
Mendukung Algoritma Mesin Vektor dalam Pembelajaran Mesin
Diterbitkan: 2020-08-14Semua yang Perlu Anda Ketahui tentang Algoritma Support Vector Machine
Kebanyakan pemula, dalam hal pembelajaran mesin, mulai dengan algoritma regresi dan klasifikasi secara alami. Algoritma ini sederhana dan mudah diikuti. Namun, penting untuk melampaui dua algoritme pembelajaran mesin ini untuk memahami konsep pembelajaran mesin dengan lebih baik.
Masih banyak lagi yang harus dipelajari dalam pembelajaran mesin, yang mungkin tidak sesederhana regresi dan klasifikasi, tetapi dapat membantu kita memecahkan berbagai masalah kompleks. Izinkan kami memperkenalkan Anda pada salah satu algoritme tersebut, Algoritma Support Vector Machine . Mendukung algoritma Vector Machine , atau algoritma SVM , biasanya disebut sebagai salah satu algoritma pembelajaran mesin yang dapat memberikan efisiensi dan akurasi untuk masalah regresi dan klasifikasi.
Jika Anda bermimpi mengejar karir di bidang pembelajaran mesin, maka Mesin Vektor Dukungan harus menjadi bagian dari gudang pembelajaran Anda. Di upGrad , kami percaya dalam membekali siswa kami dengan algoritme pembelajaran mesin terbaik untuk memulai karir mereka. Inilah yang menurut kami dapat membantu Anda memulai dengan algoritme SVM dalam pembelajaran mesin.
Daftar isi
Apa itu Algoritma Support Vector Machine?
SVM adalah jenis algoritma pembelajaran terawasi yang telah menjadi sangat populer di tahun 2020 dan akan terus begitu di masa depan. Sejarah SVM dimulai pada tahun 1990; itu diambil dari teori belajar statistik Vapnik. SVM dapat digunakan untuk tantangan regresi dan klasifikasi; namun, sebagian besar digunakan untuk mengatasi tantangan klasifikasi.
SVM adalah pengklasifikasi diskriminatif yang menciptakan hyperplanes dalam ruang dimensi-N, di mana n adalah jumlah fitur dalam kumpulan data untuk membantu membedakan input data di masa mendatang. Kedengarannya membingungkan bukan, jangan khawatir, kami akan memahaminya dalam istilah awam yang sederhana.

Bagaimana Algoritma Support Vector Machine Bekerja?
Sebelum mempelajari lebih dalam tentang cara kerja SVM, mari kita pahami beberapa istilah kunci.
Hyperplane
Hyperplanes, yang juga kadang-kadang disebut sebagai batas keputusan atau bidang keputusan, adalah batas yang membantu mengklasifikasikan titik data. Sisi hyperplane, di mana titik data baru jatuh, dapat dipisahkan atau dikaitkan ke kelas yang berbeda. Dimensi hyperplane tergantung pada jumlah fitur yang diatribusikan ke dataset. Jika dataset memiliki 2 fitur, maka hyperplane dapat berupa garis sederhana. Ketika sebuah dataset memiliki 3 fitur, maka hyperplane tersebut merupakan bidang 2 dimensi.
Mendukung Vektor
Support vector adalah titik data yang paling dekat dengan hyperplane dan mempengaruhi posisinya. Karena vektor-vektor ini mempengaruhi pemosisian hyperplane, vektor-vektor ini disebut sebagai vektor pendukung dan oleh karena itu dinamakan Algoritma Mesin Vektor Pendukung.
Batas
Sederhananya, margin adalah celah antara hyperplane dan support vector. SVM selalu memilih hyperplane yang memaksimalkan margin. Semakin besar margin, semakin tinggi akurasi hasil. Ada dua jenis margin yang digunakan dalam algoritma SVM , yaitu hard dan soft.
Ketika dataset pelatihan dapat dipisahkan secara linier, SVM dapat dengan mudah memilih dua garis paralel yang memaksimalkan jarak marginal; ini disebut margin keras. Ketika dataset pelatihan tidak sepenuhnya terpisah secara linier, maka SVM mengizinkan beberapa pelanggaran margin. Hal ini memungkinkan beberapa titik data untuk tetap berada di sisi yang salah dari hyperplane atau antara margin dan hyperplane sehingga akurasi tidak terganggu; ini disebut margin lunak.
Ada banyak kemungkinan hyperplanes untuk dataset tertentu. Tujuan dari VSM adalah untuk memilih margin yang paling maksimal untuk mengklasifikasikan titik data baru ke dalam kelas yang berbeda. Ketika titik data baru ditambahkan, SVM menentukan sisi mana dari hyperplane titik data tersebut jatuh. Berdasarkan sisi hyperplane tempat titik data baru berada, SVM kemudian mengklasifikasikannya ke dalam kelas yang berbeda.
Baca: Aljabar Linier untuk Machine Learning: Konsep Kritis, Mengapa Belajar Sebelum ML
Apa saja Jenis Support Vector Machines?
Berdasarkan dataset pelatihan, algoritma SVM dapat terdiri dari dua jenis:
SVM linier
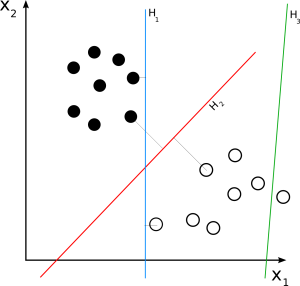
Sumber
SVM linier digunakan untuk kumpulan data yang dapat dipisahkan secara linier. Contoh dunia nyata yang sederhana dapat membantu kita memahami cara kerja SVM linier. Pertimbangkan kumpulan data yang memiliki satu fitur, bobot seseorang. Titik-titik data tersebut dapat diklasifikasikan menjadi dua kelas, obesitas atau tidak obesitas. Untuk mengklasifikasikan titik data ke dalam dua kelas ini, SVM dapat membuat hyperplane margin maksimal dengan bantuan support vector terdekat. Sekarang, setiap kali titik data baru ditambahkan, SVM akan mendeteksi sisi hyperplane, di mana ia jatuh, dan mengklasifikasikan orang tersebut sebagai obesitas atau tidak.
SVM Non-Linier
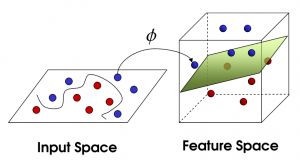
Sumber
Saat jumlah fitur meningkat, memisahkan dataset secara linier menjadi tantangan. Di situlah SVM non-linear digunakan. Kami tidak dapat menggambar garis lurus untuk memisahkan titik data ketika kumpulan data tidak dapat dipisahkan secara linier. Jadi untuk memisahkan titik data ini, SVM menambahkan dimensi lain. Dimensi baru z dapat dihitung sebagai z = x2 + Y2. Perhitungan ini akan membantu memisahkan fitur dari dataset dalam bentuk linier, dan kemudian SVM dapat membuat hyperplane untuk mengklasifikasikan titik data.
Ketika titik data diubah menjadi ruang berdimensi tinggi dengan menambahkan dimensi baru, titik tersebut menjadi mudah dipisahkan dengan hyperplane. Ini dilakukan dengan bantuan apa yang disebut trik kernel. Dengan trik kernel, algoritma SVM dapat mengubah data yang tidak dapat dipisahkan menjadi data yang dapat dipisahkan.
Apa itu Kernel?
Kernel adalah fungsi yang mengambil input berdimensi rendah dan mengubahnya menjadi ruang berdimensi tinggi. Ini juga disebut sebagai parameter penyetelan yang membantu meningkatkan akurasi keluaran SVM. Mereka melakukan beberapa transformasi data yang kompleks untuk mengubah dataset yang tidak dapat dipisahkan menjadi yang dapat dipisahkan.
Sumber
Apa saja Jenis Kernel SVM yang Berbeda?
Kernel Linier
Seperti namanya, kernel linier digunakan untuk kumpulan data yang dapat dipisahkan secara linier. Ini sebagian besar digunakan untuk kumpulan data dengan sejumlah besar fitur, klasifikasi teks, misalnya, di mana semua huruf adalah fitur baru. Sintaks kernel linier adalah:

K(x, y) = jumlah(x*y)
x dan y dalam sintaks adalah dua vektor.
Melatih SVM dengan kernel linier lebih cepat daripada melatihnya dengan kernel lain karena hanya memerlukan optimasi parameter regularisasi C dan bukan parameter gamma.
Kernel Polinomial
Kernel polinomial adalah bentuk yang lebih umum dari kernel linier yang berguna dalam mentransformasi dataset non-linear. Rumus kernel polinomial adalah sebagai berikut:
K(x, y) = (xT*y + c)d
Di sini x dan y adalah dua vektor, c adalah konstanta yang memungkinkan tradeoff untuk istilah dimensi yang lebih tinggi dan lebih rendah, dan d adalah urutan kernel. Pengembang seharusnya memutuskan urutan kernel secara manual dalam algoritma.
Kernel Fungsi Basis Radial
Kernel fungsi basis radial, juga disebut sebagai kernel Gaussian, adalah kernel yang banyak digunakan dalam algoritma SVM untuk memecahkan masalah klasifikasi. Ini memiliki potensi untuk memetakan data input ke dalam ruang dimensi tinggi yang tidak terbatas. Kernel fungsi basis radial dapat direpresentasikan secara matematis sebagai:
K(x, y) = exp(-gamma*sum(x – y2))
Di sini, x dan y adalah dua vektor, dan gamma adalah parameter penyetelan mulai dari 0 hingga 1. Gamma telah ditentukan sebelumnya secara manual dalam algoritma pembelajaran.
Fungsi basis linier, polinomial, dan radial berbeda dalam pendekatan matematisnya untuk membuat keputusan dan akurasi pembuatan hyperplane. Kernel linier dan polinomial menghabiskan lebih sedikit waktu dalam pelatihan tetapi memberikan akurasi yang lebih rendah. Di sisi lain, kernel fungsi basis radial membutuhkan lebih banyak waktu dalam pelatihan tetapi memberikan akurasi yang lebih tinggi dalam hal hasil.
Sekarang pertanyaan yang muncul adalah bagaimana memilih kernel yang akan digunakan untuk dataset Anda. Keputusan Anda seharusnya hanya bergantung pada kompleksitas kumpulan data dan keakuratan hasil yang Anda inginkan. Tentu saja, semua orang menginginkan hasil dengan akurasi tinggi, tetapi itu juga tergantung pada waktu yang Anda miliki untuk mengembangkan solusi dan berapa banyak yang dapat Anda habiskan untuk itu. Juga, kernel fungsi basis radial umumnya memberikan akurasi yang lebih tinggi, tetapi dalam beberapa keadaan, kernel linier dan polinomial dapat bekerja dengan baik.
Misalnya, untuk data yang dapat dipisahkan secara linier, kernel linier akan bekerja sebaik kernel basis radial dan memakan waktu pelatihan yang lebih sedikit. Jadi, jika dataset Anda dapat dipisahkan secara linier, Anda harus memilih kernel linier. Untuk data non-linier, Anda harus memilih fungsi basis polinomial atau radial tergantung pada waktu dan biaya yang Anda miliki.
Apa Parameter Penyetelan yang Digunakan dengan Kernel?
C regularisasi
Parameter regularisasi C menerima nilai dari Anda untuk memungkinkan tingkat kesalahan klasifikasi tertentu di setiap set data pelatihan. Nilai regularisasi C yang lebih tinggi menyebabkan hyperplane margin kecil dan tidak memungkinkan banyak kesalahan klasifikasi. Nilai yang lebih rendah, di sisi lain, menyebabkan margin tinggi dan kesalahan klasifikasi yang lebih besar.
Gamma
Parameter gamma menentukan kisaran vektor pendukung yang akan memengaruhi pemosisian hyperplane. Nilai gamma tinggi hanya mempertimbangkan titik data terdekat, dan nilai rendah mempertimbangkan titik jauh.
Bagaimana Menerapkan Algoritma Support Vector Machine dengan Python?

Sumber
Karena kita memiliki ide dasar tentang apa itu algoritma SVM dan bagaimana cara kerjanya, mari kita mempelajari sesuatu yang lebih kompleks. Sekarang kita akan melihat langkah-langkah umum untuk mengimplementasikan dan menjalankan algoritma SVM dengan Python. Kami akan menggunakan pustaka Scikit-Learn Python untuk mempelajari cara mengimplementasikan algoritme SVM.
Pertama dan terpenting, kita harus mengimpor semua perpustakaan yang diperlukan seperti Pandas dan NumPy yang diperlukan untuk menjalankan algoritma SVM. Setelah kita memiliki semua perpustakaan di tempat, kita harus mengimpor dataset pelatihan. Selanjutnya, kita harus menganalisis dataset kita. Ada beberapa cara untuk menganalisis kumpulan data.
Misalnya, kita dapat memeriksa dimensi data, membaginya menjadi variabel respons dan penjelas, dan menetapkan KPI untuk menganalisis kumpulan data kita. Setelah menyelesaikan analisis data, kita harus melakukan pra-proses dataset. Kami harus memeriksa data yang tidak relevan, tidak lengkap, dan salah dalam kumpulan data kami.
Sekarang sampai pada bagian pelatihan. Kita harus membuat kode dan melatih algoritma kita dengan kernel yang relevan. Scikit-Learn berisi perpustakaan SVM, tempat Anda dapat menemukan beberapa kelas bawaan untuk algoritme pelatihan. Pustaka SVM berisi kelas SVC yang menerima nilai untuk tipe kernel yang ingin Anda gunakan untuk melatih algoritme Anda.
Kemudian Anda memanggil metode fit dari kelas SVC yang melatih algoritme Anda, yang dimasukkan sebagai parameter ke metode fit. Anda kemudian harus menggunakan metode prediksi kelas SVC untuk membuat prediksi untuk algoritme. Setelah Anda menyelesaikan langkah prediksi, Anda harus memanggil klasifikasi_laporan dan matriks_kebingungan dari pustaka metrik untuk mengevaluasi algoritme Anda dan melihat hasilnya.
Apa Aplikasi dari algoritma Support Vector Machine?
Algoritma SVM memiliki aplikasi di berbagai regresi dan tantangan klasifikasi. Beberapa aplikasi kunci dari algoritma SVM adalah:
- Klasifikasi teks dan hypertext
- Klasifikasi gambar
- Klasifikasi data satelit seperti Synthetic-Aperture Radar (SAR)
- Mengklasifikasikan zat biologis seperti protein
- Pengenalan karakter dalam teks tulisan tangan
Mengapa Menggunakan Algoritma Support Vector Machine?
Algoritma SVM menawarkan berbagai keuntungan seperti:
- Efektif dalam memisahkan data non-linier
- Sangat akurat di ruang dimensi yang lebih rendah dan lebih tinggi
- Kebal terhadap masalah overfitting karena vektor pendukung hanya berdampak pada posisi hyperplane.
Simak: 6 Jenis Fungsi Aktivasi di Jaringan Syaraf Tiruan yang Perlu Anda Ketahui
Menyimpulkan
Kami telah melihat Algoritma Mesin Vektor Dukungan dalam artikel ini secara rinci. Kami belajar tentang algoritma SVM , cara kerjanya, jenisnya, aplikasi, manfaat, dan implementasinya dengan Python. Artikel ini akan memberi Anda ide dasar tentang algoritma SVM dan menjawab beberapa pertanyaan Anda.
Tapi itu juga akan membawa beberapa pertanyaan lain seperti bagaimana algoritma SVM mengetahui hyperplane yang tepat, library apa saja yang tersedia di Python, dan di mana menemukan dataset pelatihan? Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa batasan penggunaan algoritme mesin vektor dukungan dalam pembelajaran mesin?
Metode SVM tidak disarankan untuk kumpulan data yang besar. Kita harus memilih kernel yang ideal untuk SVM, yang merupakan proses yang menantang. Selanjutnya, SVM berkinerja buruk ketika jumlah sampel data pelatihan lebih kecil dari jumlah fitur di setiap kumpulan data. Karena mesin vektor pendukung bukan model probabilistik, kami tidak dapat menjelaskan klasifikasi dalam hal probabilitas. Selain itu, kompleksitas algoritme dan persyaratan memori SVM cukup tinggi.
Bagaimana model SVM linier dan non-linier berbeda satu sama lain?
Dalam kasus model linier, data dapat dengan mudah diklasifikasikan dengan menggambar garis lurus, yang tidak terjadi pada model mesin vektor pendukung non-linier. SVM linier lebih cepat dilatih jika dibandingkan dengan SVM non-linier. Algoritme SVM linier mengandaikan keterpisahan linier untuk setiap titik data. Sementara dalam SVM non-linier, perangkat lunak mengubah vektor data menggunakan fungsi kernel nonlinier terbaik untuk keadaan tertentu.
Apa peran parameter C di SVM?
Dalam SVM, parameter C mewakili tingkat akurasi dalam klasifikasi yang harus dicapai oleh algoritma. Singkatnya, parameter C menentukan seberapa besar Anda ingin menghukum model Anda untuk setiap titik yang salah diklasifikasikan pada kurva tertentu. C rendah memperhalus permukaan keputusan, sedangkan C tinggi berusaha untuk secara akurat mengkategorikan semua contoh pelatihan dengan memungkinkan model untuk memilih lebih banyak sampel sebagai vektor pendukung.