البيانات الضخمة: يجب أن تعرف الأدوات والتقنيات
نشرت: 2018-03-09لقد رأينا أيضًا كيف يمكن لأي مجال أو صناعة (سمها ما شئت!) تحسين عملياتها من خلال استخدام البيانات الضخمة بشكل جيد . تدرك المؤسسات هذه الحقيقة وتحاول إعداد المجموعة المناسبة من الأشخاص وتزويدهم بالمجموعة الصحيحة من الأدوات والتقنيات وفهم بياناتهم الضخمة .
مع تزايد عدد المؤسسات التي تستيقظ على هذه الحقيقة ، ينمو سوق علوم البيانات بسرعة أكبر جنبًا إلى جنب. الكل يريد قطعة من هذه الكعكة - مما أدى إلى نمو هائل في أدوات وتقنيات البيانات الضخمة.
شاهد فيديو يوتيوب.
في هذه المقالة ، سنتحدث عن الأدوات والتقنيات المناسبة التي يجب أن تكون لديك في مجموعة الأدوات الخاصة بك وأنت تقفز في عربة البيانات الضخمة. سيساعدك التعرف على هذه الأدوات أيضًا على أي مقابلات قادمة قد تواجهها.
جدول المحتويات
نظام Hadoop البيئي
لا يمكنك التحدث عن البيانات الضخمة دون ذكر الفيل في الغرفة (يقصد التورية!) - Hadoop. يعد Hadoop ، وهو اختصار لـ "نظام أساسي موجه للكائنات الموزعة عالية التوفر" ، في الأساس إطار عمل يستخدم للصيانة والشفاء الذاتي ومعالجة الأخطاء وتأمين مجموعات البيانات الكبيرة. ومع ذلك ، على مر السنين ، شمل Hadoop نظامًا بيئيًا كاملًا من الأدوات ذات الصلة . ليس ذلك فحسب ، تعتمد معظم حلول البيانات الضخمة التجارية على Hadoop.

يتكون مكدس منصة Hadoop النموذجي من HDFS و Hive و HBase و Pig.
HDFS
إنها تعني نظام الملفات الموزعة Hadoop. يمكن اعتباره نظام تخزين ملفات لـ Hadoop. تتعامل HDFS مع توزيع وتخزين مجموعات البيانات الكبيرة.

مابريديوس
يسمح MapReduce بمعالجة مجموعات البيانات الضخمة بسرعة بالتوازي. إنها تتبع فكرة بسيطة - للتعامل مع الكثير من البيانات في وقت قصير جدًا ، ما عليك سوى توظيف المزيد من العمال للوظيفة. تتم معالجة مهمة MapReduce النموذجية على مرحلتين: Map و Reduce. ترسل مرحلة "الخريطة" استعلامًا للمعالجة إلى عقد مختلفة في مجموعة Hadoop ، وتجمع مرحلة "تقليل" كل النتائج لإخراجها في قيمة واحدة. يعتني MapReduce بجدولة الوظائف ومراقبة الوظائف وإعادة تنفيذ المهمة الفاشلة.
خلية نحل
Hive هي أداة لتخزين البيانات تقوم بتحويل لغة الاستعلام إلى أوامر MapReduce. تم إطلاقه بواسطة Facebook. أفضل جزء في استخدام Hive هو أنه يمكن للمطورين استخدام معارفهم الحالية في SQL لأن Hive تستخدم HQL (لغة استعلام Hive) التي تحتوي على صيغة مشابهة لـ SQL الكلاسيكية.
HBase
HBase عبارة عن نظام DBMS موجه نحو العمود يتعامل مع البيانات غير المهيكلة في الوقت الفعلي ويعمل فوق Hadoop. لا يمكن استخدام SQL للاستعلام عن HBase لأنها لا تتعامل مع البيانات المنظمة. لذلك ، تعد Java هي اللغة المفضلة. HBase فعال للغاية في قراءة وكتابة مجموعات البيانات الكبيرة في الوقت الفعلي.
شخص شره
Pig هي لغة برمجة إجرائية عالية المستوى بدأتها Yahoo! وأصبحت مفتوحة المصدر في عام 2007. قد يبدو الأمر غريبًا ، إلا أنه يسمى Pig لأنه يمكنه التعامل مع أي نوع من البيانات التي تلقيها عليه!
شرارة
يستحق Apache Spark ذكرًا خاصًا في هذه القائمة لأنه أسرع محرك لمعالجة البيانات الضخمة . يتم استخدامه من قبل كبار اللاعبين بما في ذلك Amazon و Yahoo! و eBay و Flipkart. ألقِ نظرة على جميع المؤسسات التي تدعمها Spark ، وستتفاجأ!
يحتوي Spark على Hadoop من نواح كثيرة لأنه يتيح لك تشغيل برامج أسرع في الذاكرة بما يصل إلى مائة مرة ، وأسرع عشر مرات على القرص. 
إنه يكمل النوايا التي تم بها تقديم Hadoop . عند التعامل مع مجموعات البيانات الكبيرة ، فإن أحد الاهتمامات الرئيسية هو سرعة المعالجة ، لذلك كانت هناك حاجة لتقليل وقت الانتظار بين تنفيذ كل استعلام. ويفعل Spark ذلك بالضبط - بفضل وحداته المدمجة للبث ومعالجة الرسوم البيانية والتعلم الآلي ودعم SQL. كما أنه يدعم لغات البرمجة الأكثر شيوعًا - Java و Python و Scala.

كان الدافع الرئيسي وراء تقديم Spark هو تسريع العمليات الحسابية لـ Hadoop. ومع ذلك ، لا ينبغي أن ينظر إليه على أنه امتداد لهذا الأخير. في الواقع ، يستخدم Spark Hadoop لغرضين رئيسيين فقط - التخزين والمعالجة. بخلاف ذلك ، إنها أداة قائمة بذاتها إلى حد ما.
NoSQL
تقوم قواعد البيانات التقليدية (RDBMS) بتخزين المعلومات بطريقة منظمة عن طريق تحديد الصفوف والأعمدة. هذا ممكن لأن البيانات المخزنة ليست غير منظمة أو شبه منظمة. ولكن عندما نتحدث عن التعامل مع البيانات الضخمة ، فإننا نتحدث عن مجموعات بيانات غير منظمة إلى حد كبير. في مجموعات البيانات هذه ، لن يعمل الاستعلام باستخدام SQL ، لأن S (بنية) غير موجودة هنا. لذا ، للتعامل مع ذلك ، لدينا قواعد بيانات NoSQL.

تم تصميم قواعد بيانات NoSQL للتخصص في تخزين البيانات غير المهيكلة وتوفير عمليات استرجاع سريعة للبيانات. ومع ذلك ، فهي لا توفر نفس المستوى من الاتساق مثل قواعد البيانات التقليدية - لا يمكنك إلقاء اللوم عليهم في ذلك ، إلقاء اللوم على البيانات!
تشمل قواعد بيانات NoSQL الأكثر شيوعًا MongoDB و Cassandra و Redis و Couchbase. حتى Oracle و IBM - بائعي RDBMS الرائدين - يقدمون الآن قواعد بيانات NoSQL ، بعد رؤية النمو السريع في استخدامها.
بحيرات البيانات
شهدت بحيرات البيانات ارتفاعًا مستمرًا في استخدامها على مدار العامين الماضيين. ومع ذلك ، لا يزال الكثير من الناس يعتقدون أن Data Lakes مجرد مستودع بيانات أعيد النظر فيه - لكن هذا ليس صحيحًا. التشابه الوحيد بين الاثنين هو أنهما مستودعات تخزين البيانات. بصراحة هذا كل شيء. 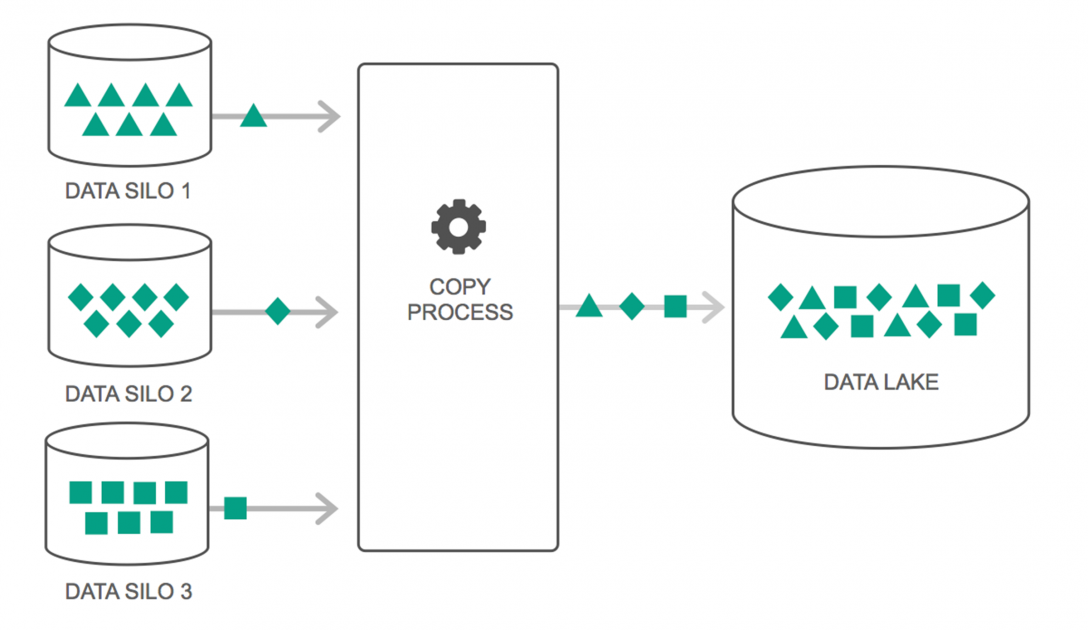
يمكن تعريف Data Lake على أنها مستودع تخزين يحتوي على كمية هائلة من البيانات الأولية من مجموعة متنوعة من المصادر ، في مجموعة متنوعة من التنسيقات ، حتى يتم الاحتياج إليها. يجب أن تدرك أن مستودعات البيانات تخزن البيانات في هيكل مجلد هرمي ، ولكن هذا ليس هو الحال مع Data Lakes. تستخدم بحيرات البيانات بنية مسطحة لحفظ مجموعات البيانات.
تتحول العديد من المؤسسات إلى Data Lakes لتبسيط معالجة الوصول إلى بياناتهم الضخمة . تخزن Data Lakes البيانات التي تم جمعها في حالتها الطبيعية - على عكس مستودع البيانات الذي يعالج البيانات قبل التخزين. هذا هو السبب في أن استعارة "البحيرة" و "المستودع" مناسبة. إذا كنت ترى البيانات على أنها مياه ، فيمكن التفكير في بحيرة البيانات على أنها بحيرة مائية - حيث يتم تخزين المياه غير المفلترة وفي شكلها الطبيعي ، ويمكن اعتبار مستودع البيانات على أنه مياه مخزنة في زجاجات ويتم الاحتفاظ بها على الرف.

قواعد البيانات في الذاكرة
في أي نظام كمبيوتر ، تكون ذاكرة الوصول العشوائي (RAM) أو ذاكرة الوصول العشوائي (Random Access Memory) مسؤولة عن تسريع المعالجة. باستخدام فلسفة مماثلة ، تم تطوير قواعد البيانات في الذاكرة بحيث يمكنك نقل بياناتك إلى نظامك ، بدلاً من نقل نظامك إلى البيانات. ما يعنيه هذا بشكل أساسي هو أنه إذا قمت بتخزين البيانات في الذاكرة ، فسوف تقلل من وقت المعالجة بهامش كبير. لن يكون جلب البيانات واستعادتها مشكلة بعد الآن حيث ستكون جميع البيانات في الذاكرة.
ولكن من الناحية العملية ، إذا كنت تتعامل مع مجموعة بيانات كبيرة حقًا ، فلا يمكن حفظها كلها في الذاكرة. ومع ذلك ، يمكنك الاحتفاظ بجزء منه في الذاكرة ومعالجته ثم إحضار جزء آخر في الذاكرة لمزيد من المعالجة. للمساعدة في ذلك ، يوفر Hadoop العديد من الأدوات التي تحتوي على قواعد بيانات على القرص وداخل الذاكرة لتسريع المعالجة.
تغليف…
القائمة الواردة في هذه المقالة ليست بأي حال من الأحوال "قائمة شاملة لأدوات وتقنيات البيانات الضخمة". وبدلاً من ذلك ، فإنه يركز على أدوات وتقنيات البيانات الضخمة "التي يجب معرفتها" . يتطور مجال البيانات الضخمة باستمرار والتقنيات الجديدة تتقادم بسرعة كبيرة مع التقنيات القديمة. هناك العديد من التقنيات الأخرى بخلاف Hadoop-Spark stack ، مثل Finch و Kafka و Nifi و Samza والمزيد. توفر هذه الأدوات نتائج سلسة بلا عوائق. لكل منها حالات استخدام خاصة بها ، ولكن قبل أن تبدأ في العمل على أي منها ، من المهم أن تكون على دراية بتلك التي ذكرناها في المقالة.
إذا كنت مهتمًا بمعرفة المزيد عن البيانات الضخمة ، فراجع دبلومة PG في تخصص تطوير البرمجيات في برنامج البيانات الضخمة المصمم للمهنيين العاملين ويوفر أكثر من 7 دراسات حالة ومشاريع ، ويغطي 14 لغة وأدوات برمجة ، وتدريب عملي عملي ورش العمل ، أكثر من 400 ساعة من التعلم الصارم والمساعدة في التوظيف مع الشركات الكبرى.
تعلم شهادات هندسة البرمجيات عبر الإنترنت من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.