
Supporta l'algoritmo della macchina vettoriale in Machine Learning
Pubblicato: 2020-08-14Tutto ciò che devi sapere sugli algoritmi delle macchine vettoriali di supporto
La maggior parte dei principianti, quando si tratta di machine learning, inizia naturalmente con gli algoritmi di regressione e classificazione . Questi algoritmi sono semplici e facili da seguire. Tuttavia, è essenziale andare oltre questi due algoritmi di machine learning per comprendere meglio i concetti di machine learning.
C'è molto altro da imparare nell'apprendimento automatico, che potrebbe non essere semplice come la regressione e la classificazione, ma può aiutarci a risolvere vari problemi complessi. Lascia che ti presentiamo uno di questi algoritmi, l'algoritmo Support Vector Machine . L'algoritmo Support Vector Machine , o algoritmo SVM , è generalmente indicato come uno di questi algoritmi di apprendimento automatico in grado di fornire efficienza e precisione sia per problemi di regressione che di classificazione.
Se sogni di intraprendere una carriera nel campo dell'apprendimento automatico, allora la Support Vector Machine dovrebbe far parte del tuo arsenale di apprendimento. In upGrad , crediamo nel fornire ai nostri studenti i migliori algoritmi di apprendimento automatico per iniziare la loro carriera. Ecco cosa pensiamo possa aiutarti a iniziare con l' algoritmo SVM nell'apprendimento automatico.
Sommario
Che cos'è un algoritmo della macchina vettoriale di supporto?
SVM è un tipo di algoritmo di apprendimento supervisionato che è diventato molto popolare nel 2020 e continuerà ad esserlo in futuro. La storia di SVM risale al 1990; è tratto dalla teoria dell'apprendimento statistico di Vapnik. SVM può essere utilizzato sia per le sfide di regressione che di classificazione; tuttavia, viene utilizzato principalmente per affrontare le sfide di classificazione.
SVM è un classificatore discriminativo che crea iperpiani nello spazio N-dimensionale, dove n è il numero di caratteristiche in un set di dati per aiutare a discriminare i futuri input di dati. Sembra confuso, non ti preoccupare, lo capiremo in termini semplici.

Come funziona un algoritmo della macchina vettoriale di supporto?
Prima di approfondire il funzionamento di una SVM, comprendiamo alcune delle terminologie chiave.
Iperpiano
Gli iperpiani, a volte indicati anche come confini decisionali o piani decisionali, sono i confini che aiutano a classificare i punti dati. Il lato dell'iperpiano, dove cade un nuovo punto dati, può essere segregato o attribuito a classi diverse. La dimensione dell'iperpiano dipende dal numero di caratteristiche attribuite a un set di dati. Se il set di dati ha 2 funzioni, l'iperpiano può essere una linea semplice. Quando un set di dati ha 3 caratteristiche, l'iperpiano è un piano bidimensionale.
Supportare i vettori
I vettori di supporto sono i punti dati più vicini all'iperpiano e ne influenzano la posizione. Poiché questi vettori influenzano il posizionamento dell'iperpiano, sono chiamati vettori di supporto e da qui il nome Support Vector Machine Algorithm.
Margine
In parole povere, il margine è lo spazio tra l'iperpiano e i vettori di supporto. SVM sceglie sempre l'iperpiano che massimizza il margine. Maggiore è il margine, maggiore è la precisione dei risultati. Esistono due tipi di margini utilizzati negli algoritmi SVM , hard e soft.
Quando il set di dati di addestramento è separabile linearmente, SVM può semplicemente selezionare due linee parallele che massimizzano la distanza marginale; questo è chiamato un margine duro. Quando il set di dati di addestramento non è completamente separato in modo lineare, l'SVM consente una violazione del margine. Consente ad alcuni punti dati di rimanere sul lato sbagliato dell'iperpiano o tra il margine e l'iperpiano in modo che l'accuratezza non sia compromessa; questo è chiamato margine morbido.
Ci possono essere molti possibili iperpiani per un dato set di dati. L'obiettivo di VSM è selezionare il margine massimo per classificare i nuovi punti dati in classi diverse. Quando viene aggiunto un nuovo punto dati, la SVM determina da quale lato dell'iperpiano cade il punto dati. In base al lato dell'iperpiano in cui cade il nuovo punto dati, SVM lo classifica quindi in classi diverse.
Leggi: Algebra lineare per l'apprendimento automatico: concetti critici, perché imparare prima di ML
Quali sono i tipi di macchine vettoriali di supporto?
Sulla base del set di dati di addestramento, l' algoritmo SVM s può essere di due tipi:
SVM lineare
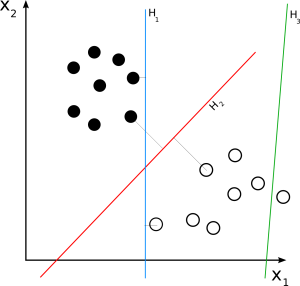
Fonte
SVM lineare viene utilizzato per un set di dati separabile linearmente. Un semplice esempio del mondo reale può aiutarci a comprendere il funzionamento di una SVM lineare. Considera un set di dati che ha una singola caratteristica, il peso di una persona. I punti dati possono essere classificati in due classi, obesi o non obesi. Per classificare i punti dati in queste due classi, SVM può creare un iperpiano di margine massimo con l'aiuto dei vettori di supporto più vicini. Ora, ogni volta che viene aggiunto un nuovo punto dati, l'SVM rileverà il lato dell'iperpiano, dove cade, e classificherà la persona come obesa o meno.
SVM non lineare
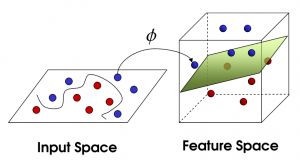
Fonte
Con l'aumento del numero di funzionalità, la separazione lineare del set di dati diventa difficile. È qui che viene utilizzata una SVM non lineare. Non possiamo tracciare una linea retta per separare i punti dati quando il set di dati non è separabile linearmente. Quindi, per separare questi punti dati, SVM aggiunge un'altra dimensione. La nuova dimensione z può essere calcolata come z = x2 + Y2. Questo calcolo aiuterà a separare le caratteristiche di un set di dati in forma lineare, quindi SVM può creare l'iperpiano per classificare i punti dati.
Quando un punto dati viene trasformato in uno spazio di dimensione elevata aggiungendo una nuova dimensione, diventa facilmente separabile con un iperpiano. Questo viene fatto con l'aiuto di quello che viene chiamato il trucco del kernel. Con il trucco del kernel, gli algoritmi SVM possono trasformare i dati non separabili in dati separabili.
Che cos'è un kernel?
Un kernel è una funzione che prende input di dimensioni ridotte e li trasforma in uno spazio di dimensioni elevate. Viene anche definito parametro di ottimizzazione che aiuta ad aumentare la precisione delle uscite SVM. Eseguono alcune trasformazioni di dati complesse per convertire il set di dati non separabile in uno separabile.
Fonte
Quali sono i diversi tipi di kernel SVM?
Kernel lineare
Come suggerisce il nome, il kernel lineare viene utilizzato per set di dati separabili linearmente. Viene utilizzato principalmente per set di dati con un gran numero di funzionalità, ad esempio la classificazione del testo, in cui tutti gli alfabeti sono una nuova funzionalità. La sintassi del kernel lineare è:

K(x, y) = somma(x*y)
xey nella sintassi sono due vettori.
L'addestramento di una SVM con un kernel lineare è più veloce dell'addestramento con qualsiasi altro kernel poiché richiede l'ottimizzazione del solo parametro di regolarizzazione C e non del parametro gamma.
Kernel polinomiale
Il kernel polinomiale è una forma più generalizzata del kernel lineare utile nella trasformazione di set di dati non lineari. La formula del kernel polinomiale è la seguente:
K(x, y) = (xT*y + c)d
Qui xey sono due vettori, c è una costante che consente il compromesso tra termini di dimensione superiore e inferiore e d è l'ordine del kernel. Lo sviluppatore dovrebbe decidere manualmente l'ordine del kernel nell'algoritmo.
Kernel della funzione di base radiale
Il kernel della funzione di base radiale, noto anche come kernel gaussiano, è un kernel ampiamente utilizzato negli algoritmi SVM per risolvere i problemi di classificazione. Ha il potenziale per mappare i dati di input in spazi indefiniti ad alta dimensione. Il kernel della funzione di base radiale può essere rappresentato matematicamente come:
K(x, y) = exp(-gamma*sum(x – y2))
Qui, xey sono due vettori e gamma è un parametro di ottimizzazione che va da 0 a 1. Gamma è predefinito manualmente nell'algoritmo di apprendimento.
Le funzioni di base lineare, polinomiale e radiale differiscono nel loro approccio matematico per prendere le decisioni e l'accuratezza della creazione dell'iperpiano. I kernel lineari e polinomiali consumano meno tempo nell'addestramento ma forniscono meno precisione. D'altra parte, il kernel della funzione di base radiale richiede più tempo nell'addestramento ma fornisce una maggiore precisione in termini di risultati.
Ora la domanda che sorge è come scegliere quale kernel usare per il tuo set di dati. La tua decisione dovrebbe dipendere esclusivamente dalla complessità del set di dati e dall'accuratezza dei risultati desiderati. Ovviamente, tutti vogliono risultati di alta precisione, ma dipende anche dal tempo che hai a disposizione per sviluppare la soluzione e da quanto puoi spenderci. Inoltre, il kernel della funzione di base radiale generalmente fornisce una maggiore precisione, ma in alcune circostanze i kernel lineare e polinomiale possono funzionare ugualmente bene.
Ad esempio, per i dati separabili linearmente, un kernel lineare funzionerà così come un kernel a base radiale e consumando meno tempo di addestramento. Quindi, se il tuo set di dati è separabile linearmente, dovresti scegliere un kernel lineare. Per i dati non lineari, dovresti scegliere una funzione di base polinomiale o radiale a seconda del tempo e delle spese che hai.
Quali sono i parametri di ottimizzazione utilizzati con i kernel?
regolarizzazione C
Il parametro di regolarizzazione C accetta i tuoi valori per consentire un certo livello di classificazione errata in ogni set di dati di addestramento. Valori di regolarizzazione C più alti portano a un iperpiano di piccolo margine e non consentono molti errori di classificazione. Valori più bassi, d'altra parte, portano a margini elevati ea una maggiore classificazione errata.
Gamma
Il parametro gamma definisce la gamma di vettori di supporto che influenzeranno il posizionamento dell'iperpiano. Il valore gamma alto considera solo i punti dati vicini e il valore basso considera i punti lontani.
Come implementare l'algoritmo della macchina vettoriale di supporto in Python?

Fonte
Dal momento che abbiamo l'idea di base di cosa sia l' algoritmo SVM e come funziona, analizziamo qualcosa di più complesso. Ora esamineremo i passaggi generali per implementare ed eseguire l' algoritmo SVM in Python. Useremo la libreria Scikit-Learn di Python per imparare come implementare l' algoritmo SVM.
Innanzitutto, dobbiamo importare tutte le librerie necessarie come Pandas e NumPy necessarie per eseguire gli algoritmi SVM. Una volta che abbiamo tutte le librerie sul posto, dobbiamo importare il set di dati di addestramento. Successivamente, dobbiamo analizzare il nostro set di dati. Esistono diversi modi per analizzare un set di dati.
Ad esempio, possiamo controllare le dimensioni dei dati, dividerli in variabili di risposta e esplicative e impostare KPI per analizzare il nostro set di dati. Dopo aver completato l'analisi dei dati, dobbiamo pre-elaborare il set di dati. Dovremmo verificare la presenza di dati irrilevanti, incompleti e errati nel nostro set di dati.
Ora arriva la parte dell'allenamento. Dobbiamo codificare e addestrare il nostro algoritmo con il kernel pertinente. Scikit-Learn contiene la libreria SVM, dove puoi trovare alcune classi integrate per l'addestramento degli algoritmi. La libreria SVM contiene una classe SVC che accetta il valore per il tipo di kernel che si desidera utilizzare per addestrare gli algoritmi.
Quindi chiami il metodo fit della classe SVC che addestra il tuo algoritmo, inserito come parametro nel metodo fit. È quindi necessario utilizzare il metodo predict della classe SVC per fare previsioni per l'algoritmo. Una volta completato il passaggio di previsione, è necessario chiamare il reporting_report e il confusion_matrix della libreria delle metriche per valutare il tuo algoritmo e vedere il risultato.
Quali sono le applicazioni dell'algoritmo Support Vector Machine?
Gli algoritmi SVM hanno applicazioni in varie sfide di regressione e classificazione. Alcune delle applicazioni chiave degli algoritmi SVM sono:
- Classificazione di testi e ipertesti
- Classificazione delle immagini
- Classificazione dei dati satellitari come il radar ad apertura sintetica (SAR)
- Classificazione di sostanze biologiche come le proteine
- Riconoscimento dei caratteri nel testo scritto a mano
Perché utilizzare l'algoritmo della macchina vettoriale di supporto?
L'algoritmo SVM offre vari vantaggi come:
- Efficace nella separazione dei dati non lineari
- Altamente preciso sia negli spazi dimensionali inferiori che superiori
- Immune al problema dell'overfitting poiché i vettori di supporto influiscono solo sulla posizione dell'iperpiano.
Dai un'occhiata: 6 tipi di funzione di attivazione nelle reti neurali che devi conoscere
Riassumendo
Abbiamo esaminato in dettaglio l' algoritmo Support Vector Machine in questo articolo. Abbiamo appreso dell'algoritmo SVM , di come funziona, dei suoi tipi, applicazioni, vantaggi e implementazione in Python. Questo articolo ti darà un'idea di base sull'algoritmo SVM e risponderà ad alcune delle tue domande.
Ma porterà anche alcune altre domande come come l' algoritmo SVM sa qual è l'iperpiano giusto, quali sono le altre librerie disponibili in Python e dove trovare il set di dati di addestramento? Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Stato di ex alunni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Quali sono i limiti dell'utilizzo di algoritmi di macchine vettoriali di supporto nell'apprendimento automatico?
Il metodo SVM non è consigliato per set di dati di grandi dimensioni. Dobbiamo selezionare un kernel ideale per SVM, che è un processo impegnativo. Inoltre, SVM ha prestazioni scadenti quando il numero di campioni di dati di addestramento è inferiore al numero di funzionalità in ciascun set di dati. Poiché la macchina del vettore di supporto non è un modello probabilistico, non siamo in grado di spiegare la classificazione in termini di probabilità. Inoltre, la complessità algoritmica e i requisiti di memoria di SVM sono piuttosto elevati.
In che modo i modelli SVM lineari e non lineari sono diversi l'uno dall'altro?
Nel caso dei modelli lineari, i dati possono essere facilmente classificati tracciando una linea retta, cosa che non è il caso dei modelli di macchine vettoriali di supporto non lineari. Le SVM lineari sono più veloci da addestrare rispetto alle SVM non lineari. Un algoritmo SVM lineare presuppone la separabilità lineare per ciascun punto dati. Mentre si trova in una SVM non lineare, il software trasforma i vettori di dati utilizzando la migliore funzione del kernel non lineare per la circostanza data.
Che ruolo gioca il parametro C in SVM?
In SVM, il parametro C rappresenta il grado di accuratezza nella classificazione che l'algoritmo deve raggiungere. In breve, il parametro C determina quanto vuoi penalizzare il tuo modello per ogni punto classificato erroneamente su una certa curva. Un C basso smussa la superficie decisionale, mentre un C alto cerca di classificare accuratamente tutte le istanze di addestramento consentendo al modello di scegliere più campioni come vettori di supporto.