
دعم خوارزمية آلة المتجهات في التعلم الآلي
نشرت: 2020-08-14كل ما تحتاج لمعرفته حول دعم خوارزميات آلة المتجهات
يبدأ معظم المبتدئين ، عندما يتعلق الأمر بالتعلم الآلي ، بخوارزميات الانحدار والتصنيف بشكل طبيعي. هذه الخوارزميات بسيطة وسهلة المتابعة. ومع ذلك ، من الضروري تجاوز هاتين الخوارزميتين للتعلم الآلي لفهم مفاهيم التعلم الآلي بشكل أفضل.
هناك الكثير لنتعلمه في التعلم الآلي ، والذي قد لا يكون بسيطًا مثل الانحدار والتصنيف ، ولكن يمكن أن يساعدنا في حل العديد من المشكلات المعقدة. دعنا نقدم لك إحدى هذه الخوارزمية ، وهي خوارزمية Support Vector Machine . عادةً ما يشار إلى خوارزمية Support Vector Machine ، أو خوارزمية SVM ، على أنها واحدة من خوارزمية التعلم الآلي التي يمكن أن توفر الكفاءة والدقة لكل من مشاكل الانحدار والتصنيف.
إذا كنت تحلم بممارسة مهنة في مجال التعلم الآلي ، فيجب أن تكون Support Vector Machine جزءًا من ترسانة التعلم الخاصة بك. في upGrad ، نؤمن بتزويد طلابنا بأفضل خوارزميات التعلم الآلي لبدء حياتهم المهنية. إليك ما نعتقد أنه يمكن أن يساعدك في البدء باستخدام خوارزمية SVM في التعلم الآلي.
جدول المحتويات
ما هي خوارزمية آلة المتجهات الداعمة؟
SVM هو نوع من خوارزمية التعلم الخاضع للإشراف التي أصبحت شائعة جدًا في عام 2020 وستظل كذلك في المستقبل. يعود تاريخ SVM إلى عام 1990 ؛ إنه مستمد من نظرية التعلم الإحصائي لـ Vapnik. يمكن استخدام SVM لكل من تحديات الانحدار والتصنيف ؛ ومع ذلك ، فإنه يستخدم في الغالب لمعالجة تحديات التصنيف.
SVM عبارة عن مصنف تمييزي يقوم بإنشاء طائرات مفرطة في فضاء N-dimensional ، حيث n هو عدد الميزات في مجموعة بيانات للمساعدة في تمييز مدخلات البيانات المستقبلية. يبدو محيرًا بشكل صحيح ، لا تقلق ، سوف نفهمه بعبارات بسيطة.

كيف تعمل خوارزمية دعم آلة المتجهات؟
قبل الخوض في عمل SVM ، دعونا نفهم بعض المصطلحات الأساسية.
الطائرة المفرطة
الطائرات الفائقة ، التي يشار إليها أحيانًا باسم حدود القرار أو مستويات القرار ، هي الحدود التي تساعد في تصنيف نقاط البيانات. يمكن فصل جانب الطائرة الفائقة ، حيث تقع نقطة بيانات جديدة ، أو نسبته إلى فئات مختلفة. يعتمد بُعد المستوى الفائق على عدد الميزات المنسوبة إلى مجموعة البيانات. إذا كانت مجموعة البيانات تحتوي على ميزتين ، فيمكن أن يكون المستوى الفائق سطرًا بسيطًا. عندما تحتوي مجموعة البيانات على 3 ميزات ، فإن المستوى الفائق هو مستوى ثنائي الأبعاد.
ناقلات الدعم
متجهات الدعم هي نقاط البيانات الأقرب إلى المستوى الفائق وتؤثر على موضعها. نظرًا لأن هذه المتجهات تؤثر على وضع الطائرة الفائقة ، فقد تم تسميتها على أنها متجهات دعم ومن ثم اسم Support Vector Machine Algorithm.
حافة
ببساطة ، الهامش هو الفجوة بين المستوي الفائق ومتجهات الدعم. يختار SVM دائمًا المستوى الفائق الذي يعمل على تكبير الهامش. كلما زاد الهامش ، زادت دقة النتائج. هناك نوعان من الهوامش المستخدمة في خوارزميات SVM ، الثابت واللين.
عندما تكون مجموعة بيانات التدريب قابلة للفصل خطيًا ، يمكن لـ SVM ببساطة تحديد خطين متوازيين يزيدان المسافة الهامشية إلى أقصى حد ؛ هذا يسمى الهامش الصعب. عندما لا تكون مجموعة بيانات التدريب منفصلة بشكل خطي تمامًا ، فإن SVM يسمح ببعض انتهاكات الهامش. يسمح لبعض نقاط البيانات بالبقاء على الجانب الخطأ من المستوى الفائق أو بين الهامش والمستوى الفائق بحيث لا يتم المساس بالدقة ؛ هذا يسمى الهامش الناعم.
يمكن أن يكون هناك العديد من المستويات العالية المحتملة لمجموعة بيانات معينة. الهدف من VSM هو تحديد أقصى هامش لتصنيف نقاط البيانات الجديدة إلى فئات مختلفة. عند إضافة نقطة بيانات جديدة ، يحدد SVM أي جانب من المستوى الفائق تسقط نقطة البيانات. استنادًا إلى جانب المستوى الفائق حيث تقع نقطة البيانات الجديدة ، يصنفها SVM إلى فئات مختلفة.
اقرأ: الجبر الخطي لتعلم الآلة: المفاهيم الحاسمة ، لماذا نتعلم قبل تعلم الآلة
ما هي أنواع آلات المتجهات الداعمة؟
بناءً على مجموعة بيانات التدريب ، يمكن أن تكون خوارزمية SVM من نوعين:
SVM الخطي
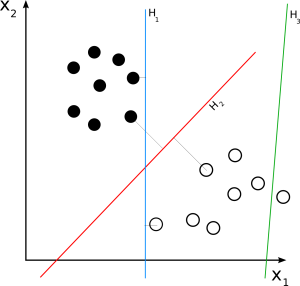
مصدر
يتم استخدام SVM الخطي لمجموعة بيانات قابلة للفصل خطيًا. يمكن أن يساعدنا مثال بسيط من العالم الحقيقي في فهم طريقة عمل SVM الخطي. ضع في اعتبارك مجموعة البيانات التي تحتوي على ميزة واحدة ، وهي وزن الشخص. يمكن تصنيف نقاط البيانات إلى فئتين ، يعانون من السمنة المفرطة أو غير البدينين. لتصنيف نقاط البيانات في هاتين الفئتين ، يمكن لـ SVM إنشاء مستوى مرتفع بهوامش قصوى بمساعدة أقرب متجهات دعم. الآن ، كلما تمت إضافة نقطة بيانات جديدة ، سيكتشف جهاز SVM جانب الطائرة الفائقة ، حيث يقع ، ويصنف الشخص على أنه بدين أم لا.
SVM غير خطي
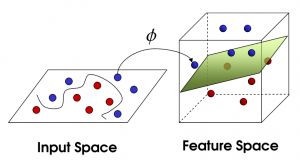
مصدر
مع زيادة عدد الميزات ، يصبح فصل مجموعة البيانات خطيًا أمرًا صعبًا. هذا هو المكان الذي يتم فيه استخدام SVM غير الخطي. لا يمكننا رسم خط مستقيم لفصل نقاط البيانات عندما لا تكون مجموعة البيانات قابلة للفصل خطيًا. لذلك ، لفصل نقاط البيانات هذه ، يضيف SVM بُعدًا آخر. يمكن حساب البعد الجديد z كـ z = x2 + Y2. سيساعد هذا الحساب في فصل ميزات مجموعة البيانات في شكل خطي ، ومن ثم يمكن لـ SVM إنشاء المستوى الفائق لتصنيف نقاط البيانات.
عندما يتم تحويل نقطة بيانات إلى مساحة عالية الأبعاد عن طريق إضافة بُعد جديد ، تصبح قابلة للفصل بسهولة باستخدام المستوى الفائق. يتم ذلك بمساعدة ما يسمى خدعة النواة. باستخدام خدعة kernel ، يمكن لخوارزميات SVM تحويل البيانات غير القابلة للفصل إلى بيانات قابلة للفصل.
ما هي النواة؟
النواة هي وظيفة تأخذ مدخلات ذات أبعاد منخفضة وتحولها إلى مساحة ذات أبعاد عالية. يشار إليه أيضًا باسم معلمة الضبط التي تساعد على زيادة دقة مخرجات SVM. يقومون بإجراء بعض تحويلات البيانات المعقدة لتحويل مجموعة البيانات غير القابلة للفصل إلى مجموعة قابلة للفصل.
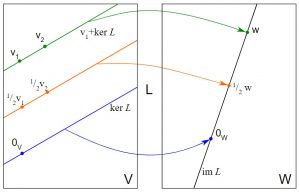
مصدر
ما هي الأنواع المختلفة لنواة SVM؟
نواة خطية
كما يوحي الاسم ، يتم استخدام النواة الخطية لمجموعات البيانات القابلة للفصل خطيًا. يتم استخدامه في الغالب لمجموعات البيانات التي تحتوي على عدد كبير من الميزات ، وتصنيف النص ، على سبيل المثال ، حيث تكون جميع الحروف الهجائية ميزة جديدة. صيغة النواة الخطية هي:

ك (س ، ص) = مجموع (س * ص)
x و y في بناء الجملة هما متجهان.
يعد تدريب SVM باستخدام نواة خطية أسرع من تدريبه مع أي نواة أخرى لأنه يتطلب تحسين معامل تنظيم C فقط وليس معلمة جاما.
نواة كثيرة الحدود
النواة متعددة الحدود هي شكل أكثر عمومية للنواة الخطية وهي مفيدة في تحويل مجموعة البيانات غير الخطية. صيغة نواة كثير الحدود هي كما يلي:
ك (س ، ص) = (س ت * ص + ج) د
هنا x و y متجهان ، c ثابت يسمح بالمقايضة لشروط البعد الأعلى والأدنى ، و d هو ترتيب النواة. من المفترض أن يقرر المطور ترتيب النواة يدويًا في الخوارزمية.
نواة دالة الأساس الشعاعي
نواة دالة الأساس الشعاعي ، يشار إليها أيضًا باسم Gaussian kernel ، هي نواة مستخدمة على نطاق واسع في خوارزميات SVM لحل مشاكل التصنيف. لديه القدرة على تعيين بيانات الإدخال في مساحات عالية الأبعاد غير محددة. يمكن تمثيل نواة دالة الأساس الشعاعي رياضيًا على النحو التالي:
K (x، y) = exp (-gamma * sum (x - y2))
هنا ، x و y متجهان ، وغاما هي معلمة ضبط تتراوح من 0 إلى 1. جاما محددة مسبقًا يدويًا في خوارزمية التعلم.
تختلف وظائف الأساس الخطي ، متعدد الحدود ، والشعاعي في نهجها الرياضي لاتخاذ قرارات إنشاء المستوي الفائق ودقته. تستهلك النواة الخطية ومتعددة الحدود وقتًا أقل في التدريب ولكنها توفر دقة أقل. من ناحية أخرى ، تستغرق نواة دالة الأساس الشعاعي مزيدًا من الوقت في التدريب ولكنها توفر دقة أعلى من حيث النتائج.
الآن السؤال الذي يطرح نفسه هو كيفية اختيار أي نواة لاستخدامها لمجموعة البيانات الخاصة بك. يجب أن يعتمد قرارك فقط على مدى تعقيد مجموعة البيانات ودقة النتائج التي تريدها. بالطبع ، يريد الجميع الحصول على نتائج عالية الدقة ، لكن ذلك يعتمد أيضًا على الوقت المتاح لك لتطوير الحل ومقدار ما يمكنك إنفاقه عليه. أيضًا ، توفر نواة دالة الأساس الشعاعي دقة أعلى بشكل عام ، ولكن في بعض الحالات ، يمكن أن تعمل النواة الخطية ومتعددة الحدود بشكل جيد.
على سبيل المثال ، بالنسبة للبيانات القابلة للفصل خطيًا ، ستعمل النواة الخطية بالإضافة إلى نواة الأساس الشعاعي مع استهلاك وقت تدريب أقل. لذلك إذا كانت مجموعة البيانات الخاصة بك قابلة للفصل خطيًا ، فيجب عليك اختيار نواة خطية. بالنسبة إلى البيانات غير الخطية ، يجب عليك اختيار دالة ذات أساس متعدد الحدود أو دالة أساس قطري حسب الوقت والمصاريف لديك.
ما هي معلمات التوليف المستخدمة مع النواة؟
ج ـ التسوية
تقبل معلمة تسوية C قيمًا منك للسماح بمستوى معين من التصنيف الخاطئ في كل مجموعة بيانات تدريب. تؤدي قيم تنظيم C الأعلى إلى مستوى فائق بهامش صغير ولا تسمح بالكثير من سوء التصنيف. من ناحية أخرى ، تؤدي القيم المنخفضة إلى هامش مرتفع وتصنيف خاطئ أكبر.
جاما
تحدد معلمة جاما نطاق متجهات الدعم التي ستؤثر على موضع المستوي الفائق. تأخذ قيمة جاما المرتفعة في الاعتبار نقاط البيانات القريبة فقط ، بينما تأخذ القيمة المنخفضة في الاعتبار النقاط البعيدة.
كيف يتم تطبيق خوارزمية دعم Vector Machine في Python؟

مصدر
نظرًا لأن لدينا فكرة أساسية عن ماهية خوارزمية SVM وكيف تعمل ، فلنتعمق في شيء أكثر تعقيدًا. الآن سنلقي نظرة على الخطوات العامة لتنفيذ وتشغيل خوارزمية SVM في Python. سنستخدم مكتبة Scikit-Learn في Python لمعرفة كيفية تنفيذ خوارزمية SVM.
أولاً وقبل كل شيء ، يتعين علينا استيراد جميع المكتبات الضرورية مثل Pandas و NumPy الضرورية لتشغيل خوارزميات SVM. بمجرد أن تكون لدينا جميع المكتبات في المكان ، يتعين علينا استيراد مجموعة بيانات التدريب. بعد ذلك ، علينا تحليل مجموعة البيانات الخاصة بنا. هناك طرق متعددة لتحليل مجموعة البيانات.
على سبيل المثال ، يمكننا التحقق من أبعاد البيانات ، وتقسيمها إلى متغيرات استجابة وتفسيرية ، وتعيين مؤشرات الأداء الرئيسية لتحليل مجموعة البيانات الخاصة بنا. بعد الانتهاء من تحليل البيانات ، يتعين علينا معالجة مجموعة البيانات مسبقًا. يجب أن نتحقق من وجود بيانات غير ملائمة وغير كاملة وغير صحيحة في مجموعة البيانات الخاصة بنا.
الآن يأتي جزء التدريب. يجب علينا ترميز وتدريب خوارزمية لدينا مع النواة ذات الصلة. يحتوي Scikit-Learn على مكتبة SVM ، حيث يمكنك العثور على بعض الفصول المضمنة لخوارزميات التدريب. تحتوي مكتبة SVM على فئة SVC تقبل قيمة نوع kernel الذي تريد استخدامه لتدريب الخوارزميات الخاصة بك.
ثم تقوم باستدعاء طريقة الملاءمة لفئة SVC التي تقوم بتدريب الخوارزمية الخاصة بك ، والتي يتم إدراجها كمعامل لطريقة الملاءمة. يجب عليك بعد ذلك استخدام طريقة التنبؤ لفئة SVC لعمل تنبؤات للخوارزمية. بمجرد الانتهاء من خطوة التنبؤ ، يجب عليك استدعاء تصنيف_التقرير و confusion_matrix لمكتبة المقاييس لتقييم الخوارزمية الخاصة بك ورؤية النتيجة.
ما هي تطبيقات خوارزمية دعم Vector Machine؟
خوارزميات SVM لها تطبيقات عبر مختلف تحديات الانحدار والتصنيف. بعض التطبيقات الرئيسية لخوارزميات SVM هي:
- تصنيف النص والنص التشعبي
- تصنيف الصورة
- تصنيف بيانات الأقمار الصناعية مثل الرادار ذو الفتحة التركيبية (SAR)
- تصنيف المواد البيولوجية مثل البروتينات
- التعرف على الحروف في نص مكتوب بخط اليد
لماذا نستخدم خوارزمية آلة المتجهات الداعمة؟
تقدم خوارزمية SVM مزايا مختلفة مثل:
- فعال في فصل البيانات غير الخطية
- دقة عالية في كل من المساحات ذات الأبعاد المنخفضة والعالية
- محصن ضد مشكلة فرط التجهيز لأن نواقل الدعم تؤثر فقط على موضع الطائرة المفرطة.
تحقق من: 6 أنواع من وظائف التنشيط في الشبكات العصبية التي تحتاج إلى معرفتها
تلخيص لما سبق
لقد ألقينا نظرة على خوارزمية Support Vector Machine في هذه المقالة بالتفصيل. تعلمنا عن خوارزمية SVM وكيف تعمل وأنواعها وتطبيقاتها وفوائدها وتنفيذها في Python. ستمنحك هذه المقالة فكرة أساسية عن خوارزمية SVM والإجابة على بعض أسئلتك.
ولكنه سيجلب أيضًا بعض الأسئلة الأخرى مثل كيف تعرف خوارزمية SVM أي المستوي الفائق الصحيح ، وما المكتبات الأخرى المتوفرة في Python ، وأين تجد مجموعة بيانات التدريب؟ إذا كنت مهتمًا بمعرفة المزيد حول التعلم الآلي ، فراجع دبلوم PG في IIIT-B & upGrad في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT- حالة الخريجين B ، أكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع أفضل الشركات.
ما هي قيود استخدام خوارزميات آلة الدعم في التعلم الآلي؟
طريقة SVM غير مستحسن لمجموعات البيانات الضخمة. يجب أن نختار نواة مثالية لـ SVM ، وهي عملية صعبة. علاوة على ذلك ، فإن أداء SVM ضعيف عندما يكون عدد عينات بيانات التدريب أقل من عدد الميزات في كل مجموعة بيانات. نظرًا لأن آلة متجه الدعم ليست نموذجًا احتماليًا ، فإننا غير قادرين على شرح التصنيف من حيث الاحتمال. علاوة على ذلك ، فإن التعقيد الحسابي ومتطلبات الذاكرة لـ SVM عالية جدًا.
كيف تختلف نماذج SVM الخطية وغير الخطية عن بعضها البعض؟
في حالة النماذج الخطية ، يمكن تصنيف البيانات بسهولة عن طريق رسم خط مستقيم ، وهذا ليس هو الحال مع نماذج آلات المتجهات غير الخطية. تعد SVMs الخطية أسرع في التدريب عند مقارنتها بـ SVMs غير الخطية. تفترض خوارزمية SVM الخطية إمكانية الفصل الخطي لكل نقطة بيانات. أثناء وجوده في SVM غير الخطي ، يقوم البرنامج بتحويل متجهات البيانات باستخدام أفضل وظيفة نواة غير خطية للظروف المحددة.
ما الدور الذي تلعبه المعلمة C في SVM؟
في SVM ، تمثل المعلمة C درجة الدقة في التصنيف التي يجب أن تحققها الخوارزمية. باختصار ، تحدد المعلمة C مقدار ما تريد معاقبة النموذج الخاص بك لكل نقطة مصنفة بشكل خاطئ على منحنى معين. يعمل المستوى C المنخفض على تلطيف سطح القرار ، بينما يسعى C المرتفع إلى تصنيف جميع حالات التدريب بدقة من خلال السماح للنموذج باختيار المزيد من العينات كمتجهات دعم.