Big Data: herramientas y tecnologías imprescindibles
Publicado: 2018-03-09También vimos cómo cualquier dominio o industria (¡simplemente nómbralo!) podría mejorar sus operaciones al hacer un buen uso de Big Data . Las organizaciones se están dando cuenta de este hecho y están tratando de incorporar al grupo adecuado de personas, blindarlos con el conjunto correcto de herramientas y tecnologías, y dar sentido a su Big Data .
A medida que más y más organizaciones se dan cuenta de este hecho, el mercado de la ciencia de datos crece más rápidamente. Todo el mundo quiere un trozo de este pastel, lo que ha dado lugar a un crecimiento masivo de las herramientas y tecnologías de big data.
Ver vídeo de youtube.
En este artículo, hablaremos sobre las herramientas y tecnologías correctas que debe tener en su kit de herramientas a medida que se sube al carro de big data. La familiaridad con estas herramientas también lo ayudará en las próximas entrevistas que pueda enfrentar.
Tabla de contenido
Ecosistema Hadoop
Es imposible hablar de Big Data sin mencionar al elefante en la habitación (¡juego de palabras!): Hadoop. Acrónimo de 'plataforma orientada a objetos distribuidos de alta disponibilidad', Hadoop es esencialmente un marco utilizado para el mantenimiento, la reparación automática, el manejo de errores y la seguridad de grandes conjuntos de datos. Sin embargo, a lo largo de los años, Hadoop ha abarcado todo un ecosistema de herramientas relacionadas . No solo eso, la mayoría de las soluciones comerciales de Big Data se basan en Hadoop.

Una pila típica de la plataforma Hadoop consta de HDFS, Hive, HBase y Pig.
HDFS
Son las siglas de Hadoop Distributed Filesystem. Se puede considerar como el sistema de almacenamiento de archivos para Hadoop. HDFS se ocupa de la distribución y el almacenamiento de grandes conjuntos de datos.

Mapa reducido
MapReduce permite que conjuntos de datos masivos se procesen rápidamente en paralelo. Sigue una idea simple: para manejar una gran cantidad de datos en muy poco tiempo, simplemente contrate a más trabajadores para el trabajo. Un trabajo típico de MapReduce se procesa en dos fases: Map y Reduce. La fase de "Mapa" envía una consulta para su procesamiento a varios nodos en un clúster de Hadoop, y la fase de "Reducir" recopila todos los resultados para generar un solo valor. MapReduce se encarga de programar trabajos, monitorear trabajos y volver a ejecutar la tarea fallida.
Colmena
Hive es una herramienta de almacenamiento de datos que convierte el lenguaje de consulta en comandos de MapReduce. Fue iniciado por Facebook. La mejor parte de usar Hive es que los desarrolladores pueden usar su conocimiento SQL existente ya que Hive usa HQL (Lenguaje de consulta de Hive) que tiene una sintaxis similar al SQL clásico.
HBase
HBase es un DBMS orientado a columnas que trata con datos no estructurados en tiempo real y se ejecuta sobre Hadoop. SQL no se puede usar para consultar en HBase ya que no trata con datos estructurados. Para eso, Java es el lenguaje preferido. HBase es extremadamente eficiente en la lectura y escritura de grandes conjuntos de datos en tiempo real.
Cerdo
Pig es un lenguaje de programación procedimental de alto nivel iniciado por Yahoo! Y se convirtió en código abierto en 2007. Por extraño que parezca, se llama Pig porque puede manejar cualquier tipo de datos que le arrojes.
Chispa - chispear
Apache Spark merece una mención especial en esta lista, ya que es el motor más rápido para el procesamiento de Big Data . Lo utilizan los principales jugadores, incluidos Amazon, Yahoo!, eBay y Flipkart. Eche un vistazo a todas las organizaciones que funcionan con Spark, ¡y quedará impresionado!
En muchos sentidos, Spark ha obsoleto a Hadoop, ya que le permite ejecutar programas hasta cien veces más rápido en la memoria y diez veces más rápido en el disco. 
Complementa las intenciones con las que se introdujo Hadoop . Cuando se trata de grandes conjuntos de datos, una de las principales preocupaciones es la velocidad de procesamiento, por lo que era necesario disminuir el tiempo de espera entre la ejecución de cada consulta. Y Spark hace exactamente eso, gracias a sus módulos integrados para transmisión, procesamiento de gráficos, aprendizaje automático y compatibilidad con SQL. También es compatible con los lenguajes de programación más comunes: Java, Python y Scala.

El motivo principal detrás de la introducción de Spark fue acelerar los procesos computacionales de Hadoop. Sin embargo, no debe verse como una extensión de este último. De hecho, Spark usa Hadoop solo para dos propósitos principales: almacenamiento y procesamiento. Aparte de eso, es una herramienta bastante independiente.
No SQL
Las bases de datos tradicionales (RDBMS) almacenan información de forma estructurada definiendo filas y columnas. Es posible allí porque los datos que se almacenan no están estructurados ni semiestructurados. Pero cuando hablamos de manejar Big Data , estamos hablando de conjuntos de datos en gran parte no estructurados. En dichos conjuntos de datos, la consulta mediante SQL no funcionará porque la S (estructura) no existe aquí. Entonces, para lidiar con eso, tenemos bases de datos NoSQL.

Las bases de datos NoSQL están diseñadas para especializarse en el almacenamiento de datos no estructurados y proporcionar recuperaciones de datos rápidas. Sin embargo, no brindan el mismo nivel de consistencia que las bases de datos tradicionales; no puede culparlos por eso, ¡culpe a los datos!
Las bases de datos NoSQL más populares incluyen MongoDB, Cassandra, Redis y Couchbase. Incluso Oracle e IBM, los principales proveedores de RDBMS, ahora ofrecen bases de datos NoSQL, después de ver el rápido crecimiento de su uso.
Lagos de datos
Los lagos de datos han experimentado un aumento continuo en su uso durante los últimos años. Sin embargo, mucha gente todavía piensa que los lagos de datos son solo una revisión del almacén de datos, pero eso no es cierto. La única similitud entre los dos es que ambos son repositorios de almacenamiento de datos. Francamente, eso es todo. 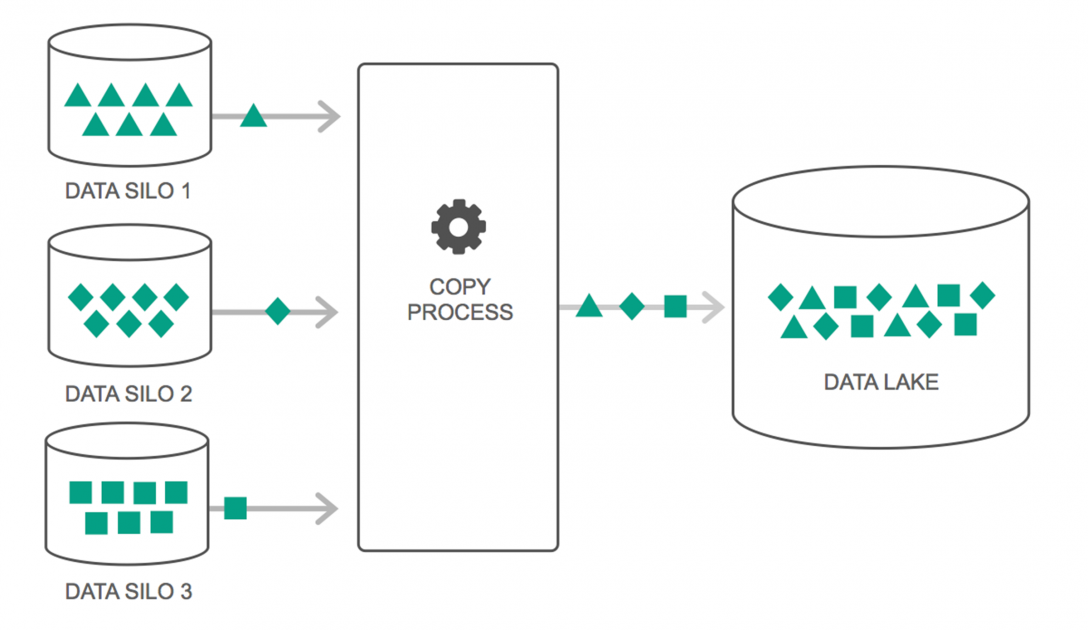
Un lago de datos se puede definir como un depósito de almacenamiento que contiene una gran cantidad de datos sin procesar de una variedad de fuentes, en una variedad de formatos, hasta que se necesita. Debe tener en cuenta que los almacenes de datos almacenan los datos en una estructura de carpetas jerárquica, pero ese no es el caso con los lagos de datos. Los lagos de datos utilizan una arquitectura plana para guardar los conjuntos de datos.
Muchas empresas se están cambiando a Data Lakes para simplificar el procesamiento de acceso a sus Big Data . Los lagos de datos almacenan los datos recopilados en su estado natural, a diferencia de un almacén de datos que procesa los datos antes de almacenarlos. Por eso es adecuada la metáfora del “lago” y el “almacén”. Si ve los datos como agua, puede pensar en un lago de datos como un lago de agua: almacena agua sin filtrar y en su forma natural, y puede pensar en un almacén de datos como agua almacenada en botellas y almacenada en un estante.

Bases de datos en memoria
En cualquier sistema informático, la RAM, o Memoria de Acceso Aleatorio, es la encargada de acelerar el procesamiento. Usando una filosofía similar, se desarrollaron bases de datos en memoria para que pueda mover sus datos a su sistema, en lugar de llevar su sistema a los datos. Lo que eso significa esencialmente es que si almacena datos en la memoria, reducirá el tiempo de procesamiento por un margen considerable. La obtención y recuperación de datos ya no será una molestia, ya que todos los datos estarán en la memoria.
Pero en la práctica, si está manejando un conjunto de datos realmente grande, no es posible tenerlo todo en la memoria. Sin embargo, puede mantener una parte en la memoria, procesarla y luego traer otra parte a la memoria para su posterior procesamiento. Para ayudar con eso, Hadoop proporciona varias herramientas que contienen bases de datos tanto en disco como en memoria para acelerar el procesamiento.
Terminando…
La lista proporcionada en este artículo no es de ninguna manera una "lista completa de herramientas y tecnologías de Big Data ". En su lugar, se centra en las herramientas y tecnologías de Big Data "imprescindibles" . El campo de Big Data está en constante evolución y las nuevas tecnologías están desactualizando a las antiguas muy rápidamente. Hay muchas más tecnologías más allá de la pila de Hadoop-Spark, como Finch, Kafka, Nifi, Samza y más. Estas herramientas brindan resultados perfectos sin contratiempos. Cada uno de estos tiene sus casos de uso específicos, pero antes de comenzar a trabajar en cualquiera de ellos, es importante conocer los que mencionamos en el artículo.
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.
Aprenda títulos de ingeniería de software en línea de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.