大数据:必须了解的工具和技术
已发表: 2018-03-09我们还看到了任何领域或行业(您只需说出它的名字!)如何通过充分利用大数据来改善其运营。 组织正在意识到这一事实,并试图招募合适的人员,用正确的工具和技术集武装他们,并理解他们的大数据。
随着越来越多的组织意识到这一事实,数据科学市场正在以更快的速度增长。 每个人都想分一杯羹——这导致了大数据工具和技术的巨大增长。
观看 youtube 视频。
在本文中,我们将讨论当您加入大数据潮流时,您的工具包中应该拥有的正确工具和技术。 熟悉这些工具也将有助于您即将面临的任何面试。
目录
Hadoop生态系统
谈到大数据,你不可能不提到房间里的大象(双关语!)——Hadoop。 Hadoop 是“高可用性分布式面向对象平台”的首字母缩写词,本质上是一个用于维护、自我修复、错误处理和保护大型数据集的框架。 然而,多年来,Hadoop 已经涵盖了相关工具的整个生态系统。 不仅如此,大多数商业大数据解决方案都基于 Hadoop。

典型的 Hadoop 平台堆栈由 HDFS、Hive、HBase 和 Pig 组成。
高密度文件系统
它代表 Hadoop 分布式文件系统。 它可以被认为是 Hadoop 的文件存储系统。 HDFS 处理大型数据集的分发和存储。

MapReduce
MapReduce 允许并行快速处理大量数据集。 它遵循一个简单的想法——在很短的时间内处理大量数据,只需雇用更多的工人来完成这项工作。 典型的 MapReduce 作业分两个阶段处理:Map 和 Reduce。 “Map”阶段向 Hadoop 集群中的各个节点发送查询以进行处理,“Reduce”阶段收集所有结果以输出为单个值。 MapReduce 负责调度作业、监视作业和重新执行失败的任务。
蜂巢
Hive 是一种数据仓库工具,可将查询语言转换为 MapReduce 命令。 它是由 Facebook 发起的。 使用 Hive 最好的部分是开发人员可以使用他们现有的 SQL 知识,因为 Hive 使用 HQL(Hive 查询语言),其语法类似于经典 SQL。
HBase
HBase 是一种面向列的 DBMS,它实时处理非结构化数据并运行在 Hadoop 之上。 SQL 不能用于在 HBase 上进行查询,因为它不处理结构化数据。 为此,Java 是首选语言。 HBase 在实时读取和写入大型数据集方面非常高效。
猪
Pig 是由 Yahoo! 发起的高级过程编程语言。 并于 2007 年成为开源软件。虽然听起来很奇怪,但它之所以被称为 Pig,是因为它可以处理你扔给它的任何类型的数据!
火花
Apache Spark 在此列表中值得特别提及,因为它是最快的大数据处理引擎。 它已被包括亚马逊、雅虎、eBay 和 Flipkart 在内的主要参与者使用。 看看所有由 Spark 提供支持的组织,你会被震撼到!
Spark 在许多方面已经过时了 Hadoop,因为它可以让您在内存中运行程序的速度提高一百倍,在磁盘上运行速度提高十倍。 
它补充了引入Hadoop的意图。 在处理大型数据集时,主要关注点之一是处理速度,因此需要减少每个查询执行之间的等待时间。 而 Spark 正是这样做的——这要归功于其用于流式处理、图形处理、机器学习和 SQL 支持的内置模块。 它还支持最常见的编程语言——Java、Python 和 Scala。

引入 Spark 的主要动机是加速 Hadoop 的计算过程。 但是,不应将其视为后者的延伸。 事实上,Spark 仅将 Hadoop 用于两个主要目的——存储和处理。 除此之外,它是一个非常独立的工具。
NoSQL
传统数据库 (RDBMS) 通过定义行和列以结构化方式存储信息。 这是可能的,因为存储的数据不是非结构化或半结构化的。 但是当我们谈论处理大数据时,我们谈论的主要是非结构化数据集。 在这样的数据集中,使用 SQL 查询是行不通的,因为这里不存在S (结构)。 所以,为了解决这个问题,我们有 NoSQL 数据库。

NoSQL 数据库专门用于存储非结构化数据并提供快速数据检索。 但是,它们不能提供与传统数据库相同级别的一致性——这不能怪他们,要怪数据!
最流行的 NoSQL 数据库包括 MongoDB、Cassandra、Redis 和 Couchbase。 即使是领先的 RDBMS 供应商 Oracle 和 IBM,在看到 NoSQL 数据库的使用量快速增长后,现在也提供 NoSQL 数据库。
数据湖
在过去的几年中,数据湖的使用量持续上升。 然而,很多人仍然认为数据湖只是重新审视数据仓库——但事实并非如此。 两者之间唯一的相似之处在于它们都是数据存储库。 坦白说,就是这样。 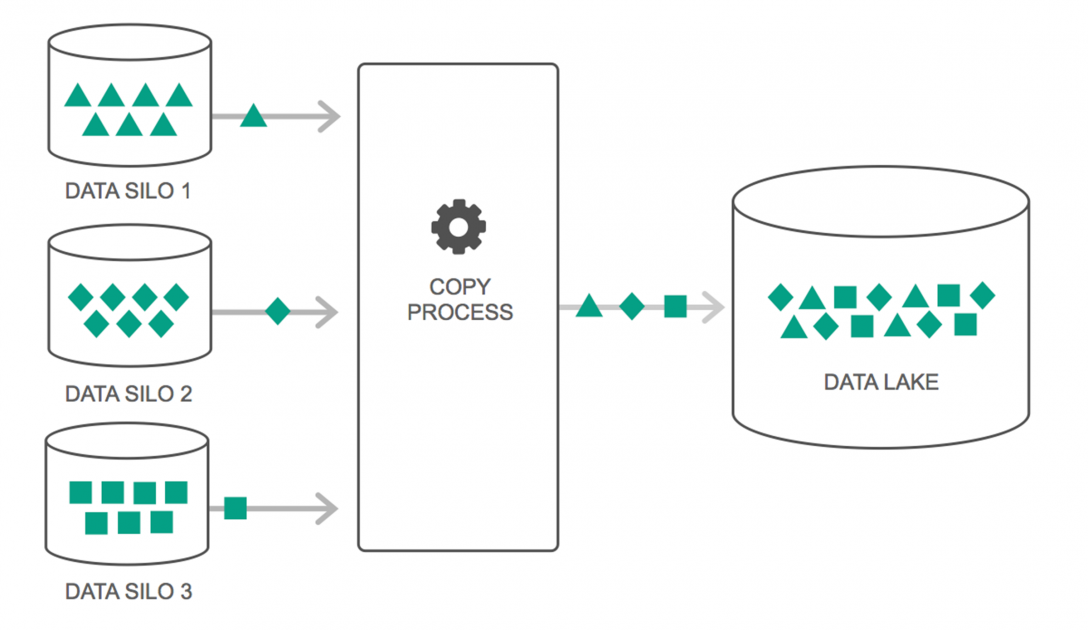
数据湖可以定义为一个存储库,它包含来自各种来源、各种格式的大量原始数据,直到需要为止。 您必须知道,数据仓库将数据存储在分层文件夹结构中,但数据湖并非如此。 数据湖使用平面架构来保存数据集。
许多企业正在转向数据湖以简化访问其大数据的处理。 数据湖以自然状态存储收集到的数据,这与在存储之前处理数据的数据仓库不同。 这就是为什么“湖”和“仓库”的比喻是恰当的。 如果您将数据视为水,那么数据湖可以被认为是水湖——以自然形式存储未经过滤的水,而数据仓库可以被认为是存储在瓶中并保存在架子上的水。

内存数据库
在任何计算机系统中,RAM 或随机存取存储器负责加快处理速度。 使用类似的理念,开发了内存数据库,以便您可以将数据移动到系统中,而不是将系统带到数据中。 这实质上意味着如果您将数据存储在内存中,它将大大减少处理时间。 数据获取和检索将不再是一件痛苦的事,因为所有数据都将在内存中。
但实际上,如果您正在处理一个非常大的数据集,则不可能将其全部存储在内存中。 但是,您可以将其中的一部分保留在内存中,对其进行处理,然后将另一部分放入内存中以进行进一步处理。 为了解决这个问题,Hadoop 提供了几个包含磁盘和内存数据库的工具,以加快处理速度。
包起来…
本文提供的列表绝不是“大数据工具和技术的综合列表”。 相反,它专注于“必须知道”的大数据工具和技术。 大数据领域不断发展,新技术很快就过时了。 除了 Hadoop-Spark 堆栈之外,还有更多技术,例如 Finch、Kafka、Nifi、Samza 等。 这些工具提供无缝的结果,没有打嗝。 其中每一个都有其特定的用例,但在你开始使用它们之前,了解我们在文章中提到的那些是很重要的。
如果您有兴趣了解有关大数据的更多信息,请查看我们的 PG 大数据软件开发专业文凭课程,该课程专为在职专业人士设计,提供 7 多个案例研究和项目,涵盖 14 种编程语言和工具,实用的动手操作研讨会,超过 400 小时的严格学习和顶级公司的就业帮助。
从世界顶级大学在线学习软件工程学位。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。