
استخدام الشبكة العصبية التلافيفية لتصنيف الصور
نشرت: 2020-08-14تصنيف الصور يحصل على تحول. بفضل CNN.
الشبكات العصبية التلافيفية (CNNs) هي العمود الفقري لتصنيف الصور ، وهي ظاهرة تعليمية عميقة تأخذ صورة وتخصص لها فئة وتسمية تجعلها فريدة من نوعها. يشكل تصنيف الصور باستخدام CNN جزءًا مهمًا من تجارب التعلم الآلي.
إلى جانب استخدام CNN وقدراتها المستحثة ، يتم استخدامه الآن على نطاق واسع لمجموعة من التطبيقات - بدءًا من وضع علامات على صور Facebook إلى توصيات منتجات Amazon وصور الرعاية الصحية إلى السيارات الأوتوماتيكية. السبب وراء شهرة شبكة CNN هو أنها تتطلب القليل جدًا من المعالجة المسبقة ، مما يعني أنه يمكنها قراءة الصور ثنائية الأبعاد عن طريق تطبيق عوامل تصفية لا تستطيع الخوارزميات التقليدية الأخرى قراءتها. سوف نتعمق في عملية تصنيف الصور باستخدام CNN .
جدول المحتويات
كيف تعمل سي إن إن؟
تم تجهيز CNN بطبقة إدخال وطبقة إخراج وطبقات مخفية ، وكلها تساعد في معالجة الصور وتصنيفها. تتكون الطبقات المخفية من طبقات تلافيفية وطبقات ReLU وطبقات تجميع وطبقات متصلة بالكامل ، وكلها تلعب دورًا مهمًا. تعرف على المزيد حول الشبكة العصبية التلافيفية.
لنلقِ نظرة على كيفية عمل تصنيف الصور باستخدام CNN :
تخيل أن الصورة المدخلة هي صورة فيل. يتم إدخال هذه الصورة ، بالبكسل ، أولاً في الطبقات التلافيفية. إذا كانت صورة بالأبيض والأسود ، فسيتم تفسير الصورة على أنها طبقة ثنائية الأبعاد ، مع تعيين قيمة لكل بكسل بين "0" و "255" ، و "0" سوداء بالكامل ، و "255" بيضاء تمامًا. من ناحية أخرى ، إذا كانت صورة ملونة ، فسيصبح هذا مصفوفة ثلاثية الأبعاد ، بطبقة زرقاء وخضراء وحمراء ، مع كل قيمة لون بين 0 و 255.

تبدأ قراءة المصفوفة بعد ذلك ، حيث يختار البرنامج صورة أصغر ، تُعرف باسم "المرشح" (أو النواة). عمق المرشح هو نفس عمق الإدخال. ينتج المرشح بعد ذلك حركة التفاف مع صورة الإدخال ، متحركًا على طول الصورة بمقدار وحدة واحدة.
ثم يقوم بضرب القيم بقيم الصورة الأصلية. يتم جمع كل الأرقام المضاعفة معًا ، ويتم إنشاء رقم واحد. تتكرر العملية مع الصورة بأكملها ، ويتم الحصول على مصفوفة أصغر من صورة الإدخال الأصلية.
تسمى المصفوفة النهائية خريطة المعالم لخريطة التنشيط. يساعد التفاف الصورة في إجراء عمليات مثل اكتشاف الحواف ، والتوضيح ، والتعتيم ، من خلال تطبيق مرشحات مختلفة. كل ما يحتاجه المرء هو تحديد جوانب مثل حجم المرشح و / أو عدد المرشحات و / أو بنية الشبكة.
من منظور بشري ، يشبه هذا الإجراء تحديد الألوان والحدود البسيطة للصورة. ومع ذلك ، لتصنيف الصورة والتعرف على الميزات التي تجعلها ، على سبيل المثال ، صورة فيل وليس قطة ، يجب تحديد الميزات الفريدة مثل الأذنين الكبيرة وجذع الفيل. هذا هو المكان الذي تأتي فيه الطبقات غير الخطية والتجميع.
تتبع الطبقة غير الخطية (ReLU) طبقة الالتفاف ، حيث يتم تطبيق وظيفة التنشيط على خرائط المعالم لزيادة عدم خطية الصورة. تزيل طبقة ReLU كل القيم السلبية وتزيد من دقة الصورة. على الرغم من وجود عمليات أخرى مثل tanh أو sigmoid ، إلا أن ReLU هي الأكثر شيوعًا حيث يمكنها تدريب الشبكة بشكل أسرع.
تتمثل الخطوة التالية في إنشاء عدة صور لنفس الكائن حتى تتمكن الشبكة دائمًا من التعرف على تلك الصورة ، بغض النظر عن حجمها أو موقعها. على سبيل المثال ، في صورة الفيل ، يجب أن تتعرف الشبكة على الفيل ، سواء كان يمشي أو يقف ثابتًا أو يجري. يجب أن تكون هناك مرونة في الصورة ، وهنا يأتي دور طبقة التجميع.
إنه يعمل مع قياسات الصورة (الارتفاع والعرض) لتقليل حجم الصورة المدخلة تدريجيًا بحيث يمكن رصد الكائنات الموجودة في الصورة وتحديدها أينما كانت.
يساعد التجميع أيضًا في التحكم في "التجهيز الزائد" حيث يوجد الكثير من المعلومات مع عدم وجود مجال لأخرى جديدة. ربما يكون المثال الأكثر شيوعًا للتجميع هو الحد الأقصى للتجميع ، حيث يتم تقسيم الصورة إلى سلسلة من المناطق غير المتداخلة.
يتعلق Max pooling بتحديد القيمة القصوى في كل منطقة بحيث يتم استبعاد جميع المعلومات الإضافية ، وتصبح الصورة أصغر حجمًا. يساعد هذا الإجراء في حساب التشوهات في الصورة أيضًا.
الآن تأتي الطبقة المتصلة بالكامل التي تضيف شبكة عصبية اصطناعية لاستخدام CNN. تجمع هذه الشبكة الاصطناعية بين ميزات مختلفة وتساعد في التنبؤ بفئات الصور بدقة أكبر. في هذه المرحلة ، يتم حساب تدرج دالة الخطأ فيما يتعلق بوزن الشبكة العصبية. يتم ضبط الأوزان وأجهزة الكشف عن الميزات لتحسين الأداء ، وتتكرر هذه العملية بشكل متكرر.
إليك ما تبدو عليه بنية CNN:
مصدر
الاستفادة من مجموعات البيانات لتطبيق CNN-MNIST
يمكن استخدام العديد من مجموعات البيانات لتطبيق CNN بشكل فعال. الثلاثة الأكثر شعبية في تصنيف الصور باستخدام CNN هي MNIST و CIFAR-10 و ImageNet. لنلقِ نظرة على MNIST أولاً.
1. MNIST
MNIST هو اختصار لمجموعة بيانات المعهد الوطني المعدل للمعايير والتكنولوجيا ويتألف من 60.000 صورة صغيرة مربعة 28 × 28 ذات تدرج رمادي لأرقام فردية مكتوبة بخط اليد بين 0 و 9. MNIST هي مجموعة بيانات شائعة ومفهومة جيدًا ، الجزء ، "حل". يمكن استخدامه في رؤية الكمبيوتر والتعلم العميق لممارسة تصنيف الصور وتطويره وتقييمه باستخدام CNN . يتضمن ذلك ، من بين أشياء أخرى ، خطوات لتقييم أداء النموذج ، واستكشاف التحسينات الممكنة ، واستخدامها للتنبؤ بالبيانات الجديدة.
إن USP الخاص به هو أنه يحتوي بالفعل على مجموعة بيانات تدريب واختبار محددة جيدًا يمكننا استخدامها. يمكن أيضًا تقسيم مجموعة التدريب هذه إلى قطار والتحقق من صحة مجموعة البيانات إذا احتاج المرء إلى تقييم أداء نموذج تشغيل التدريب. يمكن تسجيل أدائها في القطار والتحقق من صحة المجموعة في كل شوط كمنحنيات تعليمية للحصول على نظرة ثاقبة أكبر حول كيفية تعلم النموذج للمشكلة.
تدعم Keras ، إحدى واجهات برمجة التطبيقات للشبكات العصبية الرائدة ، ذلك من خلال اشتراط وسيطة " Validation_data" على النموذج. وظيفة Fit () عند تدريب النموذج ، والتي تقوم في النهاية بإرجاع كائن يذكر أداء النموذج للخسارة والمقاييس في كل دورة تدريبية. لحسن الحظ ، تم تجهيز MNIST بـ Keras افتراضيًا ، ويمكن تحميل ملفات القطار والاختبار باستخدام بضعة أسطر فقط من التعليمات البرمجية.
ومن المثير للاهتمام ، أن مقالًا بقلم يان لوكون ، الأستاذ في معهد كورانت للعلوم الرياضية بجامعة نيويورك وكورينا كورتيس ، عالمة الأبحاث في مختبرات Google في نيويورك ، يشير إلى أن قاعدة البيانات الخاصة 3 (SD-3) الخاصة بـ MNIST تم تعيينها في الأصل باعتبارها عدة التدريبات. تم تعيين قاعدة البيانات الخاصة 1 (SD-1) كمجموعة اختبار.

ومع ذلك ، فهم يعتقدون أن التعرف على SD-3 والتعرف عليه أسهل بكثير من SD-1 لأنه تم جمع SD-3 من الموظفين العاملين في مكتب الإحصاء ، بينما تم الحصول على SD-1 من بين طلاب المدارس الثانوية. نظرًا لأن الاستنتاجات الدقيقة من تجارب التعلم تنص على أن النتيجة يجب أن تكون مستقلة عن مجموعة التدريب والاختبار ، فقد كان من الضروري تطوير قاعدة بيانات جديدة من خلال فقدان مجموعات البيانات.
عند استخدام مجموعة البيانات ، يوصى بتقسيمها إلى مجموعات صغيرة ، وتخزينها في متغيرات مشتركة ، والوصول إليها بناءً على فهرس minibatch. قد تتساءل عن الحاجة إلى المتغيرات المشتركة ، ولكن هذا مرتبط باستخدام وحدة معالجة الرسومات. ما يحدث هو أنه عند نسخ البيانات إلى ذاكرة وحدة معالجة الرسومات ، إذا قمت بنسخ كل دقيقة صغيرة بشكل منفصل عند الحاجة ، فإن رمز وحدة معالجة الرسومات سوف يتباطأ ولن يكون أسرع بكثير من رمز وحدة المعالجة المركزية. إذا كانت لديك بياناتك في متغيرات Theano المشتركة ، فهناك فرصة جيدة لنسخ البيانات بأكملها على وحدة معالجة الرسومات دفعة واحدة عند إنشاء المتغيرات المشتركة.
في وقت لاحق ، يمكن لوحدة معالجة الرسومات استخدام الدفعة المصغرة من خلال الوصول إلى هذه المتغيرات المشتركة دون الحاجة إلى نسخ المعلومات من ذاكرة وحدة المعالجة المركزية. أيضًا ، نظرًا لأن نقاط البيانات عادة ما تكون أرقامًا حقيقية وأرقامًا صحيحة للتسمية ، سيكون من الجيد استخدام متغيرات مختلفة لهذه بالإضافة إلى مجموعة التحقق ومجموعة التدريب ومجموعة الاختبار ، لتسهيل قراءة الكود.
يوضح لك الرمز أدناه كيفية تخزين البيانات والوصول إلى minibatch:
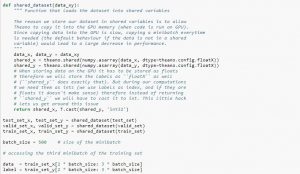
مصدر
2. مجموعة بيانات CIFAR-10
يرمز CIFAR إلى المعهد الكندي للأبحاث المتقدمة ، وقد تم تطوير مجموعة بيانات CIFAR-10 بواسطة باحثين في معهد CIFAR ، جنبًا إلى جنب مع مجموعة بيانات CIFAR-100. تتكون مجموعة بيانات CIFAR-10 من 60.000 صورة ملونة 32 × 32 بكسل لأشياء تنتمي إلى عشر فئات مثل القطط والسفن والطيور والضفادع وما إلى ذلك. هذه الصور أصغر بكثير من الصور العادية وهي مخصصة لأغراض رؤية الكمبيوتر.
CIFAR هي مجموعة بيانات واضحة ومفهومة جيدًا بدقة 80٪ في تصنيف الصور باستخدام عملية CNN و 90٪ في مجموعة بيانات الاختبار. أيضًا ، ما يصل إلى 1000 صورة موزعة على مجموعة اختبار واحدة وخمس مجموعات تدريب.
تتكون مجموعة بيانات CIFAR-10 من 1000 صورة تم اختيارها عشوائيًا من كل فئة ، ولكن قد تحتوي بعض الدفعات على صور من فئة واحدة أكثر من الأخرى. ومع ذلك ، تحتوي مجموعات التدريب بالضبط على 5000 صورة من كل فصل. تُفضل مجموعة بيانات CIFAR-10 لسهولة استخدامها كنقطة بداية لحل تصنيف الصور CNN باستخدام المشكلات.
يعد تصميم أداة الاختبار الخاصة به معياريًا ، ويمكن تطويره باستخدام خمسة عناصر تشمل تحميل مجموعة البيانات ، وتعريف النموذج ، وإعداد مجموعة البيانات ، والتقييم وعرض النتائج. يوضح المثال أدناه مجموعة بيانات CIFAR-10 باستخدام Keras API مع الصور التسعة الأولى في مجموعة بيانات التدريب:
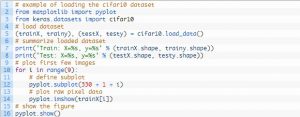
مصدر
يؤدي تشغيل المثال إلى تحميل مجموعة بيانات CIFAR-10 وطباعة شكلها.
3. ImageNet
تهدف ImageNet إلى تصنيف الصور وتسميتها إلى ما يقرب من 22000 فئة بناءً على الكلمات والعبارات المحددة مسبقًا. للقيام بذلك ، يتبع التسلسل الهرمي لـ WordNet ، حيث تكون كل كلمة أو عبارة مرادفًا أو مرادفًا (باختصار). في ImageNet ، يتم تنظيم جميع الصور وفقًا لهذه المجموعات ، بحيث تحتوي على أكثر من ألف صورة لكل مزامنة.
ومع ذلك ، عند الإشارة إلى ImageNet في رؤية الكمبيوتر والتعلم العميق ، فإن المقصود في الواقع هو تحدي التعرف على نطاق ImageNet واسع النطاق أو ILSVRC. الهدف هنا هو تصنيف الصورة إلى 1000 فئة مختلفة باستخدام أكثر من 100000 صورة اختبارية لأن مجموعة بيانات التدريب تحتوي على حوالي 1.2 مليون صورة.
ربما يكون التحدي الأكبر هنا هو أن الصور في ImageNet تبلغ 224 × 224 ، وبالتالي تتطلب معالجة مثل هذا الكم الهائل من البيانات سعة هائلة من وحدة المعالجة المركزية ووحدة معالجة الرسومات وذاكرة الوصول العشوائي. قد يكون هذا مستحيلًا بالنسبة لجهاز كمبيوتر محمول عادي ، فكيف يتغلب المرء على هذه المشكلة؟
تتمثل إحدى طرق القيام بذلك في استخدام Imagenette ، وهي مجموعة بيانات مستخرجة من ImageNet لا تتطلب الكثير من الموارد. تحتوي مجموعة البيانات هذه على مجلدين باسم "القطار" (تدريب) و "Val" (التحقق) مع مجلدات فردية لكل فصل. كل هذه الفئات لها نفس المعرف الخاص بمجموعة البيانات الأصلية ، حيث تحتوي كل فئة على حوالي 1000 صورة ، لذا فإن الإعداد الكامل متوازن جدًا.
خيار آخر هو استخدام التعلم بالنقل ، وهي طريقة تستخدم أوزانًا مُدربة مسبقًا على مجموعات البيانات الكبيرة. هذه طريقة فعالة جدًا لتصنيف الصور باستخدام CNN لأنه يمكننا استخدامها لإنتاج نماذج تعمل جيدًا بالنسبة لنا. الجانب الوحيد الذي يجب أن يكون بمقدور تصنيف الصور باستخدام نموذج CNN القيام به هو تصنيف الصور التي تنتمي إلى نفس الفئة والتمييز بين تلك الصور المختلفة. هذا هو المكان الذي يمكننا فيه الاستفادة من الأوزان المدربة مسبقًا. الميزة هنا هي أنه يمكننا استخدام طرق مختلفة اعتمادًا على نوع مجموعة البيانات التي نعمل معها.
اقرأ أيضًا: الأنواع السبعة للشبكات العصبية الاصطناعية التي يحتاج مهندسو ML إلى معرفتها
تلخيص لما سبق
باختصار ، فإن تصنيف الصور باستخدام CNN قد جعل العملية أسهل وأكثر دقة وأقل ثقلاً في العملية. إذا كنت ترغب في التعمق في التعلم الآلي ، فإن upGrad لديها مجموعة من الدورات التدريبية التي تساعدك على إتقانها كالمحترفين!
تقدم upGrad دورات متنوعة عبر الإنترنت مع مجموعة واسعة من الفئات الفرعية ؛ قم بزيارة الموقع الرسمي لمزيد من المعلومات.
إذا كنت مهتمًا بمعرفة المزيد حول التعلم الآلي ، فراجع دبلوم PG في IIIT-B & upGrad في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT- حالة الخريجين B ، أكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع أفضل الشركات.
ما هي الشبكات العصبية التلافيفية؟
الشبكات العصبية التلافيفية (CNNs) ، أو Convnets ، هي فئة من الشبكات العصبية الاصطناعية العميقة والتغذية الأمامية ، والتي يتم تطبيقها بشكل شائع على تحليل الصور المرئية. تصميم شبكات CNN مستوحى بشكل فضفاض من تنظيم القشرة البصرية للثدييات ، على الرغم من أنه تم تطبيقها أيضًا على مجالات الصوت والكلام وغيرها. تستخدم شبكات CNN مجموعة متنوعة من الإدراكات متعددة الطبقات المصممة لتتطلب الحد الأدنى من المعالجة المسبقة. هذا يجعلهم أقل عرضة للخطأ وأكثر قابلية للنقل لمجموعة متنوعة من المشاكل ، لكنه يضحي بالقدرة على إجراء تحويلات غير خطية على مدخلاتهم.
لماذا الشبكات العصبية التلافيفية جيدة لتصنيف الصور؟
القيد الكبير لـ CNN هو أنها غير قادرة على فهم السياق في الصورة. كما أنه غير قادر على عمل الوجوه واللون. المزيد من قيود CNN: تقنيات التعلم المستخدمة في الشبكات العصبية ليست كافية لإعادة إنتاج الوظائف المعرفية العليا مثل التعرف على الأشياء والتعلم والوعي المكاني والقدرة على نقل الخبرة. إن بنية الشبكات العصبية ليست مرنة بما يكفي للتغلب على هذه القيود.