Big Data: ต้องรู้จักเครื่องมือและเทคโนโลยี
เผยแพร่แล้ว: 2018-03-09นอกจากนี้เรายังเห็นว่าโดเมนหรืออุตสาหกรรมใดๆ (คุณแค่ตั้งชื่อมัน!) สามารถปรับปรุงการดำเนินงานโดยนำ Big Data ไปใช้ให้เกิดประโยชน์ ได้อย่างไร องค์กรต่างๆ ตระหนักถึงข้อเท็จจริงนี้และกำลังพยายามเข้าร่วมกลุ่มคนที่เหมาะสม ปกป้องพวกเขาด้วยชุด เครื่องมือ และเทคโนโลยีที่ถูกต้อง และทำความเข้าใจ บิ๊กดาต้า ของ ตน
เมื่อองค์กรต่างๆ ตระหนักถึงความจริงนี้มากขึ้นเรื่อยๆ ตลาด Data Science ก็เติบโตขึ้นอย่างรวดเร็วควบคู่ไปกับ ทุกคนต้องการพายชิ้นนี้ ซึ่งส่งผลให้ เครื่องมือ และเทคโนโลยีบิ๊กดาต้าเติบโตอย่างมาก
ดูวิดีโอยูทูบ
ในบทความนี้ เราจะพูดถึง เครื่องมือ และเทคโนโลยีที่เหมาะสมที่คุณควรมีในชุดเครื่องมือของคุณ เมื่อคุณก้าวเข้าสู่กลุ่มข้อมูลขนาดใหญ่ ความคุ้นเคยกับเครื่องมือเหล่านี้จะช่วยให้คุณมีการสัมภาษณ์ที่จะเกิดขึ้นที่คุณอาจเผชิญ
สารบัญ
Hadoop ระบบนิเวศ
คุณไม่สามารถพูดถึง Big Data ได้โดยไม่ต้องพูดถึงช้างในห้อง (ปุนตั้งใจ!) – Hadoop ตัวย่อสำหรับ 'แพลตฟอร์มเชิงวัตถุแบบกระจายความพร้อมใช้งานสูง" Hadoop เป็นเฟรมเวิร์กที่ใช้สำหรับการบำรุงรักษา ซ่อมแซมตัวเอง การจัดการข้อผิดพลาด และการรักษาความปลอดภัยชุดข้อมูลขนาดใหญ่ อย่างไรก็ตาม ในช่วงหลายปีที่ผ่านมา Hadoop ได้รวบรวมระบบนิเวศทั้งหมดของ เครื่องมือ ที่ เกี่ยวข้อง ไม่เพียงเท่านั้น โซลูชัน Big Data เชิงพาณิชย์ส่วนใหญ่ ยังใช้ Hadoop

สแต็คแพลตฟอร์ม Hadoop ทั่วไปประกอบด้วย HDFS, Hive, HBase และ Pig
HDFS
ย่อมาจาก Hadoop Distributed Filesystem เรียกได้ว่าเป็นระบบจัดเก็บไฟล์สำหรับ Hadoop HDFS เกี่ยวข้องกับการกระจายและการจัดเก็บชุดข้อมูลขนาดใหญ่

แผนที่ลด
MapReduce ช่วยให้สามารถประมวลผลชุดข้อมูลขนาดใหญ่ได้อย่างรวดเร็วในแบบคู่ขนาน เป็นไปตามแนวคิดง่ายๆ ในการจัดการกับข้อมูลจำนวนมากในเวลาอันสั้น เพียงแค่จ้างพนักงานให้มากขึ้นสำหรับงาน งาน MapReduce ทั่วไปมีการประมวลผลในสองขั้นตอน: แผนที่และการลด เฟส "แผนที่" จะส่งแบบสอบถามสำหรับการประมวลผลไปยังโหนดต่างๆ ในคลัสเตอร์ Hadoop และเฟส "ลด" จะรวบรวมผลลัพธ์ทั้งหมดเพื่อส่งออกเป็นค่าเดียว MapReduce ดูแลการจัดกำหนดการงาน ตรวจสอบงาน และดำเนินการงานที่ล้มเหลวอีกครั้ง
ไฮฟ์
Hive เป็นเครื่องมือคลังข้อมูลที่แปลงภาษาแบบสอบถามเป็นคำสั่ง MapReduce มันถูกริเริ่มโดย Facebook ส่วนที่ดีที่สุดเกี่ยวกับการใช้ Hive คือนักพัฒนาสามารถใช้ความรู้ SQL ที่มีอยู่ได้ เนื่องจาก Hive ใช้ HQL (Hive Query Language) ซึ่งมีรูปแบบคล้ายกับ SQL แบบคลาสสิก
HBase
HBase เป็น DBMS เชิงคอลัมน์ซึ่งเกี่ยวข้องกับข้อมูลที่ไม่มีโครงสร้างในแบบเรียลไทม์และทำงานบน Hadoop ไม่สามารถใช้ SQL ในการสืบค้นบน HBase ได้ เนื่องจากไม่ได้จัดการกับข้อมูลที่มีโครงสร้าง สำหรับสิ่งนั้น Java เป็นภาษาที่ต้องการ HBase มีประสิทธิภาพอย่างมากในการอ่านและเขียนชุดข้อมูลขนาดใหญ่ในแบบเรียลไทม์
หมู
Pig เป็นภาษาโปรแกรมขั้นสูงที่ริเริ่มโดย Yahoo! และกลายเป็นโอเพ่นซอร์สในปี 2550 แม้จะฟังดูแปลก แต่ก็เรียกว่า Pig เพราะสามารถจัดการข้อมูลประเภทใดก็ได้ที่คุณส่ง!
Spark
Apache Spark สมควรได้รับการกล่าวถึงเป็นพิเศษในรายการนี้ เนื่องจากเป็นเครื่องมือที่เร็วที่สุดสำหรับ การ ประมวลผล Big Data มันถูกนำไปใช้โดยผู้เล่นหลักเช่น Amazon, Yahoo!, eBay และ Flipkart ดู องค์กรทั้งหมด ที่ขับเคลื่อนโดย Spark แล้วคุณจะทึ่ง!
Spark มี Hadoop ที่ล้าสมัยในหลาย ๆ ด้าน เนื่องจากช่วยให้คุณเรียกใช้โปรแกรมในหน่วยความจำได้เร็วขึ้นสูงสุดร้อยเท่า และบนดิสก์เร็วขึ้นสิบเท่า 
มันเติมเต็มความตั้งใจที่มี การแนะนำ Hadoop เมื่อต้องจัดการกับชุดข้อมูลขนาดใหญ่ หนึ่งในความกังวลหลักคือความเร็วในการประมวลผล ดังนั้นจึงจำเป็นต้องลดเวลารอระหว่างการดำเนินการค้นหาแต่ละรายการ และ Spark ก็ทำอย่างนั้นจริงๆ ด้วยโมดูลในตัวสำหรับการสตรีม การประมวลผลกราฟ แมชชีนเลิร์นนิง และการสนับสนุน SQL นอกจากนี้ยังรองรับภาษาโปรแกรมทั่วไป เช่น Java, Python และ Scala

แรงจูงใจหลักที่อยู่เบื้องหลังการแนะนำ Spark คือการเร่งกระบวนการคำนวณของ Hadoop อย่างไรก็ตาม ไม่ควรมองว่าเป็นส่วนเสริมของส่วนหลัง อันที่จริง Spark ใช้ Hadoop เพื่อจุดประสงค์หลักสองประการเท่านั้น - การจัดเก็บและการประมวลผล นอกจากนั้น มันยังเป็นเครื่องมือแบบสแตนด์อโลนอีกด้วย
NoSQL
ฐานข้อมูลแบบดั้งเดิม (RDBMS) จัดเก็บข้อมูลในลักษณะที่มีโครงสร้างโดยการกำหนดแถวและคอลัมน์ เป็นไปได้เนื่องจากข้อมูลที่จัดเก็บไม่มีโครงสร้างหรือกึ่งโครงสร้าง แต่เมื่อเราพูดถึงการจัดการกับ Big Data เรากำลังพูดถึงชุดข้อมูลที่ไม่มีโครงสร้างเป็นส่วนใหญ่ ในชุดข้อมูลดังกล่าว การสืบค้นโดยใช้ SQL จะไม่ทำงาน เนื่องจากไม่มี S (โครงสร้าง) ที่นี่ ในการจัดการกับสิ่งนั้น เรามีฐานข้อมูล NoSQL

ฐานข้อมูล NoSQL สร้างขึ้นเพื่อเชี่ยวชาญในการจัดเก็บข้อมูลที่ไม่มีโครงสร้างและให้การดึงข้อมูลอย่างรวดเร็ว อย่างไรก็ตาม ฐานข้อมูลเหล่านี้ไม่ได้ให้ความสอดคล้องในระดับเดียวกับฐานข้อมูลแบบเดิม – คุณไม่สามารถตำหนิพวกเขาได้ โทษข้อมูล!
ฐานข้อมูล NoSQL ที่ได้รับความนิยมมากที่สุด ได้แก่ MongoDB, Cassandra, Redis และ Couchbase แม้แต่ Oracle และ IBM ซึ่งเป็นผู้จำหน่าย RDBMS ชั้นนำ ก็นำเสนอฐานข้อมูล NoSQL หลังจากที่ได้เห็นการใช้งานที่เพิ่มขึ้นอย่างรวดเร็ว
Data Lakes
Data Lake มีการใช้งานเพิ่มขึ้นอย่างต่อเนื่องในช่วงสองสามปีที่ผ่านมา อย่างไรก็ตาม ผู้คนจำนวนมากยังคงคิดว่า Data Lakes เป็นเพียง Data Warehouse ที่กลับมาเยี่ยมชมอีกครั้ง แต่นั่นไม่เป็นความจริง ความคล้ายคลึงกันเพียงอย่างเดียวระหว่างทั้งสองคือทั้งสองเป็นที่เก็บข้อมูล บอกตรงๆ ว่า 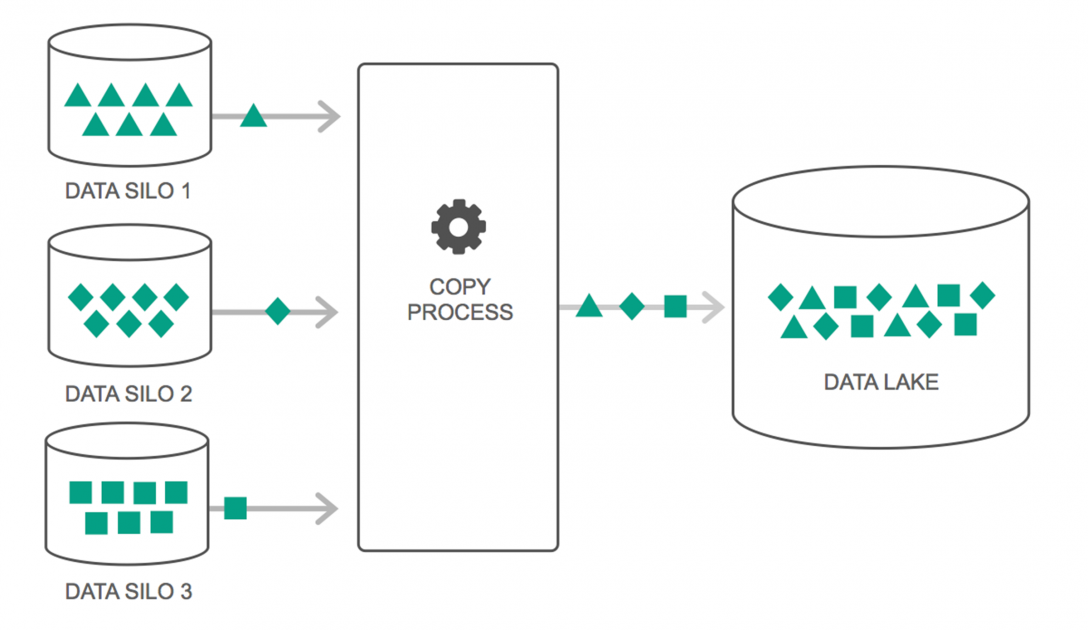
Data Lake ถูกกำหนดให้เป็นพื้นที่เก็บข้อมูลซึ่งมีข้อมูลดิบจำนวนมากจากแหล่งที่มาที่หลากหลาย ในรูปแบบที่หลากหลาย จนกว่าจะมีความจำเป็น คุณต้องทราบว่าคลังข้อมูลจัดเก็บข้อมูลในโครงสร้างโฟลเดอร์แบบลำดับชั้น แต่นั่นไม่ใช่กรณีของ Data Lakes Data Lakes ใช้สถาปัตยกรรมแบบเรียบเพื่อบันทึกชุดข้อมูล
องค์กรหลายแห่งกำลังเปลี่ยนไปใช้ Data Lakes เพื่อลดความซับซ้อนในการประมวลผลการเข้าถึง Big Data Data Lakes จัดเก็บข้อมูลที่รวบรวมไว้ในสภาพธรรมชาติ ซึ่งแตกต่างจากคลังข้อมูลซึ่งประมวลผลข้อมูลก่อนจัดเก็บ นั่นเป็นเหตุผลที่คำเปรียบเทียบ "ทะเลสาบ" และ "คลังสินค้า" เหมาะสม หากคุณเห็นข้อมูลเป็นน้ำ ดาต้าเลคสามารถนึกถึงทะเลสาบน้ำ โดยเก็บน้ำที่ไม่มีการกรองและอยู่ในรูปแบบที่เป็นธรรมชาติ และคลังข้อมูลสามารถคิดได้ว่าเป็นน้ำที่เก็บไว้ในขวดและเก็บไว้บนหิ้ง

ฐานข้อมูลในหน่วยความจำ
ในระบบคอมพิวเตอร์ใดๆ RAM หรือ Random Access Memory มีหน้าที่เร่งความเร็วในการประมวลผล โดยใช้ปรัชญาที่คล้ายคลึงกัน ฐานข้อมูลในหน่วยความจำได้รับการพัฒนาเพื่อให้คุณสามารถย้ายข้อมูลไปยังระบบของคุณ แทนที่จะนำระบบของคุณไปยังข้อมูล ความหมายหลักคือ หากคุณจัดเก็บข้อมูลในหน่วยความจำ เวลาในการประมวลผลจะลดลงค่อนข้างมาก การดึงและดึงข้อมูลจะไม่เจ็บปวดอีกต่อไป เนื่องจากข้อมูลทั้งหมดจะอยู่ในหน่วยความจำ
แต่ในทางปฏิบัติ หากคุณกำลังจัดการกับชุดข้อมูลขนาดใหญ่จริงๆ จะไม่สามารถดึงข้อมูลทั้งหมดไว้ในหน่วยความจำได้ อย่างไรก็ตาม คุณสามารถเก็บส่วนหนึ่งไว้ในหน่วยความจำ ประมวลผล แล้วนำส่วนอื่นในหน่วยความจำมาประมวลผลต่อไปได้ เพื่อช่วยในเรื่องนั้น Hadoop มี เครื่องมือ หลายอย่าง ที่มีฐานข้อมูลทั้งบนดิสก์และในหน่วยความจำเพื่อเพิ่มความเร็วในการประมวลผล
ห่อ…
รายการที่ให้ไว้ในบทความนี้ไม่ใช่ "รายการ เครื่องมือ และเทคโนโลยี Big Data ที่ครอบคลุม" แต่จะเน้นไปที่ เครื่องมือ และเทคโนโลยี “ที่ต้องรู้” ของ Big Data ขอบเขตของ Big Data มีการพัฒนาอย่างต่อเนื่องและเทคโนโลยีใหม่ๆ ทำให้เทคโนโลยีเก่าล้าสมัยไปอย่างรวดเร็ว มีเทคโนโลยีอีกมากมายนอกเหนือจากสแต็ค Hadoop-Spark เช่น Finch, Kafka, Nifi, Samza และอีกมากมาย เครื่องมือ เหล่านี้ ให้ผลลัพธ์ที่ราบรื่นและไม่สะดุด แต่ละรายการมีกรณีการใช้งานเฉพาะ แต่ก่อนที่คุณจะเริ่มดำเนินการใดๆ สิ่งสำคัญคือต้องระวังกรณีที่เรากล่าวถึงในบทความ
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ
เรียนรู้ ปริญญาวิศวกรรมซอฟต์แวร์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว