra, Redis i Couchbase. Nawet Oracle i IBM – wiodący dostawcy RDBMS – oferują teraz bazy danych NoSQL, po szybkim wzroście ich wykorzystania.
Jeziora danych
W ciągu ostatnich kilku lat korzystanie z jezior danych stale wzrastało. Jednak wiele osób nadal uważa, że Data Lakes to tylko powrót do hurtowni danych — ale to nieprawda. Jedyne podobieństwo między nimi polega na tym, że oba są repozytoriami do przechowywania danych. Szczerze, to wszystko. 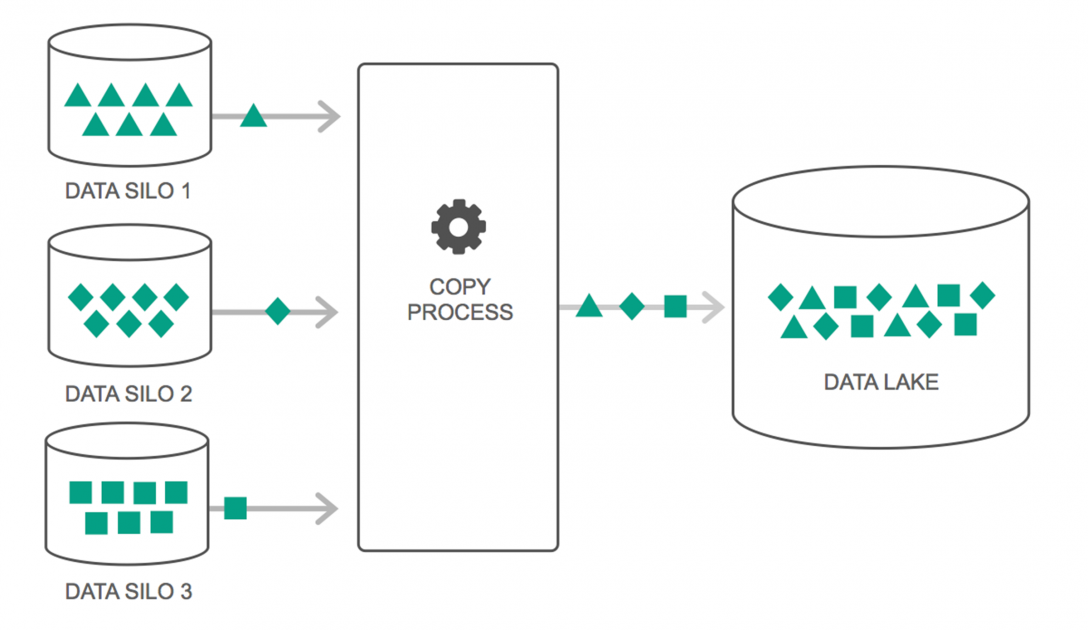
Data Lake można zdefiniować jako repozytorium przechowywania, które przechowuje ogromną ilość surowych danych z różnych źródeł w różnych formatach, dopóki nie będą potrzebne. Musisz mieć świadomość, że magazyny danych przechowują dane w hierarchicznej strukturze folderów, ale tak nie jest w przypadku Data Lakes. Data Lakes używają płaskiej architektury do zapisywania zestawów danych.
Wiele przedsiębiorstw przechodzi na Data Lakes, aby uprościć przetwarzanie dostępu do swoich Big Data . Data Lakes przechowują zebrane dane w ich naturalnym stanie – w przeciwieństwie do hurtowni danych, która przetwarza dane przed ich przechowywaniem. Dlatego metafora „jeziora” i „magazynu” jest trafna. Jeśli postrzegasz dane jako wodę, jezioro danych można traktować jako jezioro wodne – przechowujące wodę w postaci niefiltrowanej i w jej naturalnej postaci, a hurtownię danych można traktować jako wodę przechowywaną w butelkach i przechowywaną na półce.

Bazy danych w pamięci
W każdym systemie komputerowym RAM lub pamięć o dostępie swobodnym jest odpowiedzialna za przyspieszenie przetwarzania. Stosując podobną filozofię, stworzono bazy danych w pamięci, aby można było przenieść dane do systemu zamiast przenosić system do danych. Zasadniczo oznacza to, że jeśli przechowujesz dane w pamięci, skróci to czas przetwarzania o spory margines. Pobieranie i odzyskiwanie danych nie będzie już uciążliwe, ponieważ wszystkie dane będą w pamięci.
Ale praktycznie, jeśli masz do czynienia z naprawdę dużym zbiorem danych, nie jest możliwe uzyskanie wszystkiego w pamięci. Możesz jednak zachować jej część w pamięci, przetworzyć ją, a następnie przenieść inną część w pamięci do dalszego przetwarzania. Aby w tym pomóc, Hadoop udostępnia kilka narzędzi , które zawierają zarówno bazy danych na dysku, jak i w pamięci, aby przyspieszyć przetwarzanie.
Podsumowanie…
Lista zamieszczona w tym artykule nie jest w żadnym wypadku „kompleksową listą narzędzi i technologii Big Data ”. Zamiast tego koncentruje się na narzędziach i technologiach Big Data , które trzeba znać. Dziedzina Big Data stale się rozwija, a nowe technologie bardzo szybko przestarzały. Istnieje wiele innych technologii poza stosem Hadoop-Spark, takich jak Finch, Kafka, Nifi, Samza i inne. Narzędzia te zapewniają bezproblemowe rezultaty bez czkawki. Każdy z nich ma swoje specyficzne przypadki użycia, ale zanim zaczniesz pracować nad którymkolwiek z nich, ważne jest, aby być świadomym tych, o których wspomnieliśmy w artykule.
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.
Ucz się stopni inżynierii oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.