
การใช้ Convolutional Neural Network สำหรับการจำแนกรูปภาพ
เผยแพร่แล้ว: 2020-08-14การจัดประเภทรูปภาพได้รับการปรับปรุง ขอบคุณซีเอ็นเอ็น
Convolutional Neural Networks (CNNs) เป็นแกนหลักของการจัดประเภทรูปภาพ ซึ่งเป็นปรากฏการณ์การเรียนรู้เชิงลึกที่รับภาพและกำหนดคลาสและป้ายกำกับที่ทำให้มีเอกลักษณ์เฉพาะตัว การจัดประเภทรูปภาพโดยใช้ CNN เป็นส่วนสำคัญของการทดลองแมชชีนเลิร์นนิง
เมื่อใช้ร่วมกับ CNN และความสามารถที่เหนี่ยวนำขึ้น ขณะนี้มีการใช้กันอย่างแพร่หลายสำหรับแอปพลิเคชันต่างๆ ตั้งแต่การติดแท็กรูปภาพบน Facebook ไปจนถึงคำแนะนำผลิตภัณฑ์ของ Amazon และภาพด้านการดูแลสุขภาพ ไปจนถึงรถยนต์อัตโนมัติ เหตุผลที่ CNN ได้รับความนิยมมากคือต้องใช้การประมวลผลล่วงหน้าเพียงเล็กน้อย ซึ่งหมายความว่าสามารถอ่านภาพ 2D ได้โดยใช้ตัวกรองที่อัลกอริธึมทั่วไปอื่นๆ ไม่สามารถทำได้ เราจะเจาะลึกถึงกระบวนการ จัดหมวดหมู่รูปภาพโดย ใช้ CNN
สารบัญ
CNN ทำงานอย่างไร?
CNN มีชั้นอินพุต เลเยอร์เอาท์พุต และเลเยอร์ที่ซ่อนอยู่ ซึ่งทั้งหมดนี้ช่วยประมวลผลและจำแนกรูปภาพ เลเยอร์ที่ซ่อนอยู่ประกอบด้วยเลเยอร์ที่โค้งงอ เลเยอร์ ReLU เลเยอร์การรวม และเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ ซึ่งทั้งหมดมีบทบาทสำคัญ เรียนรู้เพิ่มเติมเกี่ยวกับโครงข่ายประสาทเทียม
มาดูกันว่าการ จำแนกรูปภาพโดยใช้ CNN ทำงานอย่างไร:
ลองนึกภาพว่าภาพที่ป้อนเป็นภาพช้าง ภาพนี้ซึ่งมีพิกเซลถูกป้อนลงในเลเยอร์ที่บิดเบี้ยวก่อน หากเป็นภาพขาวดำ ภาพจะถูกตีความว่าเป็นเลเยอร์ 2 มิติ โดยทุกพิกเซลจะกำหนดค่าระหว่าง '0' และ '255', '0' เป็นสีดำทั้งหมด และ '255' เป็นสีขาวทั้งหมด หากเป็นภาพสี จะกลายเป็นอาร์เรย์ 3 มิติ โดยมีชั้นสีน้ำเงิน สีเขียว และสีแดง โดยแต่ละค่าสีอยู่ระหว่าง 0 ถึง 255

การอ่านเมทริกซ์เริ่มต้นขึ้น ซึ่งซอฟต์แวร์จะเลือกภาพที่เล็กกว่า เรียกว่า 'ตัวกรอง' (หรือเคอร์เนล) ความลึกของตัวกรองเท่ากับความลึกของอินพุต จากนั้นฟิลเตอร์จะสร้างการเคลื่อนไหวที่บิดเบี้ยวไปพร้อมกับภาพที่ป้อนเข้าไป โดยเคลื่อนที่ไปทางขวาตามภาพ 1 หน่วย
จากนั้นจะคูณค่าด้วยค่ารูปภาพต้นฉบับ ตัวเลขที่คูณทั้งหมดจะถูกรวมเข้าด้วยกัน และสร้างหมายเลขเดียว กระบวนการนี้ซ้ำกับรูปภาพทั้งหมด และได้รับเมทริกซ์ ซึ่งเล็กกว่ารูปภาพอินพุตดั้งเดิม
อาร์เรย์สุดท้ายเรียกว่าแผนผังคุณลักษณะของแผนผังการเปิดใช้งาน การบิดเบี้ยวของภาพช่วยดำเนินการต่างๆ เช่น การตรวจจับขอบ การเพิ่มความคมชัด และการเบลอ โดยใช้ฟิลเตอร์ต่างๆ สิ่งเดียวที่ต้องทำคือระบุด้านต่างๆ เช่น ขนาดของตัวกรอง จำนวนตัวกรอง และ/หรือสถาปัตยกรรมของเครือข่าย
จากมุมมองของมนุษย์ การกระทำนี้คล้ายกับการระบุสีและขอบเขตที่เรียบง่ายของภาพ อย่างไรก็ตาม ในการจำแนกภาพและจำแนกลักษณะที่ทำให้มันเป็นช้างไม่ใช่แมว จำเป็นต้องระบุลักษณะเฉพาะ เช่น หูขนาดใหญ่และงวงของช้าง นี่คือที่มาของเลเยอร์ที่ไม่ใช่เชิงเส้นและการรวมเข้าด้วยกัน
เลเยอร์ที่ไม่เป็นเชิงเส้น (ReLU) จะอยู่ถัดจากเลเยอร์การบิด โดยที่ฟังก์ชันการเปิดใช้งานถูกนำไปใช้กับแมปคุณลักษณะเพื่อเพิ่มความไม่เป็นเชิงเส้นของรูปภาพ เลเยอร์ ReLU จะลบค่าลบทั้งหมดและเพิ่มความแม่นยำของภาพ แม้ว่าจะมีการดำเนินการอื่น ๆ เช่น tanh หรือ sigmoid แต่ ReLU ก็เป็นที่นิยมมากที่สุดเนื่องจากสามารถฝึกเครือข่ายได้เร็วกว่ามาก
ขั้นตอนต่อไปคือการสร้างรูปภาพหลายๆ รูปของวัตถุเดียวกัน เพื่อให้เครือข่ายสามารถจดจำรูปภาพนั้นได้ตลอดเวลา ไม่ว่าจะมีขนาดหรือตำแหน่งใดก็ตาม ตัวอย่างเช่น ในภาพช้าง เครือข่ายต้องรู้จักช้าง ไม่ว่าจะกำลังเดิน ยืนนิ่ง หรือวิ่ง ต้องมีความยืดหยุ่นของภาพ และนั่นคือที่มาของเลเยอร์การรวม
ทำงานร่วมกับการวัดของภาพ (ความสูงและความกว้าง) เพื่อลดขนาดของภาพที่ป้อนเข้าไปเรื่อยๆ เพื่อให้มองเห็นและระบุวัตถุในภาพได้ไม่ว่าจะอยู่ที่ใด
การรวมกลุ่มยังช่วยควบคุม 'ความเหมาะสม' ที่มีข้อมูลมากเกินไปโดยไม่มีขอบเขตสำหรับข้อมูลใหม่ บางที ตัวอย่างที่พบบ่อยที่สุดของการรวมกลุ่มก็คือการรวมกันสูงสุด โดยที่รูปภาพถูกแบ่งออกเป็นชุดของพื้นที่ที่ไม่ทับซ้อนกัน
Max pooling เป็นข้อมูลเกี่ยวกับการระบุค่าสูงสุดในแต่ละพื้นที่ เพื่อไม่ให้มีข้อมูลพิเศษทั้งหมด และรูปภาพจะมีขนาดเล็กลง การดำเนินการนี้ช่วยอธิบายความผิดเพี้ยนของภาพด้วย
ตอนนี้เป็นเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ซึ่งเพิ่มโครงข่ายประสาทเทียมสำหรับการใช้ CNN เครือข่ายเทียมนี้รวมคุณสมบัติต่างๆ และช่วยทำนายคลาสของรูปภาพได้อย่างแม่นยำยิ่งขึ้น ในขั้นตอนนี้ การไล่ระดับของฟังก์ชันข้อผิดพลาดจะคำนวณเกี่ยวกับน้ำหนักของโครงข่ายประสาทเทียม ตุ้มน้ำหนักและตัวตรวจจับคุณสมบัติได้รับการปรับเพื่อเพิ่มประสิทธิภาพการทำงาน และกระบวนการนี้จะเกิดขึ้นซ้ำๆ
สถาปัตยกรรม CNN มีลักษณะดังนี้:
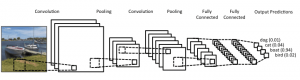
แหล่งที่มา
ใช้ประโยชน์จากชุดข้อมูลสำหรับ CNN Application-MNIST
สามารถใช้ชุดข้อมูลหลายชุดเพื่อใช้ CNN ได้อย่างมีประสิทธิภาพ สามรายการที่ได้รับความนิยมมากที่สุดซึ่งสำคัญใน การจำแนกรูปภาพโดยใช้ CNN ได้แก่ MNIST, CIFAR-10 และ ImageNet มาดู MNIST กันก่อน
1. MNIST
MNIST เป็นตัวย่อของชุดข้อมูล Modified National Institute of Standards and Technology และประกอบด้วยรูปภาพระดับสีเทาขนาดเล็ก 28 × 28 สี่เหลี่ยมจัตุรัสขนาด 60,000 ตัวของตัวเลขที่เขียนด้วยลายมือเพียงตัวเดียวระหว่าง 0 ถึง 9 MNIST เป็นชุดข้อมูลยอดนิยมและเข้าใจดีซึ่งหมายถึง ส่วน 'แก้ไข' สามารถใช้ในคอมพิวเตอร์วิทัศน์และการเรียนรู้เชิงลึกเพื่อฝึกฝน พัฒนา และประเมิน การจัดประเภท ภาพ โดยใช้ CNN ซึ่งรวมถึงขั้นตอนในการประเมินประสิทธิภาพของแบบจำลอง สำรวจการปรับปรุงที่เป็นไปได้ และใช้เพื่อคาดการณ์ข้อมูลใหม่
USP ของมันคือมีชุดข้อมูลรถไฟและชุดทดสอบที่กำหนดไว้อย่างดีที่เราสามารถใช้ได้ ชุดการฝึกนี้สามารถแบ่งออกได้อีกเป็นการฝึกและตรวจสอบชุดข้อมูล หากต้องการประเมินประสิทธิภาพของแบบจำลองการฝึก ประสิทธิภาพการทำงานในรถไฟและชุดตรวจสอบความถูกต้องในการวิ่งแต่ละครั้งสามารถบันทึกเป็นเส้นโค้งการเรียนรู้เพื่อให้เข้าใจมากขึ้นว่าตัวแบบเรียนรู้ปัญหาได้ดีเพียงใด
Keras หนึ่งใน API เครือข่ายประสาทเทียมชั้นนำ สนับสนุนสิ่งนี้โดยกำหนดอาร์กิวเมนต์ "validation_data " ให้กับโมเดล ฟังก์ชัน Fit() เมื่อฝึกโมเดล ซึ่งจะส่งคืนอ็อบเจ็กต์ที่กล่าวถึงประสิทธิภาพของโมเดลสำหรับการสูญเสียและเมตริกในการรันการฝึกแต่ละครั้ง โชคดีที่ MNIST ติดตั้ง Keras เป็นค่าเริ่มต้น และสามารถโหลดไฟล์ฝึกและทดสอบได้โดยใช้โค้ดเพียงไม่กี่บรรทัด
บทความที่น่าสนใจโดย Yann LeCun ศาสตราจารย์แห่ง Courant Institute of Mathematical Sciences ที่มหาวิทยาลัยนิวยอร์ก และ Corinna Cortes นักวิทยาศาสตร์การวิจัยที่ Google Labs ในนิวยอร์ก ชี้ให้เห็นว่าฐานข้อมูลพิเศษ 3 (SD-3) ของ MNIST เดิมถูกกำหนดให้เป็น ชุดฝึก. ฐานข้อมูลพิเศษ 1 (SD-1) ถูกกำหนดให้เป็นชุดทดสอบ

อย่างไรก็ตาม พวกเขาเชื่อว่า SD-3 นั้นระบุและจดจำได้ง่ายกว่า SD-1 มาก เนื่องจาก SD-3 ถูกรวบรวมจากพนักงานที่ทำงานในสำนักสำรวจสำมะโนประชากร ในขณะที่ SD-1 นั้นมาจากกลุ่มนักเรียนมัธยมปลาย เนื่องจากข้อสรุปที่ถูกต้องจากการเรียนรู้การทดลองกำหนดให้ผลลัพธ์ต้องเป็นอิสระจากชุดการฝึกและการทดสอบ จึงถือว่าจำเป็นต้องพัฒนาฐานข้อมูลใหม่โดยขาดชุดข้อมูล
เมื่อใช้ชุดข้อมูล ขอแนะนำให้แบ่งออกเป็น minibatches เก็บไว้ในตัวแปรที่ใช้ร่วมกัน และเข้าถึงตามดัชนี minibatch คุณอาจสงสัยว่าจำเป็นต้องใช้ตัวแปรร่วมกัน แต่สิ่งนี้เกี่ยวข้องกับการใช้ GPU สิ่งที่เกิดขึ้นคือเมื่อคัดลอกข้อมูลลงในหน่วยความจำ GPU หากคุณคัดลอกแต่ละ minibatch แยกกันตามความจำเป็น โค้ด GPU จะช้าลงและไม่เร็วกว่าโค้ด CPU มากนัก หากคุณมีข้อมูลของคุณในตัวแปรที่ใช้ร่วมกันของ Theano มีโอกาสที่ดีที่จะคัดลอกข้อมูลทั้งหมดไปยัง GPU ในคราวเดียวเมื่อมีการสร้างตัวแปรที่ใช้ร่วมกัน
ภายหลัง GPU สามารถใช้ minibatch โดยการเข้าถึงตัวแปรที่ใช้ร่วมกันเหล่านี้โดยไม่ต้องคัดลอกข้อมูลจากหน่วยความจำของ CPU นอกจากนี้ เนื่องจากจุดข้อมูลมักจะเป็นตัวเลขจริงและจำนวนเต็มของป้ายกำกับ จึงเป็นการดีที่จะใช้ตัวแปรต่างๆ สำหรับสิ่งเหล่านี้ เช่นเดียวกับชุดตรวจสอบความถูกต้อง ชุดฝึก และชุดทดสอบ เพื่อทำให้โค้ดอ่านง่ายขึ้น
รหัสด้านล่างแสดงวิธีการจัดเก็บข้อมูลและเข้าถึง minibatch:
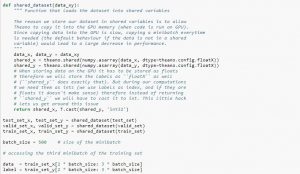
แหล่งที่มา
2. ชุดข้อมูล CIFAR-10
CIFAR ย่อมาจาก Canadian Institute for Advanced Research และชุดข้อมูล CIFAR-10 ได้รับการพัฒนาโดยนักวิจัยที่สถาบัน CIFAR ร่วมกับชุดข้อมูล CIFAR-100 ชุดข้อมูล CIFAR-10 ประกอบด้วยภาพสีขนาด 60,000 32×32 พิกเซลของวัตถุที่อยู่ในสิบคลาส เช่น แมว เรือ นก กบ ฯลฯ ภาพเหล่านี้มีขนาดเล็กกว่าภาพถ่ายทั่วไปมากและมีไว้สำหรับวัตถุประสงค์ในการมองเห็นด้วยคอมพิวเตอร์
CIFAR เป็นชุดข้อมูลที่เข้าใจได้ง่ายและตรงไปตรงมาซึ่งมีความแม่นยำ 80% ในการ จัดประเภทรูปภาพโดยใช้กระบวนการ CNN และ 90% ในชุดข้อมูลทดสอบ นอกจากนี้ รูปภาพมากถึง 1,000 ภาพที่กระจายออกไปในชุดทดสอบหนึ่งชุดและชุดฝึกอบรมห้าชุด
ชุดข้อมูล CIFAR-10 ประกอบด้วยภาพที่สุ่มเลือก 1,000 รูปจากแต่ละคลาส แต่บางชุดอาจมีรูปภาพจากคลาสหนึ่งมากกว่าอีกคลาสหนึ่ง อย่างไรก็ตาม ชุดฝึกอบรมประกอบด้วยรูปภาพ 5,000 รูปจากแต่ละชั้นเรียน ชุดข้อมูล CIFAR-10 เป็นที่ต้องการเนื่องจากใช้งานง่ายเป็นจุดเริ่มต้นสำหรับการแก้ปัญหาการ จัดประเภทรูปภาพ CNN โดยใช้ปัญหา
การออกแบบสายรัดทดสอบเป็นแบบแยกส่วน และสามารถพัฒนาได้ด้วยองค์ประกอบ 5 ประการ ได้แก่ การโหลดชุดข้อมูล การกำหนดแบบจำลอง การเตรียมชุดข้อมูล และการประเมินและการนำเสนอผลลัพธ์ ตัวอย่างด้านล่างแสดงชุดข้อมูล CIFAR-10 โดยใช้ Keras API กับเก้าภาพแรกในชุดข้อมูลการฝึก:
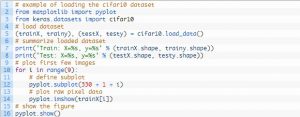
แหล่งที่มา
การรันตัวอย่างจะโหลดชุดข้อมูล CIFAR-10 และพิมพ์รูปร่าง
3. ImageNet
ImageNet ตั้งเป้าที่จะจัดหมวดหมู่และติดป้ายกำกับรูปภาพเป็นเกือบ 22,000 หมวดหมู่ตามคำและวลีที่กำหนดไว้ล่วงหน้า การทำเช่นนี้เป็นไปตามลำดับชั้นของ WordNet ซึ่งทุกคำหรือวลีเป็นคำพ้องหรือคำพ้องความหมาย (โดยย่อ) ใน ImageNet รูปภาพทั้งหมดได้รับการจัดระเบียบตามซินเซ็ตเหล่านี้ เพื่อให้มีรูปภาพมากกว่าหนึ่งพันภาพต่อหนึ่งซินเซ็ต
อย่างไรก็ตาม เมื่อ ImageNet ถูกอ้างถึงในคอมพิวเตอร์วิทัศน์และการเรียนรู้เชิงลึก สิ่งที่มีความหมายจริงๆ คือ ImageNet Large Scale Recognition Challenge หรือ ILSVRC เป้าหมายในที่นี้คือการจัดหมวดหมู่รูปภาพเป็น 1,000 หมวดหมู่ที่แตกต่างกันโดยใช้รูปภาพทดสอบมากกว่า 100,000 รูป เนื่องจากชุดข้อมูลการฝึกอบรมมีรูปภาพประมาณ 1.2 ล้านรูปภาพ
บางทีความท้าทายที่ยิ่งใหญ่ที่สุดที่นี่คือภาพใน ImageNet มีขนาด 224 × 224 ดังนั้นการประมวลผลข้อมูลจำนวนมากจึงต้องใช้ CPU, GPU และ RAM ขนาดใหญ่ สิ่งนี้อาจพิสูจน์ได้ว่าเป็นไปไม่ได้สำหรับแล็ปท็อปทั่วไป แล้วจะเอาชนะปัญหานี้ได้อย่างไร
วิธีหนึ่งในการทำเช่นนี้คือการใช้ Imagenette ซึ่งเป็นชุดข้อมูลที่ดึงมาจาก ImageNet ซึ่งไม่ต้องการทรัพยากรมากเกินไป ชุดข้อมูลนี้มีสองโฟลเดอร์ชื่อ 'train' (การฝึกอบรม) และ 'Val' (การตรวจสอบความถูกต้อง) โดยมีแต่ละโฟลเดอร์สำหรับแต่ละคลาส คลาสทั้งหมดเหล่านี้มี ID เดียวกันกับชุดข้อมูลดั้งเดิม โดยแต่ละคลาสมีรูปภาพประมาณ 1,000 รูป ดังนั้นการตั้งค่าทั้งหมดจึงค่อนข้างสมดุล
อีกทางเลือกหนึ่งคือใช้การเรียนรู้แบบถ่ายโอน ซึ่งเป็นวิธีการที่ใช้ตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้ากับชุดข้อมูลขนาดใหญ่ นี่เป็นวิธีที่มีประสิทธิภาพมากในการ จัดประเภทรูปภาพโดยใช้ CNN เนื่องจากเราสามารถใช้เพื่อสร้างแบบจำลองที่ทำงานได้ดีสำหรับเรา ด้านหนึ่งที่การ จัดประเภทรูปภาพโดยใช้โมเดล CNN ควรทำได้คือการจัดประเภทรูปภาพที่เป็นของคลาสเดียวกันและแยกแยะความแตกต่างระหว่างรูปภาพเหล่านั้น นี่คือจุดที่เราสามารถใช้ประโยชน์จากตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้าได้ ข้อได้เปรียบที่นี่คือ เราสามารถใช้วิธีต่างๆ ได้ขึ้นอยู่กับชนิดของชุดข้อมูลที่เรากำลังทำงานด้วย
อ่านเพิ่มเติม: วิศวกร ML โครงข่ายประสาทเทียม 7 ประเภทต้องรู้
สรุป
โดยสรุป การ จัดประเภทรูปภาพโดยใช้ CNN ทำให้กระบวนการง่ายขึ้น แม่นยำยิ่งขึ้น และใช้กระบวนการน้อยลง หากคุณต้องการเจาะลึกลงไปในแมชชีนเลิร์น นิง upGrad มีหลักสูตรมากมายที่จะช่วยให้คุณเชี่ยวชาญอย่างมืออาชีพ!
upGrad เสนอหลักสูตรออนไลน์ที่หลากหลายพร้อมหมวดหมู่ย่อยที่หลากหลาย เยี่ยมชม เว็บไซต์อย่างเป็นทางการ สำหรับข้อมูลเพิ่มเติม
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
โครงข่ายประสาทเทียมคืออะไร?
Convolutional Neural Network (CNN) หรือ Convolutional Neural Networks เป็นเครือข่ายประสาทเทียมแบบฟีดฟอร์เวิร์ดลึก ซึ่งมักใช้ในการวิเคราะห์ภาพ การออกแบบซีเอ็นเอ็นได้รับแรงบันดาลใจอย่างหลวมๆ จากการจัดระเบียบของวิชวลคอร์เทกซ์ของสัตว์เลี้ยงลูกด้วยนม แม้ว่าพวกมันจะถูกนำไปใช้กับเสียง คำพูด และโดเมนอื่นๆ ด้วยเช่นกัน CNN ใช้ Perceptron แบบหลายชั้นหลายรูปแบบที่ออกแบบมาเพื่อให้มีการประมวลผลล่วงหน้าน้อยที่สุด สิ่งนี้ทำให้มีโอกาสเกิดข้อผิดพลาดน้อยลงและสามารถพกพาไปใช้กับชุดปัญหาที่หลากหลายได้ แต่เสียสละความสามารถในการทำการแปลงแบบไม่เชิงเส้นกับอินพุต
เหตุใดโครงข่ายประสาทเทียมจึงเหมาะสำหรับการจำแนกรูปภาพ
ข้อจำกัดใหญ่ของ CNN คือไม่สามารถเข้าใจบริบทในภาพได้ ยังไม่สามารถทำหน้าและทำสีได้ ข้อจำกัดเพิ่มเติมของ CNN: เทคนิคการเรียนรู้ที่ใช้ในโครงข่ายประสาทเทียมไม่เพียงพอที่จะสร้างฟังก์ชันการรับรู้ที่สูงขึ้น เช่น การรู้จำวัตถุ การเรียนรู้ การรับรู้เชิงพื้นที่ และความสามารถในการถ่ายทอดประสบการณ์ สถาปัตยกรรมของโครงข่ายประสาทเทียมไม่ยืดหยุ่นพอที่จะเอาชนะข้อจำกัดเหล่านี้