ビッグデータ:ツールとテクノロジーを知っている必要があります
公開: 2018-03-09また、ビッグデータを有効に活用することで、ドメインや業界(名前を付けるだけです!)がどのように運用を改善できるかを見ました。 組織はこの事実に気づき、適切な人々を乗せ、適切なツールとテクノロジーを備え、ビッグデータを理解しようとしています。
ますます多くの組織がこの事実に目覚めるにつれて、データサイエンス市場はますます急速に成長しています。 誰もがこのパイの一部を望んでいます。これにより、ビッグデータツールとテクノロジーが大幅に成長しました。
YouTubeのビデオを見る。
この記事では、ビッグデータの時流に乗るときにツールキットに含める必要のある適切なツールとテクノロジーについて説明します。 これらのツールに精通していると、今後直面する可能性のある面接にも役立ちます。
目次
Hadoopエコシステム
部屋の中の象に言及せずにビッグデータについて話すことはできません(しゃれを意図しています!)–Hadoop。 「高可用性分散オブジェクト指向プラットフォーム」の頭字語であるHadoopは、基本的に、大規模なデータセットの維持、自己修復、エラー処理、および保護に使用されるフレームワークです。 ただし、何年にもわたって、Hadoopは関連ツールのエコシステム全体を網羅してきました。 それだけでなく、ほとんどの商用ビッグデータソリューションはHadoopに基づいています。

典型的なHadoopプラットフォームスタックは、HDFS、Hive、HBase、およびPigで構成されています。
HDFS
これは、Hadoop分散ファイルシステムの略です。 これは、Hadoopのファイルストレージシステムと考えることができます。 HDFSは、大規模なデータセットの配布と保存を扱います。

MapReduce
MapReduceを使用すると、大量のデータセットを迅速に並行して処理できます。 それは単純な考えに従います。非常に短い時間で大量のデータを処理するには、仕事により多くの労働者を雇用するだけです。 典型的なMapReduceジョブは、MapとReduceの2つのフェーズで処理されます。 「Map」フェーズは、処理のためのクエリをHadoopクラスター内のさまざまなノードに送信し、「Reduce」フェーズはすべての結果を収集して単一の値に出力します。 MapReduceは、ジョブのスケジューリング、ジョブの監視、および失敗したタスクの再実行を処理します。
ハイブ
Hiveは、クエリ言語をMapReduceコマンドに変換するデータウェアハウスツールです。 それはFacebookによって始められました。 Hiveを使用することの最大の利点は、Hiveが従来のSQLと同様の構文を持つHQL(Hiveクエリ言語)を使用するため、開発者が既存のSQL知識を使用できることです。
HBase
HBaseは、非構造化データをリアルタイムで処理し、Hadoop上で実行される列指向のDBMSです。 SQLは構造化データを処理しないため、HBaseでのクエリには使用できません。 そのためには、Javaが優先言語です。 HBaseは、大規模なデータセットをリアルタイムで読み書きするのに非常に効率的です。
豚
Pigは、Yahoo!によって開始された高レベルの手続き型プログラミング言語です。 そして2007年にオープンソースになりました。奇妙に聞こえるかもしれませんが、Pigと呼ばれるのは、スローするあらゆるタイプのデータを処理できるからです。
スパーク
Apache Sparkは、ビッグデータ処理用の最速のエンジンであるため、このリストで特筆に値します。 これは、Amazon、Yahoo!、eBay、Flipkartなどの主要なプレーヤーによって使用されています。 Sparkを利用しているすべての組織を見てください。そうすれば、あなたは驚かれることでしょう。
Sparkは、メモリ内で最大100倍、ディスク上で10倍高速なプログラムを実行できるため、多くの点で古いHadoopを備えています。 
これは、 Hadoopが導入された意図を補完するものです。 大規模なデータセットを処理する場合、主要な懸念事項の1つは処理速度であるため、各クエリの実行間の待機時間を短縮する必要がありました。 そして、Sparkはまさにそれを実現します。ストリーミング、グラフ処理、機械学習、SQLサポートのための組み込みモジュールのおかげです。 また、最も一般的なプログラミング言語であるJava、Python、Scalaもサポートしています。

Sparkの導入の背後にある主な動機は、Hadoopの計算プロセスを高速化することでした。 ただし、後者の拡張と見なすべきではありません。 実際、SparkはHadoopを2つの主な目的(ストレージと処理)にのみ使用します。 それ以外は、かなりスタンドアロンのツールです。
NoSQL
従来のデータベース(RDBMS)は、行と列を定義することにより、構造化された方法で情報を格納します。 保存されているデータは非構造化または半構造化されていないため、そこで可能です。 しかし、ビッグデータの取り扱いについて話すときは、主に非構造化データセットについて話します。 このようなデータセットでは、 S (構造)がここに存在しないため、SQLを使用したクエリは機能しません。 したがって、これに対処するために、NoSQLデータベースがあります。

NoSQLデータベースは、非構造化データの保存に特化し、データをすばやく取得できるように構築されています。 ただし、これらは従来のデータベースと同じレベルの一貫性を提供しません。そのためにそれらを非難することはできません。データを非難します。
最も人気のあるNoSQLデータベースには、MongoDB、Cassandra、Redis、Couchbaseなどがあります。 主要なRDBMSベンダーであるOracleとIBMでさえ、その使用量が急速に増加していることを確認した後、現在NoSQLデータベースを提供しています。
データレイク
データレイクは、過去2年間、使用量が継続的に増加しています。 ただし、多くの人々は、データレイクはデータウェアハウスを再検討しただけだと考えていますが、そうではありません。 2つの間の唯一の類似点は、両方がデータストレージリポジトリであるということです。 率直に言って、それだけです。 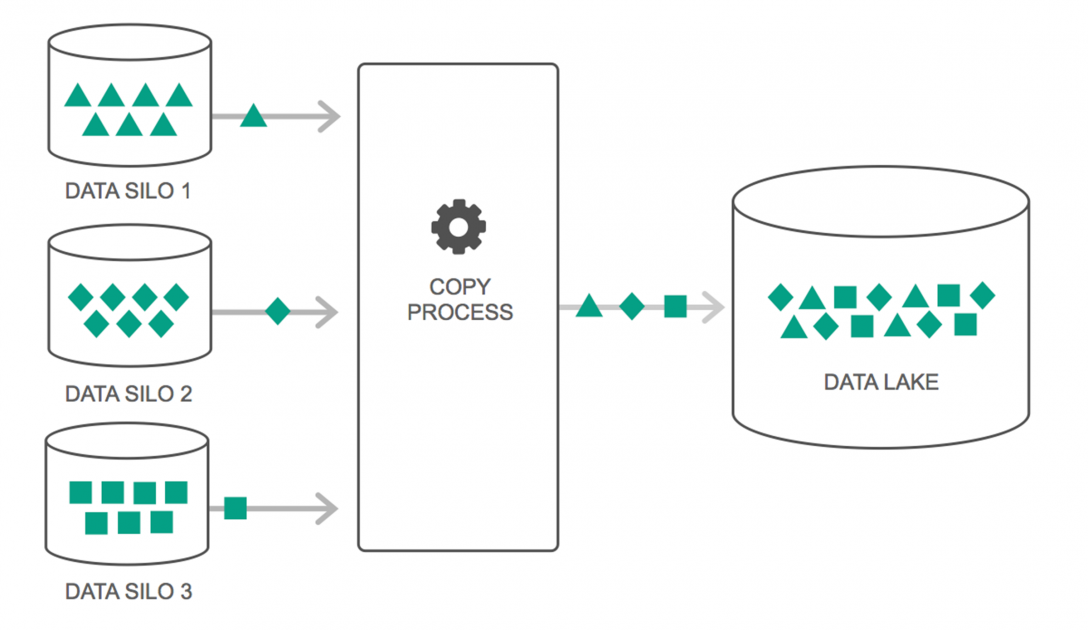
データレイクは、必要になるまで、さまざまなソースからの大量の生データをさまざまな形式で保持するストレージリポジトリとして定義できます。 データウェアハウスはデータを階層フォルダー構造に格納することに注意する必要がありますが、データレイクの場合はそうではありません。 データレイクは、フラットアーキテクチャを使用してデータセットを保存します。
多くの企業は、ビッグデータへのアクセス処理を簡素化するためにデータレイクに切り替えています。 データレイクは、保存する前にデータを処理するデータウェアハウスとは異なり、収集されたデータを自然な状態で保存します。 そのため、「湖」と「倉庫」の比喩が適切です。 データを水と見なす場合、データレイクは水湖と考えることができます。つまり、ろ過されていない自然な形で水を保管し、データウェアハウスはボトルに保管されて棚に保管されている水と考えることができます。

インメモリデータベース
どのコンピュータシステムでも、RAMまたはランダムアクセスメモリが処理の高速化を担っています。 同様の哲学を使用して、システムをデータに移動する代わりに、データをシステムに移動できるように、インメモリデータベースが開発されました。 つまり、データをメモリに保存すると、処理時間が大幅に短縮されます。 すべてのデータがメモリ内にあるため、データのフェッチと取得はもう面倒ではありません。
ただし、実際には、非常に大きなデータセットを処理している場合、すべてをメモリ内に取得することはできません。 ただし、その一部をメモリ内に保持して処理し、別の部分をメモリ内に移動してさらに処理することができます。 これを支援するために、Hadoopは、処理を高速化するためのオンディスクデータベースとインメモリデータベースの両方を含むいくつかのツールを提供します。
まとめ…
この記事で提供されるリストは、決して「ビッグデータツールとテクノロジーの包括的なリスト」ではありません。 代わりに、「知っておくべき」ビッグデータツールとテクノロジーに焦点を当てています。 ビッグデータの分野は絶えず進化しており、新しいテクノロジーは古いテクノロジーよりも急速に時代遅れになっています。 Finch、Kafka、Nifi、Samzaなど、Hadoop-Sparkスタック以外にも多くのテクノロジーがあります。 これらのツールは、問題のないシームレスな結果を提供します。 これらにはそれぞれ固有のユースケースがありますが、それらのいずれかに取り組む前に、記事で言及したものを知っておくことが重要です。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。
世界のトップ大学からオンラインでソフトウェアエンジニアリングの学位を学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。