
Menggunakan Jaringan Saraf Konvolusi untuk Klasifikasi Gambar
Diterbitkan: 2020-08-14Klasifikasi Gambar Mendapat Perubahan. Terima kasih kepada CNN.
Convolutional Neural Networks (CNNs) adalah tulang punggung klasifikasi gambar, sebuah fenomena pembelajaran mendalam yang mengambil gambar dan menetapkan kelas dan label yang membuatnya unik. Klasifikasi gambar menggunakan CNN merupakan bagian penting dari eksperimen pembelajaran mesin.
Bersama dengan menggunakan CNN dan kemampuannya yang diinduksi, sekarang banyak digunakan untuk berbagai aplikasi-kanan dari penandaan gambar Facebook hingga rekomendasi produk Amazon dan citra perawatan kesehatan hingga mobil otomatis. Alasan CNN begitu populer adalah karena memerlukan sedikit pra-pemrosesan, yang berarti bahwa ia dapat membaca gambar 2D dengan menerapkan filter yang tidak dapat dilakukan oleh algoritma konvensional lainnya. Kami akan mempelajari lebih dalam proses bagaimana klasifikasi gambar menggunakan CNN bekerja.
Daftar isi
Bagaimana CNN bekerja?
CNN dilengkapi dengan lapisan input, lapisan output, dan lapisan tersembunyi, yang semuanya membantu memproses dan mengklasifikasikan gambar. Lapisan tersembunyi terdiri dari lapisan convolutional, lapisan ReLU, lapisan pooling, dan lapisan yang terhubung penuh, yang semuanya memainkan peran penting. Pelajari lebih lanjut tentang jaringan saraf convolutional.
Mari kita lihat bagaimana klasifikasi gambar menggunakan CNN bekerja:
Bayangkan bahwa gambar input adalah gajah. Gambar ini, dengan piksel, pertama kali dimasukkan ke dalam lapisan konvolusi. Jika itu adalah gambar hitam putih, gambar ditafsirkan sebagai lapisan 2D, dengan setiap piksel diberi nilai antara '0' dan '255', '0' sepenuhnya hitam, dan '255' sepenuhnya putih. Sebaliknya, jika itu adalah gambar berwarna, ini menjadi larik 3D, dengan lapisan biru, hijau, dan merah, dengan masing-masing nilai warna antara 0 dan 255.

Pembacaan matriks kemudian dimulai, di mana perangkat lunak memilih gambar yang lebih kecil, yang dikenal sebagai 'filter' (atau kernel). Kedalaman filter sama dengan kedalaman input. Filter kemudian menghasilkan gerakan konvolusi bersama dengan gambar input, bergerak ke kanan sepanjang gambar sebesar 1 unit.
Kemudian mengalikan nilai dengan nilai gambar asli. Semua angka yang dikalikan dijumlahkan, dan satu angka dihasilkan. Proses ini diulangi bersama dengan seluruh gambar, dan diperoleh matriks, lebih kecil dari gambar input asli.
Array terakhir disebut peta fitur dari peta aktivasi. Konvolusi gambar membantu melakukan operasi seperti deteksi tepi, penajaman, dan pengaburan, dengan menerapkan filter yang berbeda. Yang perlu dilakukan hanyalah menentukan aspek-aspek seperti ukuran filter, jumlah filter dan/atau arsitektur jaringan.
Dari sudut pandang manusia, tindakan ini mirip dengan mengidentifikasi warna dan batas sederhana dari sebuah gambar. Namun, untuk mengklasifikasikan gambar dan mengenali fitur yang membuatnya, katakanlah, gajah dan bukan kucing, fitur unik seperti telinga besar dan belalai gajah perlu diidentifikasi. Di sinilah lapisan non-linear dan pooling masuk.
Lapisan non-linier (ReLU) mengikuti lapisan konvolusi, di mana fungsi aktivasi diterapkan pada peta fitur untuk meningkatkan ketidaklinieran gambar. Lapisan ReLU menghilangkan semua nilai negatif dan meningkatkan akurasi gambar. Meskipun ada operasi lain seperti tanh atau sigmoid, ReLU adalah yang paling populer karena dapat melatih jaringan lebih cepat.
Langkah selanjutnya adalah membuat beberapa gambar dari objek yang sama sehingga jaringan selalu dapat mengenali gambar tersebut, berapa pun ukuran atau lokasinya. Misalnya, pada gambar gajah, jaringan harus mengenali gajah, apakah sedang berjalan, berdiri diam, atau berlari. Harus ada fleksibilitas gambar, dan di situlah lapisan penyatuan masuk.
Ia bekerja dengan pengukuran gambar (tinggi dan lebar) untuk secara progresif mengurangi ukuran gambar input sehingga objek dalam gambar dapat terlihat dan diidentifikasi di mana pun ia berada.
Pooling juga membantu mengontrol 'overfitting' di mana ada terlalu banyak informasi tanpa ruang lingkup untuk yang baru. Mungkin, contoh pooling yang paling umum adalah max pooling, di mana gambar dibagi menjadi serangkaian area yang tidak tumpang tindih.
Penggabungan maksimum adalah tentang mengidentifikasi nilai maksimum di setiap area sehingga semua informasi tambahan dikecualikan, dan ukuran gambar menjadi lebih kecil. Tindakan ini membantu menjelaskan distorsi pada gambar juga.
Sekarang hadir lapisan yang sepenuhnya terhubung yang menambahkan jaringan saraf tiruan untuk menggunakan CNN. Jaringan buatan ini menggabungkan fitur yang berbeda dan membantu memprediksi kelas gambar dengan akurasi yang lebih besar. Pada tahap ini, gradien fungsi kesalahan dihitung berdasarkan bobot jaringan saraf. Bobot dan detektor fitur disesuaikan untuk mengoptimalkan kinerja, dan proses ini diulang berulang kali.
Inilah yang tampak seperti arsitektur CNN:
Sumber
Memanfaatkan kumpulan data untuk Aplikasi CNN-MNIST
Beberapa kumpulan data dapat digunakan untuk menerapkan CNN secara efektif. Tiga yang paling populer dalam klasifikasi citra menggunakan CNN adalah MNIST, CIFAR-10, dan ImageNet. Mari kita lihat MNIST dulu.
1. MNIST
MNIST adalah akronim untuk kumpulan data Institut Standar dan Teknologi yang Dimodifikasi dan terdiri dari 60.000 gambar skala abu-abu berukuran 28x28 persegi berukuran kecil dengan angka tulisan tangan antara 0 dan 9. MNIST adalah kumpulan data yang populer dan dipahami dengan baik, untuk bagian, 'terpecahkan.' Dapat digunakan dalam computer vision dan deep learning untuk mempraktekkan, mengembangkan, dan mengevaluasi klasifikasi citra menggunakan CNN . Antara lain, ini mencakup langkah-langkah untuk mengevaluasi kinerja model, mengeksplorasi kemungkinan perbaikan, dan menggunakannya untuk memprediksi data baru.
USP-nya adalah bahwa ia sudah memiliki dataset kereta dan pengujian yang terdefinisi dengan baik yang dapat kita gunakan. Kumpulan pelatihan ini selanjutnya dapat dibagi menjadi rangkaian pelatihan dan memvalidasi dataset jika seseorang perlu mengevaluasi kinerja model yang dijalankan pelatihan. Performanya di kereta dan set validasi pada setiap putaran dapat direkam sebagai kurva pembelajaran untuk wawasan yang lebih luas tentang seberapa baik model mempelajari masalahnya.
Keras, salah satu API jaringan saraf terkemuka, mendukung ini dengan menetapkan argumen “validation_data ” ke model. Fit() berfungsi saat melatih model, yang pada akhirnya mengembalikan objek yang menyebutkan performa model untuk kerugian dan metrik pada setiap pelatihan yang dijalankan. Untungnya, MNIST dilengkapi dengan Keras secara default, dan file kereta dan pengujian dapat dimuat hanya dengan beberapa baris kode.
Menariknya, sebuah artikel oleh Yann LeCun, Profesor di The Courant Institute of Mathematical Sciences di New York University dan Corinna Cortes, Research Scientist di Google Labs di New York, menunjukkan bahwa MNIST's Special Database 3 (SD-3) awalnya ditugaskan sebagai perlengkapan latihan. Database Khusus 1 (SD-1) ditetapkan sebagai set pengujian.

Namun, mereka percaya bahwa SD-3 jauh lebih mudah dikenali dan dikenali daripada SD-1 karena SD-3 dikumpulkan dari pegawai yang bekerja di Biro Sensus, sedangkan SD-1 bersumber dari kalangan siswa SMA. Karena kesimpulan yang akurat dari eksperimen pembelajaran mengamanatkan bahwa hasilnya harus independen dari set pelatihan dan pengujian, dianggap perlu untuk mengembangkan database baru dengan melewatkan set data.
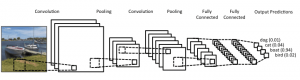
Saat menggunakan dataset, disarankan untuk membaginya menjadi minibatch, menyimpannya dalam variabel bersama, dan mengaksesnya berdasarkan indeks minibatch. Anda mungkin bertanya-tanya perlunya variabel bersama, tetapi ini terkait dengan penggunaan GPU. Apa yang terjadi adalah ketika menyalin data ke memori GPU, jika Anda menyalin setiap minibatch secara terpisah jika diperlukan, kode GPU akan melambat dan tidak lebih cepat dari kode CPU. Jika Anda memiliki data dalam variabel bersama Theano, ada peluang bagus untuk menyalin seluruh data ke GPU sekaligus saat variabel bersama dibuat.
Nantinya GPU dapat menggunakan minibatch dengan mengakses variabel bersama ini tanpa perlu menyalin informasi dari memori CPU. Juga, karena titik data biasanya bilangan real dan bilangan bulat label, akan lebih baik untuk menggunakan variabel yang berbeda untuk ini serta untuk set validasi, set pelatihan, dan set pengujian, untuk membuat kode lebih mudah dibaca.
Kode di bawah ini menunjukkan cara menyimpan data dan mengakses minibatch:
Sumber
2. Kumpulan Data CIFAR-10
CIFAR adalah singkatan dari Canadian Institute for Advanced Research, dan kumpulan data CIFAR-10 dikembangkan oleh para peneliti di lembaga CIFAR, bersama dengan kumpulan data CIFAR-100. Dataset CIFAR-10 terdiri dari 60.000 gambar berwarna 32×32 piksel dari objek yang termasuk dalam sepuluh kelas seperti kucing, kapal, burung, katak, dll. Gambar-gambar ini jauh lebih kecil daripada foto rata-rata dan dimaksudkan untuk tujuan penglihatan komputer.
CIFAR adalah kumpulan data langsung yang dipahami dengan baik, yang 80% akurat dalam klasifikasi gambar menggunakan proses CNN dan 90% pada kumpulan data uji. Juga, sebanyak 1.000 gambar tersebar di satu batch tes dan lima batch pelatihan.
Dataset CIFAR-10 terdiri dari 1.000 gambar yang dipilih secara acak dari setiap kelas, tetapi beberapa kumpulan mungkin berisi lebih banyak gambar dari satu kelas daripada yang lain. Namun, kumpulan pelatihan berisi tepat 5.000 gambar dari setiap kelas. Dataset CIFAR-10 lebih disukai karena kemudahan penggunaannya sebagai titik awal untuk memecahkan masalah klasifikasi citra CNN .
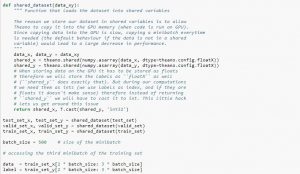
Desain test harness-nya bersifat modular, dan dapat dikembangkan dengan lima elemen yang mencakup pemuatan set data, definisi model, persiapan set data, serta evaluasi dan presentasi hasil. Contoh di bawah ini menunjukkan kumpulan data CIFAR-10 menggunakan Keras API dengan sembilan gambar pertama dalam kumpulan data pelatihan:
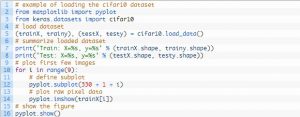
Sumber
Menjalankan contoh memuat set data CIFAR-10 dan mencetak bentuknya.
3. ImageNet
ImageNet bertujuan untuk mengkategorikan dan melabeli gambar ke dalam hampir 22.000 kategori berdasarkan kata dan frasa yang telah ditentukan sebelumnya. Untuk melakukan ini, ini mengikuti hierarki WordNet, di mana setiap kata atau frasa adalah sinonim atau synset (singkatnya). Di ImageNet, semua gambar diatur menurut synset ini, untuk memiliki lebih dari seribu gambar per synset.
Namun, ketika ImageNet dirujuk dalam computer vision dan deep learning, yang sebenarnya dimaksud adalah ImageNet Large Scale Recognition Challenge atau ILSVRC. Tujuannya di sini adalah untuk mengkategorikan gambar ke dalam 1.000 kategori berbeda dengan menggunakan lebih dari 100.000 gambar uji karena set data pelatihan berisi sekitar 1,2 juta gambar.
Mungkin tantangan terbesar di sini adalah bahwa gambar di ImageNet berukuran 224x224, sehingga pemrosesan data dalam jumlah besar membutuhkan kapasitas CPU, GPU, dan RAM yang besar. Ini mungkin terbukti mustahil untuk laptop rata-rata, jadi bagaimana cara mengatasi masalah ini?
Salah satu cara untuk melakukannya adalah dengan menggunakan Imagenette, kumpulan data yang diekstrak dari ImageNet yang tidak memerlukan terlalu banyak sumber daya. Dataset ini memiliki dua folder bernama 'train' (pelatihan) dan 'Val' (validasi) dengan folder individual untuk setiap kelas. Semua kelas ini memiliki ID yang sama dengan dataset asli, dengan masing-masing kelas memiliki sekitar 1.000 gambar, sehingga seluruh pengaturan cukup seimbang.
Pilihan lainnya adalah menggunakan transfer learning, sebuah metode yang menggunakan bobot yang telah dilatih sebelumnya pada kumpulan data yang besar. Ini adalah cara klasifikasi gambar yang sangat efektif menggunakan CNN karena kita dapat menggunakannya untuk menghasilkan model yang bekerja dengan baik untuk kita. Salah satu aspek yang harus dapat dilakukan oleh klasifikasi citra dengan model CNN adalah mengklasifikasikan citra yang termasuk dalam kelas yang sama dan membedakan citra yang berbeda. Di sinilah kita dapat menggunakan beban yang telah dilatih sebelumnya. Keuntungannya di sini adalah kita dapat menggunakan metode yang berbeda tergantung pada jenis dataset yang sedang kita kerjakan.
Baca Juga: 7 Jenis Jaringan Syaraf Tiruan yang Perlu Diketahui Engineer ML
Menyimpulkan
Singkatnya, klasifikasi gambar menggunakan CNN telah membuat proses lebih mudah, lebih akurat, dan tidak terlalu banyak proses. Jika Anda ingin mempelajari pembelajaran mesin lebih dalam, upGrad memiliki berbagai kursus yang membantu Anda menguasainya seperti seorang profesional!
upGrad menawarkan berbagai kursus online dengan berbagai subkategori; kunjungi situs resminya untuk informasi lebih lanjut.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa itu jaringan saraf convolutional?
Jaringan saraf convolutional (CNNs), atau convnets, adalah kategori jaringan saraf tiruan feed-forward yang dalam, paling sering diterapkan untuk menganalisis citra visual. Desain CNN secara longgar terinspirasi oleh organisasi korteks visual mamalia, meskipun mereka juga telah diterapkan pada audio, ucapan, dan domain lainnya. CNN menggunakan variasi perceptron multilayer yang dirancang untuk membutuhkan pra-pemrosesan minimal. Hal ini membuat mereka kurang rawan kesalahan dan lebih portabel untuk beragam masalah, tetapi mengorbankan kemampuan untuk melakukan transformasi non-linear pada input mereka.
Mengapa jaringan saraf convolutional bagus untuk klasifikasi gambar?
Keterbatasan besar CNN adalah ia tidak dapat memahami konteks dalam sebuah gambar. Hal ini juga tidak dapat melakukan wajah dan melakukan warna. Lebih banyak keterbatasan CNN: Teknik pembelajaran yang digunakan dalam jaringan saraf tidak cukup untuk mereproduksi fungsi kognitif yang lebih tinggi seperti pengenalan objek, pembelajaran, kesadaran spasial dan kemampuan untuk mentransfer pengalaman. Arsitektur jaringan saraf tidak cukup fleksibel untuk mengatasi keterbatasan ini.