
รองรับ Vector Machine Algorithm ใน Machine Learning
เผยแพร่แล้ว: 2020-08-14ทุกสิ่งที่คุณจำเป็นต้องรู้เกี่ยวกับ Support Vector Machine Algorithms
ผู้เริ่มต้นส่วนใหญ่เมื่อพูดถึงแมชชีนเลิร์นนิง เริ่มต้นด้วย อัลกอริทึมการถดถอยและการจัดหมวดหมู่ อย่างเป็นธรรมชาติ อัลกอริทึมเหล่านี้เรียบง่ายและน่าติดตาม อย่างไรก็ตาม จำเป็นต้องก้าวไปไกลกว่าอัลกอริธึมแมชชีนเลิร์นนิงทั้งสองนี้ เพื่อให้เข้าใจแนวคิดของแมชชีนเลิร์นนิงได้ดีขึ้น
มีอะไรอีกมากให้เรียนรู้ในแมชชีนเลิร์นนิง ซึ่งอาจไม่ง่ายเหมือนการถดถอยและการจัดหมวดหมู่ แต่สามารถช่วยเราแก้ปัญหาที่ซับซ้อนต่างๆ ได้ ขอแนะนำให้คุณรู้จักกับอัลกอริธึมดังกล่าว นั่นคือ Support Vector Machine Algorithm รองรับอัลกอริธึม Vector Machine หรือ อัลกอริธึม SVM มักถูกเรียกว่าอัลกอริธึมการเรียนรู้ด้วยเครื่องหนึ่งที่สามารถให้ประสิทธิภาพและความแม่นยำสำหรับปัญหาการถดถอยและการจำแนกประเภท
หากคุณใฝ่ฝันที่จะประกอบอาชีพในสาขาแมชชีนเลิร์นนิง Support Vector Machine ควรเป็นส่วนหนึ่งของคลังแสงการเรียนรู้ของคุณ ที่ upGrad เราเชื่อในการจัดเตรียมอัลกอริธึมแมชชีนเลิร์นนิงที่ดีที่สุดให้กับนักเรียนเพื่อเริ่มต้นอาชีพ นี่คือสิ่งที่เราคิดว่าสามารถช่วยให้คุณเริ่มต้นด้วย อัลกอริทึม SVM ในการเรียนรู้ของเครื่อง
สารบัญ
อัลกอริธึม Support Vector Machine คืออะไร?
SVM เป็น อัลกอริธึมการเรียนรู้ภายใต้การดูแลประเภทหนึ่งซึ่งได้รับความนิยมอย่างมากในปี 2020 และจะเป็นเช่นนี้ต่อไปในอนาคต ประวัติของ SVM มีอายุย้อนไปถึงปี 1990; มาจากทฤษฎีการเรียนรู้เชิงสถิติของ Vapnik SVM สามารถใช้ได้กับความท้าทายทั้งการถดถอยและการจำแนกประเภท อย่างไรก็ตาม ส่วนใหญ่จะใช้เพื่อจัดการกับความท้าทายในการจัดหมวดหมู่
SVM เป็นตัวแยกประเภทที่สร้างไฮเปอร์เพลนในพื้นที่ N-dimensional โดยที่ n คือจำนวนของคุณสมบัติในชุดข้อมูลเพื่อช่วยแยกแยะอินพุตข้อมูลในอนาคต ฟังดูน่าสับสน ไม่ต้องกังวล เราจะเข้าใจมันในแง่คนธรรมดา

อัลกอริธึมเครื่องเวกเตอร์สนับสนุนทำงานอย่างไร
ก่อนเจาะลึกถึงการทำงานของ SVM เรามาทำความเข้าใจคำศัพท์สำคัญบางคำกันก่อน
ไฮเปอร์เพลน
ไฮเปอร์เพลน ซึ่งบางครั้งเรียกว่าขอบเขตการตัดสินใจหรือระนาบการตัดสินใจ เป็นขอบเขตที่ช่วยจำแนกจุดข้อมูล ด้านไฮเปอร์เพลนซึ่งมีจุดข้อมูลใหม่ตกอยู่ สามารถแยกออกหรือระบุถึงคลาสต่างๆ ได้ ขนาดของไฮเปอร์เพลนขึ้นอยู่กับจำนวนคุณลักษณะที่มาจากชุดข้อมูล หากชุดข้อมูลมี 2 คุณสมบัติ ไฮเปอร์เพลนอาจเป็นเส้นธรรมดาได้ เมื่อชุดข้อมูลมีคุณสมบัติ 3 ประการ ไฮเปอร์เพลนจะเป็นระนาบ 2 มิติ
เวกเตอร์สนับสนุน
เวกเตอร์สนับสนุนเป็นจุดข้อมูลที่ใกล้กับไฮเปอร์เพลนมากที่สุดและส่งผลต่อตำแหน่งของมัน เนื่องจากเวกเตอร์เหล่านี้ส่งผลต่อการวางตำแหน่งไฮเปอร์เพลน จึงเรียกว่าเวกเตอร์สนับสนุนและด้วยเหตุนี้จึงตั้งชื่อว่า Support Vector Machine Algorithm
มาร์จิ้น
พูดง่ายๆ คือ ระยะขอบคือช่องว่างระหว่างไฮเปอร์เพลนและเวกเตอร์แนวรับ SVM จะเลือกไฮเปอร์เพลนที่เพิ่มระยะขอบให้สูงสุดเสมอ ยิ่งมาร์จิ้นมากเท่าไหร่ ผลลัพธ์ก็จะยิ่งแม่นยำมากขึ้นเท่านั้น ระยะขอบมีสองประเภทที่ใช้ใน อัลกอริธึม SVM แบบ แข็งและแบบอ่อน
เมื่อชุดข้อมูลการฝึกอบรมสามารถแยกออกได้เป็นเส้นตรง SVM สามารถเลือกเส้นคู่ขนานสองเส้นที่เพิ่มระยะขอบให้มากที่สุด นี้เรียกว่าขอบแข็ง เมื่อชุดข้อมูลการฝึกไม่แยกเป็นเส้นตรงทั้งหมด SVM จะอนุญาตให้มีการละเมิดระยะขอบบางส่วน อนุญาตให้จุดข้อมูลบางจุดอยู่บนด้านที่ไม่ถูกต้องของไฮเปอร์เพลนหรือระหว่างระยะขอบและไฮเปอร์เพลน เพื่อไม่ให้เกิดความแม่นยำ สิ่งนี้เรียกว่าระยะขอบแบบอ่อน
สามารถมีไฮเปอร์เพลนที่เป็นไปได้มากมายสำหรับชุดข้อมูลที่กำหนด เป้าหมายของ VSM คือการเลือกระยะขอบสูงสุดเพื่อจัดประเภทจุดข้อมูลใหม่เป็นคลาสต่างๆ เมื่อมีการเพิ่มจุดข้อมูลใหม่ SVM จะกำหนดด้านของไฮเปอร์เพลนที่จุดข้อมูลตก จากด้านข้างของไฮเปอร์เพลนที่จุดข้อมูลใหม่ตกอยู่ จากนั้น SVM จะจำแนกออกเป็นคลาสต่างๆ
อ่าน: พีชคณิตเชิงเส้นสำหรับการเรียนรู้ของเครื่อง: แนวคิดที่สำคัญ เหตุใดจึงต้องเรียนรู้ก่อน ML
Support Vector Machines ประเภทใดบ้าง
จากชุดข้อมูลการฝึกอบรม อัลกอริธึม SVM สามารถเป็นได้สองประเภท:
SVM เชิงเส้น
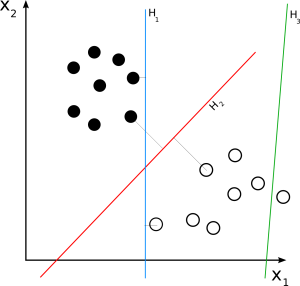
แหล่งที่มา
Linear SVM ใช้สำหรับชุดข้อมูลที่แยกได้เชิงเส้น ตัวอย่างง่ายๆ ในชีวิตจริงช่วยให้เราเข้าใจการทำงานของ SVM เชิงเส้นได้ พิจารณาชุดข้อมูลที่มีคุณลักษณะเดียว คือ น้ำหนักของบุคคล จุดข้อมูลสามารถแบ่งได้เป็น 2 ประเภท คือ อ้วนหรือไม่อ้วน ในการจำแนกจุดข้อมูลออกเป็นสองคลาสนี้ SVM สามารถสร้างไฮเปอร์เพลนขอบสูงสุดด้วยความช่วยเหลือของเวกเตอร์สนับสนุนที่ใกล้ที่สุด ตอนนี้ เมื่อใดก็ตามที่มีการเพิ่มจุดข้อมูลใหม่ SVM จะตรวจจับด้านไฮเปอร์เพลน ตำแหน่งที่จุดข้อมูลตก และจัดประเภทบุคคลนั้นเป็นโรคอ้วนหรือไม่
SVM ที่ไม่ใช่เชิงเส้น
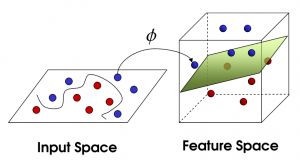
แหล่งที่มา
เมื่อจำนวนคุณสมบัติเพิ่มขึ้น การแยกชุดข้อมูลแบบเส้นตรงจะกลายเป็นเรื่องท้าทาย นั่นคือที่ที่ใช้ SVM ที่ไม่ใช่เชิงเส้น เราไม่สามารถวาดเส้นตรงเพื่อแยกจุดข้อมูลเมื่อชุดข้อมูลไม่สามารถแยกเป็นเส้นตรงได้ ดังนั้น เพื่อแยกจุดข้อมูลเหล่านี้ SVM จะเพิ่มมิติอื่น มิติข้อมูลใหม่ z สามารถคำนวณได้เป็น z = x2 + Y2 การคำนวณนี้จะช่วยแยกคุณลักษณะของชุดข้อมูลในรูปแบบเชิงเส้น จากนั้น SVM จะสร้างไฮเปอร์เพลนเพื่อจัดประเภทจุดข้อมูล
เมื่อจุดข้อมูลถูกแปลงเป็นพื้นที่มิติสูงโดยการเพิ่มมิติใหม่ มันจะแยกออกได้อย่างง่ายดายด้วยไฮเปอร์เพลน ทำได้โดยใช้สิ่งที่เรียกว่าเคล็ดลับเคอร์เนล ด้วยเคล็ดลับเคอร์เนล อัลกอริธึม SVM สามารถแปลงข้อมูลที่ไม่สามารถแยกออกเป็นข้อมูลที่แยกได้
เคอร์เนลคืออะไร?
เคอร์เนลเป็นฟังก์ชันที่ใช้อินพุตขนาดต่ำและแปลงเป็นพื้นที่มิติสูง มันยังเรียกว่าพารามิเตอร์การปรับแต่งที่ช่วยเพิ่มความแม่นยำของเอาต์พุต SVM พวกเขาดำเนินการแปลงข้อมูลที่ซับซ้อนบางอย่างเพื่อแปลงชุดข้อมูลที่ไม่สามารถแยกออกเป็นชุดที่แยกได้
แหล่งที่มา
เคอร์เนล SVM ประเภทต่าง ๆ มีอะไรบ้าง
เคอร์เนลเชิงเส้น
ตามชื่อที่แนะนำ เคอร์เนลเชิงเส้นใช้สำหรับชุดข้อมูลที่แยกได้เชิงเส้น ส่วนใหญ่จะใช้สำหรับชุดข้อมูลที่มีคุณสมบัติจำนวนมาก เช่น การจัดประเภทข้อความ โดยที่ตัวอักษรทั้งหมดเป็นคุณลักษณะใหม่ ไวยากรณ์ของเคอร์เนลเชิงเส้นคือ:

K(x, y) = ผลรวม(x*y)
x และ y ในไวยากรณ์เป็นเวกเตอร์สองตัว
การฝึก SVM ด้วยเคอร์เนลเชิงเส้นเร็วกว่าการฝึกกับเคอร์เนลอื่นๆ เนื่องจากต้องการการปรับให้เหมาะสมของพารามิเตอร์การทำให้เป็นมาตรฐาน C เท่านั้น ไม่ใช่พารามิเตอร์แกมมา
เคอร์เนลพหุนาม
เคอร์เนลพหุนามเป็นรูปแบบทั่วไปของเคอร์เนลเชิงเส้นที่มีประโยชน์ในการแปลงชุดข้อมูลที่ไม่ใช่เชิงเส้น สูตรของเคอร์เนลพหุนามมีดังนี้:
K(x, y) = (xT*y + c)d
ในที่นี้ x และ y เป็นเวกเตอร์สองตัว c คือค่าคงที่ที่ยอมให้แลกเปลี่ยนเงื่อนไขมิติที่สูงกว่าและต่ำกว่า และ d คือลำดับของเคอร์เนล นักพัฒนาซอฟต์แวร์ควรตัดสินใจลำดับของเคอร์เนลด้วยตนเองในอัลกอริทึม
เคอร์เนลฟังก์ชันพื้นฐานเรเดียล
เคอร์เนลฟังก์ชันพื้นฐานแบบเรเดียล หรือที่เรียกว่าเคอร์เนลแบบเกาส์เซียน เป็นเคอร์เนลที่ใช้กันอย่างแพร่หลายใน อัลกอริธึม SVM สำหรับการแก้ปัญหาการจำแนกประเภท มีศักยภาพในการแมปข้อมูลอินพุตลงในช่องว่างมิติสูงที่ไม่แน่นอน เคอร์เนลฟังก์ชันพื้นฐานแนวรัศมีสามารถแสดงทางคณิตศาสตร์ได้ดังนี้:
K(x, y) = ค่าประสบการณ์(-แกมมา*ผลรวม(x – y2))
ในที่นี้ x และ y เป็นเวกเตอร์สองตัว และแกมมาเป็นพารามิเตอร์การปรับค่าตั้งแต่ 0 ถึง 1 แกมมาถูกกำหนดไว้ล่วงหน้าด้วยตนเองในอัลกอริธึมการเรียนรู้
ฟังก์ชันพื้นฐานเชิงเส้นตรง พหุนาม และแนวรัศมีแตกต่างกันในแนวทางทางคณิตศาสตร์สำหรับการตัดสินใจในการสร้างไฮเปอร์เพลนและความแม่นยำ เมล็ดเชิงเส้นและพหุนามใช้เวลาน้อยกว่าในการฝึกอบรม แต่มีความแม่นยำน้อยกว่า ในทางกลับกัน เคอร์เนลของฟังก์ชันพื้นฐานแนวรัศมีใช้เวลาในการฝึกนานขึ้น แต่ให้ผลลัพธ์ที่แม่นยำกว่าในแง่ของผลลัพธ์
ตอนนี้คำถามที่เกิดขึ้นคือวิธีการเลือกเคอร์เนลที่จะใช้สำหรับชุดข้อมูลของคุณ การตัดสินใจของคุณควรขึ้นอยู่กับความซับซ้อนของชุดข้อมูลและความถูกต้องของผลลัพธ์ที่คุณต้องการเท่านั้น แน่นอน ทุกคนต้องการผลลัพธ์ที่มีความแม่นยำสูง แต่ก็ขึ้นอยู่กับเวลาที่คุณต้องพัฒนาโซลูชันและจำนวนเงินที่คุณจะใช้ไปกับมัน นอกจากนี้ โดยทั่วไปแล้ว เคอร์เนลฟังก์ชันพื้นฐานแนวรัศมีจะให้ความแม่นยำสูงกว่า แต่ในบางกรณี เคอร์เนลเชิงเส้นและพหุนามสามารถทำงานได้ดีเท่ากัน
ตัวอย่างเช่น สำหรับข้อมูลที่แยกได้เชิงเส้นตรง เคอร์เนลเชิงเส้นจะทำงานเช่นเดียวกับเคอร์เนลพื้นฐานในแนวรัศมี และในขณะที่ใช้เวลาฝึกน้อยลง ดังนั้นหากชุดข้อมูลของคุณแยกเชิงเส้นได้ คุณควรเลือกเคอร์เนลเชิงเส้น สำหรับข้อมูลที่ไม่ใช่เชิงเส้น คุณควรเลือกฟังก์ชันพหุนามหรือฟังก์ชันพื้นฐานแนวรัศมี ขึ้นอยู่กับเวลาและค่าใช้จ่ายที่คุณมี
พารามิเตอร์การปรับแต่งที่ใช้กับเคอร์เนลคืออะไร
C การทำให้เป็นมาตรฐาน
พารามิเตอร์การทำให้เป็นมาตรฐาน C ยอมรับค่าจากคุณเพื่อให้มีการจัดประเภทผิดในระดับหนึ่งในชุดข้อมูลการฝึกอบรมแต่ละชุด ค่าการทำให้เป็นมาตรฐาน C ที่สูงขึ้นนำไปสู่ไฮเปอร์เพลนขอบเล็กและไม่อนุญาตให้มีการจัดประเภทผิดมากนัก ในทางกลับกัน ค่าที่ต่ำกว่าจะนำไปสู่กำไรที่สูงและการจัดประเภทที่ไม่ถูกต้องมากขึ้น
แกมมา
พารามิเตอร์แกมมากำหนดช่วงของเวกเตอร์สนับสนุนที่จะส่งผลต่อตำแหน่งของไฮเปอร์เพลน ค่าแกมมาสูงจะพิจารณาเฉพาะจุดข้อมูลที่อยู่ใกล้เคียง และค่าต่ำจะพิจารณาจุดที่อยู่ห่างไกล
วิธีการใช้อัลกอริธึม Support Vector Machine ใน Python ใช้งานได้อย่างไร

แหล่งที่มา
เนื่องจากเรามีแนวคิดพื้นฐานว่า อัลกอริธึม SVM คืออะไรและทำงานอย่างไร มาเจาะลึกสิ่งที่ซับซ้อนกว่านี้กันดีกว่า ตอนนี้เราจะดูขั้นตอนทั่วไปในการปรับใช้และเรียกใช้ อัลกอริทึม SVM ใน Python เราจะใช้ไลบรารี Scikit-Learn ของ Python เพื่อเรียนรู้วิธีใช้ อัลกอริทึม SVM
ก่อนอื่นเราต้องนำเข้าไลบรารีที่จำเป็นทั้งหมด เช่น Pandas และ NumPy ที่จำเป็นในการรัน อัลกอริธึม SVM เมื่อเรามีไลบรารี่ทั้งหมดแล้ว เราต้องนำเข้าชุดข้อมูลการฝึกอบรม ต่อไป เราต้องวิเคราะห์ชุดข้อมูลของเรา มีหลายวิธีในการวิเคราะห์ชุดข้อมูล
ตัวอย่างเช่น เราสามารถตรวจสอบมิติข้อมูล แบ่งออกเป็นการตอบสนองและตัวแปรอธิบาย และตั้งค่า KPI เพื่อวิเคราะห์ชุดข้อมูลของเรา หลังจากเสร็จสิ้นการวิเคราะห์ข้อมูล เราต้องประมวลผลชุดข้อมูลล่วงหน้า เราควรตรวจสอบข้อมูลที่ไม่เกี่ยวข้อง ไม่สมบูรณ์ และไม่ถูกต้องในชุดข้อมูลของเรา
ตอนนี้มาถึงส่วนการฝึกอบรม เราต้องโค้ดและฝึกอัลกอริทึมของเราด้วยเคอร์เนลที่เกี่ยวข้อง Scikit-Learn มีไลบรารี SVM ซึ่งคุณสามารถค้นหาคลาสในตัวสำหรับอัลกอริทึมการฝึกอบรมได้ ไลบรารี SVM มีคลาส SVC ที่ยอมรับค่าสำหรับประเภทของเคอร์เนลที่คุณต้องการใช้เพื่อฝึกอัลกอริทึมของคุณ
จากนั้นคุณเรียกวิธี fit ของคลาส SVC ที่ฝึกอัลกอริทึมของคุณ ซึ่งแทรกเป็นพารามิเตอร์ของวิธี fit คุณต้องใช้วิธีการทำนายของคลาส SVC เพื่อทำการคาดการณ์สำหรับอัลกอริทึม เมื่อคุณทำตามขั้นตอนการคาดคะเนเสร็จแล้ว คุณจะต้องเรียกรายงานการจำแนกประเภทและความสับสน_เมทริกซ์ของไลบรารีเมตริกเพื่อประเมินอัลกอริทึมของคุณและดูผลลัพธ์
แอพพลิเคชั่นของอัลกอริธึม Support Vector Machine คืออะไร?
อัลกอริทึม SVM มีแอปพลิเคชันสำหรับความท้าทายด้านการถดถอยและการจำแนกประเภทต่างๆ แอปพลิเคชันหลักบางตัวของ อัลกอริทึม SVM ได้แก่:
- การจัดประเภทข้อความและไฮเปอร์เท็กซ์
- การจำแนกรูปภาพ
- การจำแนกข้อมูลดาวเทียม เช่น เรดาร์รูรับแสงสังเคราะห์ (SAR)
- การจำแนกสารชีวภาพ เช่น โปรตีน
- การรู้จำอักขระในข้อความที่เขียนด้วยลายมือ
เหตุใดจึงต้องใช้อัลกอริธึม Support Vector Machine
อัลกอริทึม SVM มีประโยชน์มากมาย เช่น:
- มีประสิทธิภาพในการแยกข้อมูลที่ไม่เป็นเชิงเส้น
- มีความแม่นยำสูงทั้งในช่องว่างมิติล่างและมิติสูง
- ป้องกันปัญหา overfitting เนื่องจากเวกเตอร์สนับสนุนส่งผลกระทบต่อตำแหน่งของไฮเปอร์เพลนเท่านั้น
เช็คเอาท์: 6 ประเภทของฟังก์ชันการเปิดใช้งานในโครงข่ายประสาทเทียมที่คุณต้องรู้
สรุป
เราได้ดู อัลกอริธึม Support Vector Machine ในบทความนี้โดยละเอียดแล้ว เราได้เรียนรู้เกี่ยวกับ อัลกอริทึม SVM วิธี การทำงาน ประเภท แอปพลิเคชัน ประโยชน์ และการใช้งานใน Python บทความนี้จะให้แนวคิดพื้นฐานเกี่ยวกับ อัลกอริทึม SVM และตอบคำถามของคุณ
แต่ยังจะนำมาซึ่งคำถามอื่นๆ เช่น วิธีที่ อัลกอริธึม SVM รู้ได้อย่างไรว่าไฮเปอร์เพลนที่ถูกต้องคืออะไร ไลบรารีอื่นๆ ที่มีอยู่ใน Python มีอะไรบ้าง และจะหาชุดข้อมูลการฝึกอบรมได้จากที่ใด หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ข้อ จำกัด ของการใช้อัลกอริธึมเครื่องเวกเตอร์สนับสนุนในการเรียนรู้ของเครื่องมีอะไรบ้าง?
ไม่แนะนำให้ใช้วิธี SVM สำหรับชุดข้อมูลขนาดใหญ่ เราต้องเลือกเคอร์เนลในอุดมคติสำหรับ SVM ซึ่งเป็นกระบวนการที่ท้าทาย นอกจากนี้ SVM ยังทำงานได้ไม่ดีเมื่อจำนวนตัวอย่างข้อมูลการฝึกน้อยกว่าจำนวนคุณลักษณะในชุดข้อมูลแต่ละชุด เนื่องจากเครื่องเวกเตอร์สนับสนุนไม่ใช่แบบจำลองความน่าจะเป็น เราจึงไม่สามารถอธิบายการจำแนกประเภทในแง่ของความน่าจะเป็นได้ นอกจากนี้ ความซับซ้อนของอัลกอริทึมและความต้องการหน่วยความจำของ SVM นั้นค่อนข้างสูง
โมเดล SVM เชิงเส้นและไม่เป็นเชิงเส้นแตกต่างกันอย่างไร
ในกรณีของตัวแบบเชิงเส้นตรง ข้อมูลสามารถจำแนกได้ง่ายโดยการวาดเส้นตรง ซึ่งไม่ใช่กรณีที่มีแบบจำลองเครื่องสนับสนุนเวกเตอร์ที่ไม่เป็นเชิงเส้น SVM เชิงเส้นนั้นฝึกได้เร็วกว่าเมื่อเทียบกับ SVM ที่ไม่ใช่เชิงเส้น อัลกอริธึม SVM เชิงเส้นสันนิษฐานว่าสามารถแยกเชิงเส้นได้สำหรับแต่ละจุดข้อมูล ในขณะที่อยู่ใน SVM ที่ไม่เป็นเชิงเส้น ซอฟต์แวร์จะแปลงเวกเตอร์ข้อมูลโดยใช้ฟังก์ชันเคอร์เนลที่ไม่เป็นเชิงเส้นที่ดีที่สุดสำหรับสถานการณ์ที่กำหนด
พารามิเตอร์ C มีบทบาทอย่างไรใน SVM
ใน SVM พารามิเตอร์ C แสดงถึงระดับความแม่นยำในการจำแนกประเภทที่อัลกอริทึมต้องบรรลุ กล่าวโดยย่อ พารามิเตอร์ C จะกำหนดจำนวนเงินที่คุณต้องการลงโทษแบบจำลองของคุณสำหรับแต่ละจุดที่จัดประเภทผิดบนเส้นโค้งที่แน่นอน C ต่ำจะทำให้พื้นผิวการตัดสินใจราบรื่นขึ้น ในขณะที่ C สูงจะพยายามจัดหมวดหมู่อินสแตนซ์การฝึกอบรมทั้งหมดอย่างแม่นยำ โดยอนุญาตให้โมเดลเลือกตัวอย่างเพิ่มเติมเป็นเวกเตอร์สนับสนุน