大數據:必須了解的工具和技術
已發表: 2018-03-09我們還看到了任何領域或行業(您只需說出它的名字!)如何通過充分利用大數據來改善其運營。 組織正在意識到這一事實,並試圖讓合適的人加入,用正確的工具和技術來武裝他們,並理解他們的大數據。
隨著越來越多的組織意識到這一事實,數據科學市場正在以更快的速度增長。 每個人都想分一杯羹——這導致了大數據工具和技術的巨大增長。
觀看 youtube 視頻。
在本文中,我們將討論當您加入大數據潮流時,您的工具包中應該擁有的正確工具和技術。 熟悉這些工具也將有助於您即將面臨的任何面試。
目錄
Hadoop生態系統
談到大數據,你不可能不提到房間裡的大象(雙關語!)——Hadoop。 Hadoop 是“高可用性分佈式面向對象平台”的首字母縮寫詞,本質上是一個用於維護、自我修復、錯誤處理和保護大型數據集的框架。 然而,多年來,Hadoop 已經涵蓋了相關工具的整個生態系統。 不僅如此,大多數商業大數據解決方案都基於 Hadoop。

典型的 Hadoop 平台堆棧由 HDFS、Hive、HBase 和 Pig 組成。
高密度文件系統
它代表 Hadoop 分佈式文件系統。 它可以被認為是 Hadoop 的文件存儲系統。 HDFS 處理大型數據集的分發和存儲。

MapReduce
MapReduce 允許並行快速處理大量數據集。 它遵循一個簡單的想法——在很短的時間內處理大量數據,只需僱用更多的工人來完成這項工作。 典型的 MapReduce 作業分兩個階段處理:Map 和 Reduce。 “Map”階段向 Hadoop 集群中的各個節點發送查詢以進行處理,“Reduce”階段收集所有結果以輸出為單個值。 MapReduce 負責調度作業、監視作業和重新執行失敗的任務。
蜂巢
Hive 是一種數據倉庫工具,可將查詢語言轉換為 MapReduce 命令。 它是由 Facebook 發起的。 使用 Hive 最好的部分是開發人員可以使用他們現有的 SQL 知識,因為 Hive 使用 HQL(Hive 查詢語言),其語法類似於經典 SQL。
HBase
HBase 是一種面向列的 DBMS,它實時處理非結構化數據並運行在 Hadoop 之上。 SQL 不能用於在 HBase 上進行查詢,因為它不處理結構化數據。 為此,Java 是首選語言。 HBase 在實時讀取和寫入大型數據集方面非常高效。
豬
Pig 是由 Yahoo! 發起的高級過程編程語言。 並於 2007 年成為開源軟件。雖然聽起來很奇怪,但它之所以被稱為 Pig,是因為它可以處理你扔給它的任何類型的數據!
火花
Apache Spark 在此列表中值得特別提及,因為它是最快的大數據處理引擎。 它已被包括亞馬遜、雅虎、eBay 和 Flipkart 在內的主要參與者使用。 看看所有由 Spark 提供支持的組織,你會被震撼到!
Spark 在許多方面已經過時了 Hadoop,因為它可以讓您在內存中運行程序的速度提高一百倍,在磁盤上運行速度提高十倍。 
它補充了引入Hadoop的意圖。 在處理大型數據集時,主要關注點之一是處理速度,因此需要減少每個查詢執行之間的等待時間。 而 Spark 正是這樣做的——這要歸功於其用於流式處理、圖形處理、機器學習和 SQL 支持的內置模塊。 它還支持最常見的編程語言——Java、Python 和 Scala。

引入 Spark 的主要動機是加速 Hadoop 的計算過程。 但是,不應將其視為後者的延伸。 事實上,Spark 僅將 Hadoop 用於兩個主要目的——存儲和處理。 除此之外,它是一個非常獨立的工具。
NoSQL
傳統數據庫 (RDBMS) 通過定義行和列以結構化方式存儲信息。 這是可能的,因為存儲的數據不是非結構化或半結構化的。 但是當我們談論處理大數據時,我們談論的主要是非結構化數據集。 在這樣的數據集中,使用 SQL 查詢是行不通的,因為這裡不存在S (結構)。 所以,為了解決這個問題,我們有 NoSQL 數據庫。

NoSQL 數據庫專門用於存儲非結構化數據並提供快速數據檢索。 但是,它們不能提供與傳統數據庫相同級別的一致性——這不能怪他們,要怪數據!
最流行的 NoSQL 數據庫包括 MongoDB、Cassandra、Redis 和 Couchbase。 即使是領先的 RDBMS 供應商 Oracle 和 IBM,在看到 NoSQL 數據庫的使用量快速增長後,現在也提供 NoSQL 數據庫。
數據湖
在過去的幾年中,數據湖的使用量持續上升。 然而,很多人仍然認為數據湖只是重新審視數據倉庫——但事實並非如此。 兩者之間唯一的相似之處在於它們都是數據存儲庫。 坦白說,就是這樣。 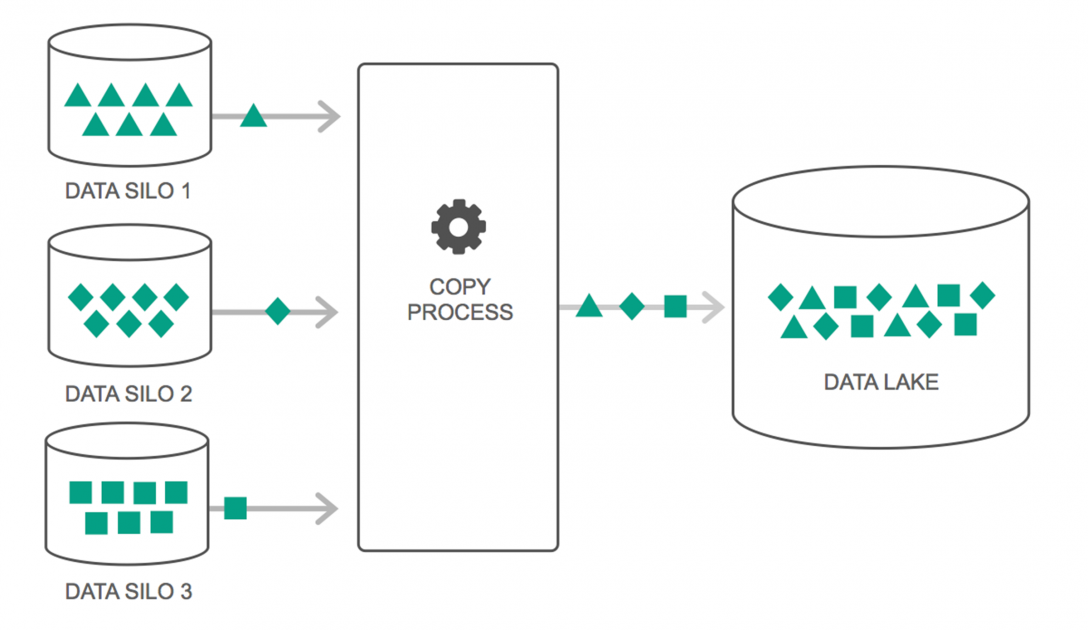
數據湖可以定義為一個存儲庫,它包含來自各種來源、各種格式的大量原始數據,直到需要為止。 您必須知道,數據倉庫將數據存儲在分層文件夾結構中,但數據湖並非如此。 數據湖使用平面架構來保存數據集。
許多企業正在轉向數據湖以簡化訪問其大數據的處理。 數據湖以自然狀態存儲收集到的數據,這與在存儲之前處理數據的數據倉庫不同。 這就是為什麼“湖”和“倉庫”的比喻是恰當的。 如果您將數據視為水,那麼數據湖可以被認為是水湖——以自然形式存儲未經過濾的水,而數據倉庫可以被認為是存儲在瓶中並保存在架子上的水。

內存數據庫
在任何計算機系統中,RAM 或隨機存取存儲器負責加快處理速度。 使用類似的理念,開發了內存數據庫,以便您可以將數據移動到系統中,而不是將系統帶到數據中。 這實質上意味著如果您將數據存儲在內存中,它將大大減少處理時間。 數據獲取和檢索將不再是一件痛苦的事,因為所有數據都將在內存中。
但實際上,如果您正在處理一個非常大的數據集,則不可能將其全部存儲在內存中。 但是,您可以將其中的一部分保留在內存中,對其進行處理,然後將另一部分放入內存中以進行進一步處理。 為了解決這個問題,Hadoop 提供了幾個包含磁盤和內存數據庫的工具,以加快處理速度。
包起來…
本文提供的列表絕不是“大數據工具和技術的綜合列表”。 相反,它專注於“必須知道”的大數據工具和技術。 大數據領域不斷發展,新技術很快就過時了。 除了 Hadoop-Spark 堆棧之外,還有更多技術,例如 Finch、Kafka、Nifi、Samza 等。 這些工具提供無縫的結果,沒有打嗝。 其中每一個都有其特定的用例,但在你開始使用它們之前,了解我們在文章中提到的那些是很重要的。
如果您有興趣了解有關大數據的更多信息,請查看我們的 PG 大數據軟件開發專業文憑課程,該課程專為在職專業人士設計,提供 7 多個案例研究和項目,涵蓋 14 種編程語言和工具,實用的動手操作研討會,超過 400 小時的嚴格學習和頂級公司的就業幫助。
從世界頂級大學在線學習軟件工程學位。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。