
Usando Rede Neural Convolucional para Classificação de Imagens
Publicados: 2020-08-14Classificação de imagem recebe uma reforma. Obrigado à CNN.
As Redes Neurais Convolucionais (CNNs) são a espinha dorsal da classificação de imagens, um fenômeno de aprendizado profundo que pega uma imagem e atribui a ela uma classe e um rótulo que a torna única. A classificação de imagens usando CNN é uma parte significativa dos experimentos de aprendizado de máquina.
Juntamente com o uso da CNN e seus recursos induzidos, agora é amplamente usado para uma variedade de aplicativos - desde a marcação de fotos do Facebook até recomendações de produtos da Amazon e imagens de saúde para carros automáticos. A razão pela qual a CNN é tão popular é que ela requer muito pouco pré-processamento, o que significa que ela pode ler imagens 2D aplicando filtros que outros algoritmos convencionais não conseguem. Vamos nos aprofundar no processo de como funciona a classificação de imagens usando a CNN .
Índice
Como funciona a CNN?
As CNNs são equipadas com uma camada de entrada, uma camada de saída e camadas ocultas, todas as quais ajudam a processar e classificar imagens. As camadas ocultas compreendem camadas convolucionais, camadas ReLU, camadas de agrupamento e camadas totalmente conectadas, todas as quais desempenham um papel crucial. Saiba mais sobre rede neural convolucional.
Vejamos como funciona a classificação de imagens usando a CNN :
Imagine que a imagem de entrada seja a de um elefante. Esta imagem, com pixels, é inserida primeiro nas camadas convolucionais. Se for uma imagem em preto e branco, a imagem é interpretada como uma camada 2D, com cada pixel atribuído a um valor entre '0' e '255', '0' sendo totalmente preto e '255' totalmente branco. Se, por outro lado, for uma imagem colorida, ela se torna uma matriz 3D, com uma camada azul, verde e vermelha, com cada valor de cor entre 0 e 255.

Inicia-se então a leitura da matriz, para a qual o software seleciona uma imagem menor, conhecida como 'filtro' (ou kernel). A profundidade do filtro é igual à profundidade da entrada. O filtro então produz um movimento de convolução junto com a imagem de entrada, movendo-se ao longo da imagem em 1 unidade.
Em seguida, ele multiplica os valores pelos valores originais da imagem. Todos os números multiplicados são somados e um único número é gerado. O processo é repetido junto com toda a imagem, e uma matriz é obtida, menor que a imagem de entrada original.
A matriz final é chamada de mapa de recursos de um mapa de ativação. A convolução de uma imagem ajuda a realizar operações como detecção de bordas, nitidez e desfoque, aplicando diferentes filtros. Basta especificar aspectos como o tamanho do filtro, o número de filtros e/ou a arquitetura da rede.
Do ponto de vista humano, essa ação é semelhante a identificar as cores e os limites simples de uma imagem. No entanto, para classificar a imagem e reconhecer as características que a tornam, digamos, de um elefante e não de um gato, é necessário identificar características únicas como orelhas grandes e tromba do elefante. É aqui que entram as camadas não lineares e de pooling.
A camada não linear (ReLU) segue a camada de convolução, onde uma função de ativação é aplicada aos mapas de características para aumentar a não linearidade da imagem. A camada ReLU remove todos os valores negativos e aumenta a precisão da imagem. Embora existam outras operações como tanh ou sigmoid, o ReLU é o mais popular, pois pode treinar a rede muito mais rapidamente.
O próximo passo é criar várias imagens do mesmo objeto para que a rede sempre reconheça aquela imagem, qualquer que seja seu tamanho ou localização. Por exemplo, na imagem do elefante, a rede deve reconhecer o elefante, seja ele andando, parado ou correndo. Deve haver flexibilidade de imagem, e é aí que entra a camada de pooling.
Ele trabalha com as medidas da imagem (altura e largura) para reduzir progressivamente o tamanho da imagem de entrada para que os objetos na imagem possam ser vistos e identificados onde quer que ela esteja localizada.
O pooling também ajuda a controlar o 'overfitting' onde há muita informação sem espaço para novas. Talvez o exemplo mais comum de pooling seja o pooling máximo, onde a imagem é dividida em uma série de áreas não sobrepostas.
O pooling máximo trata da identificação do valor máximo em cada área para que todas as informações extras sejam excluídas e a imagem fique menor em tamanho. Essa ação também ajuda a explicar distorções na imagem.
Agora vem a camada totalmente conectada que adiciona uma rede neural artificial para usar a CNN. Essa rede artificial combina diferentes recursos e ajuda a prever as classes de imagem com maior precisão. Nesta etapa, o gradiente da função de erro é calculado em relação ao peso da rede neural. Os pesos e os detectores de recursos são ajustados para otimizar o desempenho e esse processo é repetido repetidamente.
Veja como é a arquitetura da CNN:
Fonte
Aproveitando conjuntos de dados para CNN Application-MNIST
Vários conjuntos de dados podem ser usados para aplicar a CNN de forma eficaz. Os três mais populares vitais na classificação de imagens usando CNN são MNIST, CIFAR-10 e ImageNet. Vejamos primeiro o MNIST.
1. MNIST
MNIST é um acrônimo para o conjunto de dados do Instituto Nacional de Padrões e Tecnologia Modificado e compreende 60.000 pequenas imagens quadradas 28×28 em tons de cinza de dígitos manuscritos únicos entre 0 e 9. O MNIST é um conjunto de dados popular e bem compreendido que é, para o maior parte, 'resolvido'. Ele pode ser usado em visão computacional e aprendizado profundo para praticar, desenvolver e avaliar a classificação de imagens usando CNN . Entre outras coisas, isso inclui etapas para avaliar o desempenho do modelo, explorar possíveis melhorias e usá-lo para prever novos dados.
Sua USP é que já possui um conjunto de dados de treinamento e teste bem definido que podemos usar. Esse conjunto de treinamento pode ser dividido em um conjunto de dados de treinamento e validação se for necessário avaliar o desempenho de um modelo de execução de treinamento. Seu desempenho no trem e conjunto de validação em cada corrida podem ser registrados como curvas de aprendizado para uma maior percepção de quão bem o modelo está aprendendo o problema.
Keras, uma das principais APIs de rede neural, suporta isso estipulando o argumento “validation_data ” para o modelo. Fit() ao treinar o modelo, que eventualmente retorna um objeto que menciona o desempenho do modelo para a perda e as métricas em cada execução de treinamento. Felizmente, o MNIST é equipado com Keras por padrão, e os arquivos de treinamento e teste podem ser carregados usando apenas algumas linhas de código.
Curiosamente, um artigo de Yann LeCun, Professor do Courant Institute of Mathematical Sciences da New York University e Corinna Cortes, Research Scientist do Google Labs em Nova York, aponta que o Special Database 3 (SD-3) do MNIST foi originalmente designado como um conjunto de treinamento. O Banco de Dados Especial 1 (SD-1) foi designado como um conjunto de teste.

No entanto, eles acreditam que o SD-3 é muito mais fácil de identificar e reconhecer do que o SD-1 porque o SD-3 foi coletado de funcionários que trabalham no Census Bureau, enquanto o SD-1 foi obtido entre estudantes do ensino médio. Como as conclusões precisas dos experimentos de aprendizado exigem que o resultado seja independente do conjunto de treinamento e do teste, foi considerado necessário desenvolver um novo banco de dados sem os conjuntos de dados.
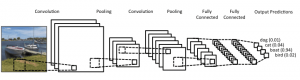
Ao usar o conjunto de dados, é recomendável dividi-lo em minilotes, armazená-lo em variáveis compartilhadas e acessá-lo com base no índice do minilote. Você pode se perguntar sobre a necessidade de variáveis compartilhadas, mas isso está relacionado ao uso da GPU. O que acontece é que ao copiar dados para a memória da GPU, se você copiar cada minilote separadamente conforme e quando necessário, o código da GPU ficará mais lento e não será muito mais rápido que o código da CPU. Se você tiver seus dados em variáveis compartilhadas Theano, há uma boa chance de copiar todos os dados para a GPU de uma só vez quando as variáveis compartilhadas forem criadas.
Posteriormente, a GPU pode usar o minilote acessando essas variáveis compartilhadas sem precisar copiar informações da memória da CPU. Além disso, como os pontos de dados geralmente são números reais e rotulam inteiros, seria bom usar variáveis diferentes para eles, bem como para o conjunto de validação, um conjunto de treinamento e um conjunto de teste, para facilitar a leitura do código.
O código abaixo mostra como armazenar dados e acessar um minilote:
Fonte
2. Conjunto de dados CIFAR-10
CIFAR significa Canadian Institute for Advanced Research, e o conjunto de dados CIFAR-10 foi desenvolvido por pesquisadores do instituto CIFAR, juntamente com o conjunto de dados CIFAR-100. O conjunto de dados CIFAR-10 consiste em 60.000 imagens coloridas de 32 × 32 pixels de objetos pertencentes a dez classes, como gatos, navios, pássaros, sapos, etc. Essas imagens são muito menores do que uma fotografia média e destinam-se a fins de visão computacional.
O CIFAR é um conjunto de dados simples e bem compreendido, com 80% de precisão na classificação de imagens usando o processo CNN e 90% no conjunto de dados de teste. Além disso, até 1.000 imagens espalhadas por um lote de teste e cinco lotes de treinamento.
O conjunto de dados CIFAR-10 consiste em 1.000 imagens selecionadas aleatoriamente de cada classe, mas alguns lotes podem conter mais imagens de uma classe do que de outra. No entanto, os lotes de treinamento contêm exatamente 5.000 imagens de cada classe. O conjunto de dados CIFAR-10 é preferido por sua facilidade de uso como ponto de partida para resolver problemas de classificação de imagens CNN .
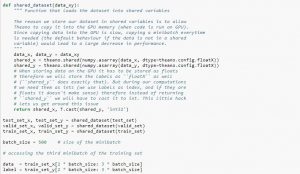
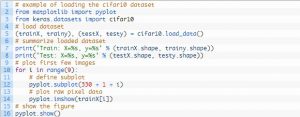
O design de seu equipamento de teste é modular e pode ser desenvolvido com cinco elementos que incluem carregamento do conjunto de dados, definição do modelo, preparação do conjunto de dados e avaliação e apresentação dos resultados. O exemplo abaixo mostra o conjunto de dados CIFAR-10 usando a API Keras com as primeiras nove imagens no conjunto de dados de treinamento:
Fonte
A execução do exemplo carrega o conjunto de dados CIFAR-10 e imprime sua forma.
3. ImageNet
ImageNet visa categorizar e rotular imagens em quase 22.000 categorias com base em palavras e frases predefinidas. Para isso, segue a hierarquia WordNet, onde cada palavra ou frase é um sinônimo ou synset (em resumo). No ImageNet, todas as imagens são organizadas de acordo com esses synsets, para ter mais de mil imagens por synset.
No entanto, quando o ImageNet é referido em visão computacional e aprendizado profundo, o que realmente significa é o ImageNet Large Scale Recognition Challenge ou ILSVRC. O objetivo aqui é categorizar uma imagem em 1.000 categorias diferentes usando mais de 100.000 imagens de teste, já que o conjunto de dados de treinamento contém cerca de 1,2 milhão de imagens.
Talvez o maior desafio aqui seja que as imagens no ImageNet medem 224×224 e, portanto, o processamento de uma quantidade tão grande de dados requer uma capacidade massiva de CPU, GPU e RAM. Isso pode ser impossível para um laptop médio, então como superar esse problema?
Uma maneira de fazer isso é usar o Imagenette, um conjunto de dados extraído do ImageNet que não requer muitos recursos. Este conjunto de dados possui duas pastas denominadas 'train' (treinamento) e 'Val' (validação) com pastas individuais para cada classe. Todas essas classes têm o mesmo ID que o conjunto de dados original, com cada uma das classes tendo cerca de 1.000 imagens, então toda a configuração é bastante equilibrada.
Outra opção é usar o aprendizado de transferência, um método que usa pesos pré-treinados em grandes conjuntos de dados. Esta é uma forma muito eficaz de classificação de imagens usando CNN porque podemos usá-la para produzir modelos que funcionam bem para nós. O único aspecto que uma classificação de imagens usando o modelo CNN deve ser capaz de fazer é classificar imagens pertencentes à mesma classe e distinguir entre aquelas que são diferentes. É aqui que podemos fazer uso dos pesos pré-treinados. A vantagem aqui é que podemos usar métodos diferentes dependendo do tipo de conjunto de dados com o qual estamos trabalhando.
Leia também: Os 7 tipos de redes neurais artificiais que os engenheiros de ML precisam conhecer
Resumindo
Para resumir, a classificação de imagens usando CNN tornou o processo mais fácil, mais preciso e menos pesado. Se você quiser se aprofundar no aprendizado de máquina, o upGrad tem uma variedade de cursos que ajudam você a dominá-lo como um profissional!
O upGrad oferece vários cursos online com uma ampla variedade de subcategorias; visite o site oficial para mais informações.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
O que são redes neurais convolucionais?
Redes neurais convolucionais (CNNs), ou convnets, são uma categoria de redes neurais artificiais profundas e feed-forward, mais comumente aplicadas à análise de imagens visuais. O design das CNNs é vagamente inspirado na organização do córtex visual dos mamíferos, embora também tenha sido aplicado ao áudio, fala e outros domínios. As CNNs usam uma variação de perceptrons multicamadas projetadas para exigir o mínimo de pré-processamento. Isso os torna menos propensos a erros e mais portáteis para um conjunto diversificado de problemas, mas sacrifica a capacidade de realizar transformações não lineares em suas entradas.
Por que as redes neurais convolucionais são boas para classificação de imagens?
A grande limitação da CNN é que ela não consegue entender o contexto de uma imagem. Também é incapaz de fazer rostos e cores. Mais limitações da CNN: As técnicas de aprendizado usadas em redes neurais não são suficientes para reproduzir funções cognitivas superiores, como reconhecimento de objetos, aprendizado, consciência espacial e capacidade de transferir experiência. A arquitetura das redes neurais não é flexível o suficiente para superar essas limitações.