
Suporte ao algoritmo de máquina vetorial no aprendizado de máquina
Publicados: 2020-08-14Tudo o que você precisa saber sobre algoritmos de máquina de vetor de suporte
A maioria dos iniciantes, quando se trata de aprendizado de máquina, começa com algoritmos de regressão e classificação naturalmente. Esses algoritmos são simples e fáceis de seguir. No entanto, é essencial ir além desses dois algoritmos de aprendizado de máquina para entender melhor os conceitos de aprendizado de máquina.
Há muito mais a aprender em aprendizado de máquina, que pode não ser tão simples quanto regressão e classificação, mas pode nos ajudar a resolver vários problemas complexos. Vamos apresentá-lo a um desses algoritmos, o Support Vector Machine Algorithm . O algoritmo Support Vector Machine , ou algoritmo SVM , geralmente é referido como um desses algoritmos de aprendizado de máquina que pode fornecer eficiência e precisão para problemas de regressão e classificação.
Se você sonha em seguir uma carreira no campo de aprendizado de máquina, o Support Vector Machine deve fazer parte do seu arsenal de aprendizado. Na upGrad , acreditamos em equipar nossos alunos com os melhores algoritmos de aprendizado de máquina para começar suas carreiras. Aqui está o que achamos que pode ajudá-lo a começar com o algoritmo SVM no aprendizado de máquina.
Índice
O que é um algoritmo de máquina de vetor de suporte?
O SVM é um tipo de algoritmo de aprendizado supervisionado que se tornou muito popular em 2020 e continuará sendo no futuro. A história da SVM remonta a 1990; é extraído da teoria de aprendizagem estatística de Vapnik. O SVM pode ser usado para desafios de regressão e classificação; no entanto, é usado principalmente para enfrentar os desafios de classificação.
O SVM é um classificador discriminativo que cria hiperplanos no espaço N-dimensional, onde n é o número de recursos em um conjunto de dados para ajudar a discriminar entradas de dados futuras. Parece confuso, não se preocupe, vamos entender em termos simples e leigos.

Como funciona um algoritmo de máquina de vetor de suporte?
Antes de nos aprofundarmos no funcionamento de um SVM, vamos entender algumas das principais terminologias.
Hiperplano
Os hiperplanos, às vezes também chamados de limites de decisão ou planos de decisão, são os limites que ajudam a classificar os pontos de dados. O lado do hiperplano, onde cai um novo ponto de dados, pode ser segregado ou atribuído a diferentes classes. A dimensão do hiperplano depende do número de recursos que são atribuídos a um conjunto de dados. Se o conjunto de dados tiver 2 recursos, o hiperplano poderá ser uma linha simples. Quando um conjunto de dados possui 3 recursos, o hiperplano é um plano bidimensional.
Vetores de suporte
Os vetores de suporte são os pontos de dados que estão mais próximos do hiperplano e afetam sua posição. Como esses vetores afetam o posicionamento do hiperplano, eles são chamados de vetores de suporte e daí o nome de algoritmo de máquina de vetor de suporte.
Margem
Simplificando, a margem é a lacuna entre o hiperplano e os vetores de suporte. O SVM sempre escolhe o hiperplano que maximiza a margem. Quanto maior a margem, maior é a precisão dos resultados. Existem dois tipos de margens que são usadas em algoritmos SVM , hard e soft.
Quando o conjunto de dados de treinamento é linearmente separável, o SVM pode simplesmente selecionar duas linhas paralelas que maximizam a distância marginal; isso é chamado de margem rígida. Quando o conjunto de dados de treinamento não é totalmente separado linearmente, o SVM permite alguma violação de margem. Permite que alguns pontos de dados fiquem do lado errado do hiperplano ou entre a margem e o hiperplano para que a precisão não seja comprometida; isso é chamado de margem suave.
Pode haver muitos hiperplanos possíveis para um determinado conjunto de dados. O objetivo do VSM é selecionar a margem máxima para classificar novos pontos de dados em diferentes classes. Quando um novo ponto de dados é adicionado, o SVM determina em qual lado do hiperplano o ponto de dados cai. Com base no lado do hiperplano em que o novo ponto de dados cai, o SVM o classifica em diferentes classes.
Leia: Álgebra linear para aprendizado de máquina: conceitos críticos, por que aprender antes de ML
Quais são os tipos de máquinas de vetor de suporte?
Com base no conjunto de dados de treinamento, os algoritmos SVM podem ser de dois tipos:
SVM linear
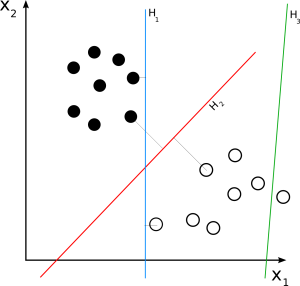
Fonte
O SVM linear é usado para um conjunto de dados linearmente separável. Um exemplo simples do mundo real pode nos ajudar a entender o funcionamento de um SVM linear. Considere um conjunto de dados que tenha um único recurso, o peso de uma pessoa. Os pontos de dados podem ser classificados em duas classes, obesos ou não obesos. Para classificar os pontos de dados nessas duas classes, o SVM pode criar um hiperplano de margem máxima com a ajuda dos vetores de suporte mais próximos. Agora, sempre que um novo ponto de dados for adicionado, o SVM detectará o lado do hiperplano, onde ele cai, e classificará a pessoa como obesa ou não.
SVM não linear
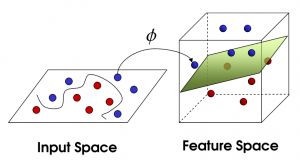
Fonte
À medida que o número de recursos aumenta, separar o conjunto de dados linearmente se torna um desafio. É aí que um SVM não linear é usado. Não podemos traçar uma linha reta para separar os pontos de dados quando o conjunto de dados não é separável linearmente. Portanto, para separar esses pontos de dados, o SVM adiciona outra dimensão. A nova dimensão z pode ser calculada como z = x2 + Y2. Esse cálculo ajudará a separar os recursos de um conjunto de dados de forma linear e, em seguida, o SVM poderá criar o hiperplano para classificar os pontos de dados.
Quando um ponto de dados é transformado em um espaço de alta dimensão adicionando uma nova dimensão, ele se torna facilmente separável com um hiperplano. Isso é feito com a ajuda do que é chamado de truque do kernel. Com o truque do kernel, os algoritmos SVM podem transformar dados não separáveis em dados separáveis.
O que é um Kernel?
Um kernel é uma função que recebe entradas de baixa dimensão e as transforma em espaço de alta dimensão. Também é referido como um parâmetro de ajuste que ajuda a aumentar a precisão das saídas SVM. Eles realizam algumas transformações de dados complexas para converter o conjunto de dados não separável em um separável.
Fonte
Quais são os diferentes tipos de kernels SVM?
Kernel Linear
Como o nome sugere, o kernel linear é usado para conjuntos de dados linearmente separáveis. É usado principalmente para conjuntos de dados com um grande número de recursos, classificação de texto, por exemplo, onde todos os alfabetos são um novo recurso. A sintaxe do kernel linear é:

K(x, y) = soma(x*y)
xey na sintaxe são dois vetores.
Treinar um SVM com um kernel linear é mais rápido do que treiná-lo com qualquer outro kernel, pois requer a otimização apenas do parâmetro de regularização C e não do parâmetro gama.
Kernel polinomial
O kernel polinomial é uma forma mais generalizada do kernel linear que é útil para transformar conjuntos de dados não lineares. A fórmula do kernel polinomial é a seguinte:
K(x, y) = (xT*y + c)d
Aqui xey são dois vetores, c é uma constante que permite a troca por termos de dimensão mais alta e mais baixa, e d é a ordem do kernel. O desenvolvedor deve decidir a ordem do kernel manualmente no algoritmo.
Kernel de função de base radial
O kernel de função de base radial, também conhecido como kernel gaussiano, é um kernel amplamente utilizado em algoritmos SVM para resolver problemas de classificação. Ele tem o potencial de mapear dados de entrada em espaços indefinidos de alta dimensão. O kernel da função de base radial pode ser representado matematicamente como:
K(x, y) = exp(-gama*soma(x – y2))
Aqui, xey são dois vetores e gamma é um parâmetro de ajuste que varia de 0 a 1. Gamma é pré-definido manualmente no algoritmo de aprendizado.
As funções de base linear, polinomial e radial diferem em sua abordagem matemática para tomar decisões e precisão na criação do hiperplano. Kernels lineares e polinomiais consomem menos tempo de treinamento, mas fornecem menos precisão. Por outro lado, o kernel da função de base radial leva mais tempo no treinamento, mas fornece maior precisão em termos de resultados.
Agora, a questão que surge é como escolher qual kernel usar para seu conjunto de dados. Sua decisão deve depender exclusivamente da complexidade do conjunto de dados e da precisão dos resultados desejados. Claro, todos querem resultados de alta precisão, mas também depende do tempo que você tem para desenvolver a solução e quanto você pode gastar com ela. Além disso, o kernel da função de base radial geralmente fornece maior precisão, mas em algumas circunstâncias, os kernels linear e polinomial podem ter um desempenho igualmente bom.
Por exemplo, para dados linearmente separáveis, um kernel linear funcionará tão bem quanto um kernel de base radial e consumirá menos tempo de treinamento. Portanto, se seu conjunto de dados for linearmente separável, você deve escolher um kernel linear. Para dados não lineares, você deve escolher uma função de base polinomial ou radial, dependendo do tempo e da despesa que você tem.
Quais são os parâmetros de ajuste usados com kernels?
Regularização C
O parâmetro de regularização C aceita valores seus para permitir um certo nível de classificação incorreta em cada conjunto de dados de treinamento. Valores de regularização C mais altos levam a um hiperplano de margem pequena e não permitem muitos erros de classificação. Valores mais baixos, por outro lado, levam a margens altas e maiores erros de classificação.
Gama
O parâmetro gamma define a faixa de vetores de suporte que irão impactar o posicionamento do hiperplano. O valor de gama alto considera apenas os pontos de dados próximos e o valor baixo considera os pontos distantes.
Como implementar o algoritmo de máquina de vetor de suporte em Python?

Fonte
Já que temos a ideia básica do que é o algoritmo SVM e como ele funciona, vamos nos aprofundar em algo mais complexo. Agora veremos as etapas gerais para implementar e executar o algoritmo SVM em Python. Usaremos a biblioteca Scikit-Learn do Python para aprender como implementar o algoritmo SVM.
Em primeiro lugar, temos que importar todas as bibliotecas necessárias, como Pandas e NumPy, necessárias para executar os algoritmos SVM. Assim que tivermos todas as bibliotecas no local, precisamos importar o conjunto de dados de treinamento. Em seguida, temos que analisar nosso conjunto de dados. Existem várias maneiras de analisar um conjunto de dados.
Por exemplo, podemos verificar as dimensões dos dados, dividi-los em variáveis de resposta e explicativas e definir KPIs para analisar nosso conjunto de dados. Depois de concluir a análise dos dados, temos que pré-processar o conjunto de dados. Devemos verificar dados irrelevantes, incompletos e incorretos em nosso conjunto de dados.
Agora vem a parte do treino. Temos que codificar e treinar nosso algoritmo com o kernel relevante. O Scikit-Learn contém a biblioteca SVM, onde você pode encontrar algumas classes internas para algoritmos de treinamento. A biblioteca SVM contém uma classe SVC que aceita o valor para o tipo de kernel que você deseja usar para treinar seus algoritmos.
Então você chama o método fit da classe SVC que treina seu algoritmo, inserido como parâmetro para o método fit. Você precisa então usar o método de previsão da classe SVC para fazer previsões para o algoritmo. Depois de concluir a etapa de previsão, você deve chamar o relatório_classificação e a matriz_confusão da biblioteca de métricas para avaliar seu algoritmo e ver o resultado.
Quais são as aplicações do algoritmo Support Vector Machine?
Os algoritmos SVM têm aplicações em vários desafios de regressão e classificação. Algumas das principais aplicações dos algoritmos SVM são:
- Classificação de texto e hipertexto
- Classificação de imagem
- Classificação de dados de satélite, como Radar de Abertura Sintética (SAR)
- Classificação de substâncias biológicas, como proteínas
- Reconhecimento de caracteres em texto escrito à mão
Por que usar o algoritmo Support Vector Machine?
O algoritmo SVM oferece vários benefícios, como:
- Eficaz na separação de dados não lineares
- Altamente preciso em espaços dimensionais inferiores e superiores
- Imune ao problema de overfitting, pois os vetores de suporte afetam apenas a posição do hiperplano.
Confira: 6 tipos de função de ativação em redes neurais que você precisa conhecer
Resumindo
Analisamos detalhadamente o algoritmo de máquina de vetor de suporte neste artigo. Aprendemos sobre o algoritmo SVM , como ele funciona, seus tipos, aplicativos, benefícios e implementação em Python. Este artigo lhe dará uma ideia básica sobre o algoritmo SVM e responderá a algumas de suas perguntas.
Mas também trará algumas outras questões, como como o algoritmo SVM sabe qual é o hiperplano certo, quais são as outras bibliotecas disponíveis em Python e onde encontrar o conjunto de dados de treinamento? Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Quais são as limitações do uso de algoritmos de máquina de vetor de suporte no aprendizado de máquina?
O método SVM não é recomendado para grandes conjuntos de dados. Devemos selecionar um kernel ideal para SVM, que é um processo desafiador. Além disso, o SVM tem um desempenho ruim quando o número de amostras de dados de treinamento é menor que o número de recursos em cada conjunto de dados. Como a máquina de vetores de suporte não é um modelo probabilístico, não podemos explicar a classificação em termos de probabilidade. Além disso, a complexidade algorítmica e os requisitos de memória do SVM são bastante altos.
Como os modelos SVM lineares e não lineares são diferentes entre si?
No caso de modelos lineares, os dados podem ser facilmente classificados traçando uma linha reta, o que não é o caso de modelos de máquinas de vetores de suporte não lineares. SVMs lineares são mais rápidos de treinar quando comparados a SVMs não lineares. Um algoritmo SVM linear pressupõe separabilidade linear para cada ponto de dados. Enquanto em um SVM não linear, o software transforma os vetores de dados usando a melhor função de kernel não linear para a circunstância dada.
Que papel o parâmetro C desempenha no SVM?
No SVM, o parâmetro C representa o grau de precisão na classificação que o algoritmo deve alcançar. Em suma, o parâmetro C determina o quanto você deseja penalizar seu modelo para cada ponto mal classificado em uma determinada curva. Um C baixo suaviza a superfície de decisão, enquanto um C alto procura categorizar com precisão todas as instâncias de treinamento, permitindo que o modelo escolha mais amostras como vetores de suporte.