
Sprijină algoritmul Vector Machine în Machine Learning
Publicat: 2020-08-14Tot ce trebuie să știți despre algoritmii de mașină vectorială de suport
Majoritatea începătorilor, când vine vorba de învățare automată, încep cu algoritmi de regresie și clasificare în mod natural. Acești algoritmi sunt simpli și ușor de urmat. Cu toate acestea, este esențial să depășim acești doi algoritmi de învățare automată pentru a înțelege mai bine conceptele de învățare automată.
Există mult mai multe de învățat în învățarea automată, care ar putea să nu fie la fel de simplu precum regresia și clasificarea, dar ne poate ajuta să rezolvăm diverse probleme complexe. Permiteți-ne să vă prezentăm un astfel de algoritm, algoritmul de suport Vector Machine . Algoritmul Support Vector Machine , sau algoritmul SVM , este de obicei denumit un astfel de algoritm de învățare automată care poate oferi eficiență și acuratețe atât pentru problemele de regresie, cât și de clasificare.
Dacă visezi să urmezi o carieră în domeniul învățării automate, atunci Support Vector Machine ar trebui să facă parte din arsenalul tău de învățare. La upGrad , credem în dotarea studenților noștri cu cei mai buni algoritmi de învățare automată pentru a începe cu cariera lor. Iată ce credem că vă poate ajuta să începeți cu algoritmul SVM în învățarea automată.
Cuprins
Ce este un algoritm de mașină vectorială de suport?
SVM este un tip de algoritm de învățare supravegheată care a devenit foarte popular în 2020 și va continua să fie așa și în viitor. Istoria SVM datează din 1990; este extras din teoria învăţării statistice a lui Vapnik. SVM poate fi folosit atât pentru provocări de regresie, cât și pentru clasificare; cu toate acestea, este folosit mai ales pentru a aborda provocările de clasificare.
SVM este un clasificator discriminativ care creează hiperplanuri în spațiul N-dimensional, unde n este numărul de caracteristici dintr-un set de date pentru a ajuta la discriminarea viitoarelor intrări de date. Sună confuz corect, nu vă faceți griji, îl vom înțelege în termeni simpli.

Cum funcționează un algoritm de mașină vectorială de suport?
Înainte de a aprofunda în funcționarea unui SVM, să înțelegem câteva dintre terminologiile cheie.
Hiperplan
Hiperplanurile, care sunt uneori denumite și limite de decizie sau planuri de decizie, sunt granițele care ajută la clasificarea punctelor de date. Partea hiperplanului, unde cade un nou punct de date, poate fi segregată sau atribuită unor clase diferite. Dimensiunea hiperplanului depinde de numărul de caracteristici care sunt atribuite unui set de date. Dacă setul de date are 2 caracteristici, atunci hiperplanul poate fi o linie simplă. Când un set de date are 3 caracteristici, atunci hiperplanul este un plan bidimensional.
Vectori de suport
Vectorii suport sunt punctele de date care sunt cel mai aproape de hiperplan și afectează poziția acestuia. Deoarece acești vectori afectează poziționarea hiperplanului, ei sunt numiți ca vectori de suport și, de aici, denumirea de algoritm de mașină vectorială de suport.
Marja
Mai simplu spus, marja este decalajul dintre hiperplan și vectorii suport. SVM alege întotdeauna hiperplanul care maximizează marja. Cu cât este mai mare marja, cu atât este mai mare acuratețea rezultatelor. Există două tipuri de marje care sunt utilizate în algoritmii SVM , hard și soft.
Când setul de date de antrenament este separabil liniar, SVM poate selecta pur și simplu două linii paralele care maximizează distanța marginală; aceasta se numește o marjă dură. Când setul de date de antrenament nu este complet separat liniar, atunci SVM permite o încălcare a marjei. Permite ca unele puncte de date să rămână pe partea greșită a hiperplanului sau între margine și hiperplan, astfel încât precizia să nu fie compromisă; aceasta se numește margine moale.
Pot exista multe hiperplanuri posibile pentru un anumit set de date. Scopul VSM este de a selecta cea mai maximă marjă pentru a clasifica noile puncte de date în diferite clase. Când este adăugat un nou punct de date, SVM-ul determină în ce parte a hiperplanului se află punctul de date. În funcție de partea hiperplanului în care se află noul punct de date, SVM îl clasifică apoi în diferite clase.
Citiți: Algebră liniară pentru învățarea automată: concepte critice, de ce să învățați înainte de ML
Care sunt tipurile de mașini de suport Vector?
Pe baza setului de date de antrenament, algoritmii SVM pot fi de două tipuri:
SVM liniar
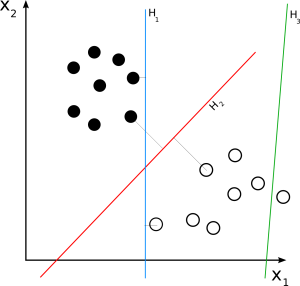
Sursă
Linear SVM este utilizat pentru un set de date separabil liniar. Un exemplu simplu din lumea reală ne poate ajuta să înțelegem funcționarea unui SVM liniar. Luați în considerare un set de date care are o singură caracteristică, greutatea unei persoane. Se presupune că punctele de date pot fi clasificate în două clase, obezi sau nu. Pentru a clasifica punctele de date în aceste două clase, SVM poate crea un hiperplan cu margine maximă cu ajutorul celor mai apropiați vectori suport. Acum, ori de câte ori este adăugat un nou punct de date, SVM-ul va detecta partea hiperplanului, unde cade și va clasifica persoana ca obeză sau nu.
SVM neliniar
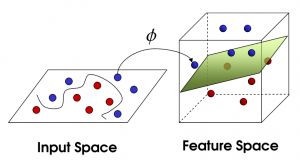
Sursă
Pe măsură ce numărul de caracteristici crește, separarea liniară a setului de date devine o provocare. Acolo este folosit un SVM neliniar. Nu putem desena o linie dreaptă pentru a separa punctele de date atunci când setul de date nu este separabil liniar. Deci, pentru a separa aceste puncte de date, SVM adaugă o altă dimensiune. Noua dimensiune z poate fi calculată ca z = x2 + Y2. Acest calcul va ajuta la separarea caracteristicilor unui set de date în formă liniară, iar apoi SVM poate crea hiperplanul pentru a clasifica punctele de date.
Când un punct de date este transformat într-un spațiu de dimensiune mare prin adăugarea unei noi dimensiuni, acesta devine ușor separabil cu un hiperplan. Acest lucru se face cu ajutorul a ceea ce se numește trucul nucleului. Cu trucul nucleului, algoritmii SVM pot transforma datele neseparabile în date separabile.
Ce este un kernel?
Un nucleu este o funcție care preia intrări de dimensiune mică și le transformă în spațiu de dimensiune mare. Este, de asemenea, menționat ca un parametru de reglare care ajută la creșterea preciziei ieșirilor SVM. Ei efectuează unele transformări complexe de date pentru a converti setul de date neseparabil într-unul separabil.
Sursă
Care sunt diferitele tipuri de nuclee SVM?
Kernel liniar
După cum sugerează și numele, nucleul liniar este utilizat pentru seturi de date separabile liniar. Este folosit mai ales pentru seturi de date cu un număr mare de caracteristici, clasificarea textului, de exemplu, unde toate alfabetele sunt o caracteristică nouă. Sintaxa nucleului liniar este:

K(x, y) = suma(x*y)
x și y în sintaxă sunt doi vectori.
Antrenarea unui SVM cu un nucleu liniar este mai rapid decât antrenamentul cu orice alt nucleu, deoarece necesită optimizarea doar a parametrului de regularizare C și nu a parametrului gamma.
Nucleul polinom
Nucleul polinom este o formă mai generalizată a nucleului liniar care este utilă în transformarea setului de date neliniar. Formula nucleului polinom este următoarea:
K(x, y) = (xT*y + c)d
Aici x și y sunt doi vectori, c este o constantă care permite un compromis pentru termeni de dimensiune mai mare și mai mică, iar d este ordinea nucleului. Dezvoltatorul ar trebui să decidă ordinea nucleului manual în algoritm.
Nucleu cu funcție de bază radială
Nucleul funcției de bază radială, denumit și nucleu gaussian, este un nucleu utilizat pe scară largă în algoritmii SVM pentru rezolvarea problemelor de clasificare. Are potențialul de a mapa datele de intrare în spații nedefinite de dimensiuni mari. Nucleul funcției de bază radială poate fi reprezentat matematic ca:
K(x, y) = exp(-gamma*sum(x – y2))
Aici, x și y sunt doi vectori, iar gamma este un parametru de reglare care variază de la 0 la 1. Gamma este predefinită manual în algoritmul de învățare.
Funcțiile de bază liniară, polinomială și radială diferă în abordarea lor matematică pentru luarea deciziilor de creare a hiperplanului și acuratețea. Nuezele liniare și polinomiale consumă mai puțin timp în antrenament, dar oferă mai puțină precizie. Pe de altă parte, nucleul funcției de bază radială necesită mai mult timp în antrenament, dar oferă o precizie mai mare în ceea ce privește rezultatele.
Acum, întrebarea care apare este cum să alegeți ce nucleu să utilizați pentru setul de date. Decizia dvs. ar trebui să depindă numai de complexitatea setului de date și de acuratețea rezultatelor dorite. Desigur, toată lumea își dorește rezultate de mare acuratețe, dar depinde și de timpul pe care îl aveți pentru a dezvolta soluția și cât de mult puteți cheltui pentru ea. De asemenea, nucleul funcției de bază radială oferă în general o precizie mai mare, dar în unele circumstanțe, nucleele liniare și polinomiale pot funcționa la fel de bine.
De exemplu, pentru date separabile liniar, un nucleu liniar va funcționa la fel de bine ca un nucleu pe bază radială și, în același timp, consumă mai puțin timp de antrenament. Deci, dacă setul de date este separabil liniar, ar trebui să alegeți un nucleu liniar. Pentru datele neliniare, ar trebui să alegeți o funcție de bază polinomială sau radială, în funcție de timpul și cheltuielile pe care le aveți.
Care sunt parametrii de reglare utilizați cu nucleele?
C regularizare
Parametrul de regularizare C acceptă valori de la dvs. pentru a permite un anumit nivel de clasificare greșită în fiecare set de date de antrenament. Valorile mai mari de regularizare C conduc la un hiperplan cu marjă mică și nu permit multă clasificare greșită. Valorile mai mici, pe de altă parte, conduc la o marjă mare și o clasificare greșită mai mare.
Gamma
Parametrul gamma definește intervalul de vectori suport care vor afecta poziționarea hiperplanului. Valoarea gamma mare ia în considerare numai punctele de date din apropiere, iar valoarea scăzută ia în considerare punctele îndepărtate.
Cum se implementează algoritmul de mașină vectorială de suport în Python?

Sursă
Deoarece avem ideea de bază despre ce este algoritmul SVM și cum funcționează, haideți să pătrundem în ceva mai complex. Acum ne vom uita la pașii generali pentru implementarea și rularea algoritmului SVM în Python. Vom folosi biblioteca Scikit-Learn din Python pentru a învăța cum să implementăm algoritmul SVM.
În primul rând, trebuie să importam toate bibliotecile necesare, cum ar fi Pandas și NumPy, care sunt necesare pentru a rula algoritmii SVM. Odată ce avem toate bibliotecile în loc, trebuie să importam setul de date de antrenament. În continuare, trebuie să ne analizăm setul de date. Există mai multe moduri de a analiza un set de date.
De exemplu, putem verifica dimensiunile datelor, le putem împărți în variabile de răspuns și explicative și putem seta KPI-uri pentru a analiza setul de date. După finalizarea analizei datelor, trebuie să preprocesăm setul de date. Ar trebui să verificăm dacă există date irelevante, incomplete și incorecte în setul nostru de date.
Acum vine partea de antrenament. Trebuie să codificăm și să ne antrenăm algoritmul cu nucleul relevant. Scikit-Learn conține biblioteca SVM, unde puteți găsi câteva clase încorporate pentru algoritmi de antrenament. Biblioteca SVM conține o clasă SVC care acceptă valoarea pentru tipul de nucleu pe care doriți să-l utilizați pentru a vă antrena algoritmii.
Apoi apelați metoda fit a clasei SVC care vă antrenează algoritmul, inserată ca parametru în metoda fit. Apoi, trebuie să utilizați metoda predict a clasei SVC pentru a face predicții pentru algoritm. După ce ați finalizat pasul de predicție, trebuie să apelați classification_report și confusion_matrix ale bibliotecii de metrici pentru a vă evalua algoritmul și a vedea rezultatul.
Care sunt aplicațiile algoritmului Support Vector Machine?
Algoritmii SVM au aplicații pentru diverse provocări de regresie și clasificare. Unele dintre aplicațiile cheie ale algoritmilor SVM sunt:
- Clasificarea textului și hipertextului
- Clasificarea imaginilor
- Clasificarea datelor din satelit, cum ar fi radarul cu deschidere sintetică (SAR)
- Clasificarea substanțelor biologice precum proteinele
- Recunoașterea caracterelor în textul scris de mână
De ce să folosiți algoritmul de suport Vector Machine?
Algoritmul SVM oferă diverse beneficii, cum ar fi:
- Eficient în separarea datelor neliniare
- Foarte precisă atât în spațiile dimensionale inferioare, cât și în cele mai mari
- Imun la problema supraajustării, deoarece vectorii suport afectează doar poziția hiperplanului.
Verificați: 6 tipuri de funcție de activare în rețelele neuronale pe care trebuie să le cunoașteți
Rezumând
Am analizat în detaliu algoritmul de mașină vectorială de suport în acest articol. Am aflat despre algoritmul SVM , cum funcționează, tipurile, aplicațiile, beneficiile și implementarea acestuia în Python. Acest articol vă va oferi o idee de bază despre algoritmul SVM și vă va răspunde la câteva dintre întrebările dvs.
Dar va aduce și alte întrebări, cum ar fi modul în care algoritmul SVM știe care este hiperplanul potrivit, ce alte biblioteci sunt disponibile în Python și unde să găsească setul de date de antrenament? Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Care sunt limitările utilizării algoritmilor de mașină vectorială de suport în învățarea automată?
Metoda SVM nu este recomandată pentru seturi mari de date. Trebuie să selectăm un nucleu ideal pentru SVM, care este un proces provocator. În plus, SVM are performanțe slabe atunci când numărul de mostre de date de antrenament este mai mic decât numărul de caracteristici din fiecare set de date. Deoarece mașina vectorului suport nu este un model probabilist, nu putem explica clasificarea în termeni de probabilitate. Mai mult, complexitatea algoritmică și cerințele de memorie ale SVM sunt destul de mari.
În ce mod sunt diferite modelele SVM liniare și neliniare unele de altele?
În cazul modelelor liniare, datele pot fi clasificate cu ușurință prin trasarea unei linii drepte, ceea ce nu este cazul modelelor de mașini cu vector suport neliniar. SVM-urile liniare sunt mai rapid de antrenat în comparație cu SVM-urile neliniare. Un algoritm liniar SVM presupune separabilitate liniară pentru fiecare punct de date. În timp ce într-un SVM neliniar, software-ul transformă vectorii de date folosind cea mai bună funcție de nucleu neliniară pentru circumstanța dată.
Ce rol joacă parametrul C în SVM?
În SVM, parametrul C reprezintă gradul de precizie în clasificare pe care trebuie să-l atingă algoritmul. Pe scurt, parametrul C determină cât de mult doriți să penalizați modelul pentru fiecare punct greșit clasificat pe o anumită curbă. Un C scăzut netezește suprafața de decizie, în timp ce un C ridicat caută să clasifice cu exactitate toate instanțele de antrenament, permițând modelului să aleagă mai multe mostre ca vectori suport.