Big Data: trebuie să cunoașteți instrumentele și tehnologiile
Publicat: 2018-03-09Am văzut, de asemenea, cum orice domeniu sau industrie (doar să-l numești!) și-ar putea îmbunătăți operațiunile prin folosirea Big Data . Organizațiile își dau seama de acest fapt și încearcă să integreze setul potrivit de oameni, să-i blindeze cu setul corect de instrumente și tehnologii și să dea sens Big Data .
Pe măsură ce tot mai multe organizații se trezesc la acest fapt, piața Data Science crește și mai rapid alături. Toată lumea își dorește o bucată din această plăcintă – ceea ce a dus la o creștere masivă a instrumentelor și tehnologiilor de date mari.
Urmăriți videoclipul de pe youtube.
În acest articol, vom vorbi despre instrumentele și tehnologiile potrivite pe care ar trebui să le aveți în setul dvs. de instrumente în timp ce veți sări în valul de date mari. Familiarizarea cu aceste instrumente vă va ajuta, de asemenea, la orice interviuri viitoare cu care vă puteți confrunta.
Cuprins
Ecosistemul Hadoop
Nu poți vorbi despre Big Data fără a menționa elefantul din cameră (joc de cuvinte!) – Hadoop. Un acronim pentru „Platformă orientată pe obiecte distribuite de înaltă disponibilitate”, Hadoop este, în esență, un cadru utilizat pentru întreținerea, auto-vindecarea, gestionarea erorilor și securizarea seturi de date mari. Cu toate acestea, de-a lungul anilor, Hadoop a cuprins un întreg ecosistem de instrumente conexe . Nu numai atât, majoritatea soluțiilor comerciale de Big Data se bazează pe Hadoop.

O stivă tipică de platformă Hadoop constă din HDFS, Hive, HBase și Pig.
HDFS
Aceasta înseamnă Hadoop Distributed Filesystem. Poate fi considerat ca fiind sistemul de stocare a fișierelor pentru Hadoop. HDFS se ocupă cu distribuția și stocarea seturilor mari de date.

MapReduce
MapReduce permite procesarea rapidă în paralel a unor seturi masive de date. Urmează o idee simplă - pentru a trata o mulțime de date într-un timp foarte scurt, pur și simplu angajați mai mulți lucrători pentru acest loc de muncă. O lucrare tipică MapReduce este procesată în două faze: Mapă și Reduce. Faza „Hartă” trimite o interogare pentru procesare către diferite noduri dintr-un cluster Hadoop, iar faza „Reducere” colectează toate rezultatele pentru a le scoate într-o singură valoare. MapReduce se ocupă de programarea sarcinilor, de monitorizarea lucrărilor și de reexecutarea sarcinii eșuate.
Stup
Hive este un instrument de depozitare a datelor care convertește limbajul de interogare în comenzi MapReduce. A fost inițiat de Facebook. Cea mai bună parte a utilizării Hive este că dezvoltatorii își pot folosi cunoștințele SQL existente, deoarece Hive utilizează HQL (Hive Query Language) care are o sintaxă similară cu SQL-ul clasic.
HBase
HBase este un SGBD orientat pe coloane care se ocupă de date nestructurate în timp real și rulează pe Hadoop. SQL nu poate fi folosit pentru a interoga pe HBase, deoarece nu se ocupă de date structurate. Pentru asta, Java este limbajul preferat. HBase este extrem de eficient în citirea și scrierea de seturi mari de date în timp real.
Porc
Pig este un limbaj de programare procedural de nivel înalt care a fost inițiat de Yahoo! Și a devenit open source în 2007. Oricât de ciudat ar suna, se numește Pig pentru că poate gestiona orice tip de date pe care îi arunci!
Scânteie
Apache Spark merită o mențiune specială pe această listă, deoarece este cel mai rapid motor pentru procesarea Big Data . Este folosit de jucători importanți, inclusiv Amazon, Yahoo!, eBay și Flipkart. Aruncă o privire la toate organizațiile care sunt alimentate de Spark și vei fi uluit!
Spark a depășit Hadoop în multe privințe, deoarece vă permite să rulați programe de până la o sută de ori mai rapid în memorie și de zece ori mai rapid pe disc. 
Acesta completează intențiile cu care a fost introdus Hadoop . Când aveți de-a face cu seturi mari de date, una dintre preocupările majore este viteza de procesare, așa că a fost nevoie să se diminueze timpul de așteptare dintre execuția fiecărei interogări. Și Spark face exact asta – datorită modulelor sale încorporate pentru streaming, procesare grafică, învățare automată și suport SQL. De asemenea, acceptă cele mai comune limbaje de programare – Java, Python și Scala.

Motivul principal din spatele introducerii Spark a fost accelerarea proceselor de calcul ale Hadoop. Cu toate acestea, nu trebuie privit ca o prelungire a acestuia din urmă. De fapt, Spark folosește Hadoop doar pentru două scopuri principale - stocare și procesare. În afară de asta, este un instrument destul de independent.
NoSQL
Bazele de date tradiționale (RDBMS) stochează informații într-un mod structurat prin definirea de rânduri și coloane. Este posibil acolo deoarece datele stocate nu sunt nestructurate sau semi-structurate. Dar când vorbim despre gestionarea Big Data , vorbim despre seturi de date în mare măsură nestructurate. În astfel de seturi de date, interogarea folosind SQL nu va funcționa, deoarece S (structura) nu există aici. Deci, pentru a face față cu asta, avem baze de date NoSQL.

Bazele de date NoSQL sunt construite pentru a se specializa în stocarea datelor nestructurate și pentru a oferi o recuperare rapidă a datelor. Cu toate acestea, ele nu oferă același nivel de consistență ca bazele de date tradiționale – nu le poți învinovăți pentru asta, da vina pe date!
Cele mai populare baze de date NoSQL includ MongoDB, Cassandra, Redis și Couchbase. Chiar și Oracle și IBM – principalii furnizori RDBMS – oferă acum baze de date NoSQL, după ce au văzut creșterea rapidă a utilizării acestora.
Data Lakes
Lacurile de date au cunoscut o creștere continuă a utilizării lor în ultimii doi ani. Cu toate acestea, mulți oameni încă mai cred că Data Lakes sunt doar revăzute Data Warehouse – dar nu este adevărat. Singura similitudine dintre cele două este că ambele sunt depozite de stocare a datelor. Sincer, asta este. 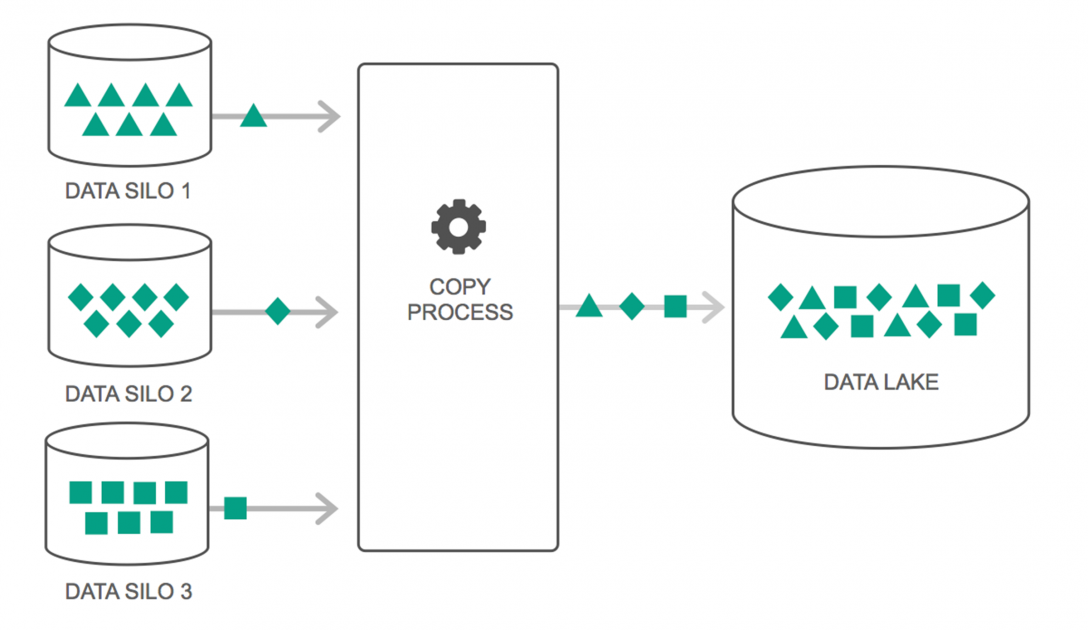
Un lac de date poate fi definit ca un depozit de stocare care deține o cantitate imensă de date brute dintr-o varietate de surse, într-o varietate de formate, până când este nevoie. Trebuie să știți că depozitele de date stochează datele într-o structură de foldere ierarhice, dar nu este cazul cu Data Lakes. Data Lakes utilizează o arhitectură plată pentru a salva seturile de date.
Multe companii trec la Data Lakes pentru a simplifica procesarea accesării Big Data . Data Lakes stochează datele colectate în starea lor naturală – spre deosebire de un depozit de date care prelucrează datele înainte de stocare. De aceea, metafora „lac” și „depozit” este potrivită. Dacă vedeți datele ca apă, un lac de date poate fi gândit ca un lac de apă - stocând apa nefiltrată și în forma ei naturală, iar un depozit de date poate fi gândit ca apă stocată în sticle și păstrată pe raft.

Baze de date în memorie
În orice sistem informatic, RAM sau memoria cu acces aleatoriu este responsabilă pentru accelerarea procesării. Folosind o filozofie similară, au fost dezvoltate baze de date în memorie, astfel încât să vă puteți muta datele în sistem, în loc să vă duceți sistemul la date. Ceea ce înseamnă în esență este că, dacă stocați date în memorie, timpul de procesare va reduce cu o marjă destul de mare. Preluarea și recuperarea datelor nu vor mai fi o durere, deoarece toate datele vor fi în memorie.
Dar practic, dacă manipulați un set de date foarte mare, nu este posibil să le obțineți pe toate în memorie. Cu toate acestea, puteți păstra o parte din acesta în memorie, o puteți procesa și apoi aduceți o altă parte în memorie pentru procesare ulterioară. Pentru a ajuta la aceasta, Hadoop oferă mai multe instrumente care conțin atât baze de date pe disc, cât și baze de date în memorie, pentru a accelera procesarea.
Încheierea…
Lista furnizată în acest articol nu este în niciun caz o „listă cuprinzătoare a instrumentelor și tehnologiilor Big Data ”. În schimb, se concentrează pe instrumentele și tehnologiile Big Data „trebuie să știe” . Domeniul Big Data este în continuă evoluție, iar noile tehnologii le depășesc foarte repede pe cele mai vechi. Există mult mai multe tehnologii dincolo de stiva Hadoop-Spark, cum ar fi Finch, Kafka, Nifi, Samza și multe altele. Aceste instrumente oferă rezultate perfecte fără sughiț. Fiecare dintre acestea are cazurile lor specifice de utilizare, dar înainte de a lucra la oricare dintre ele, este important să fii conștient de cele pe care le-am menționat în articol.
Dacă sunteți interesat să aflați mai multe despre Big Data, consultați programul nostru PG Diploma în Dezvoltare Software Specializare în Big Data, care este conceput pentru profesioniști care lucrează și oferă peste 7 studii de caz și proiecte, acoperă 14 limbaje și instrumente de programare, practică practică. ateliere de lucru, peste 400 de ore de învățare riguroasă și asistență pentru plasarea unui loc de muncă cu firme de top.
Învață diplome de Inginerie software online de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.