
支持向量機:SVM 的類型 [算法解釋]
已發表: 2020-12-01目錄
介紹
就像機器學習中執行分類任務(決策樹、隨機森林、K-NN)和回歸的其他算法一樣,支持向量機或 SVM 是整個池中的一種此類算法。 它是一種有監督的(需要標記數據集)機器學習算法,用於解決與分類或回歸相關的問題。
但是,它經常應用於分類問題。 SVM 算法需要將每個數據項繪製為一個點。 繪圖是在 n 維空間中完成的,其中 n 是特定數據的特徵數。 然後,通過找到有效分離兩個(或更多)類的最合適的超平面來進行分類。
術語支持向量只是單個特徵的坐標。 為什麼將數據點概括為您可能會問的向量。 在現實世界的問題中,存在更高維度的數據集。 在更高維度(n 維度)中,執行向量算術和矩陣操作而不是將它們視為點更有意義。
支持向量機的類型
線性支持向量機:線性支持向量機用於線性可分的數據,即用於可以通過使用一條直線分為兩類的數據集。 這樣的數據點被稱為線性可分數據,分類器被描述為線性 SVM 分類器。
非線性 SVM:非線性 SVM 用於非線性可分離數據的數據,即不能使用直線對數據集進行分類。 為此,我們使用了一種稱為內核技巧的東西,將數據點設置在更高維度,可以使用平面或其他數學函數將它們分開。 這樣的數據點稱為非線性數據,使用的分類器稱為非線性 SVM 分類器。
線性 SVM 算法
讓我們談談一個二元分類問題。 任務是盡可能準確地對任一類中的測試點進行有效分類。 以下是 SVM 過程中涉及的步驟。

首先,繪製和可視化屬於這兩個類的一組點,如下所示。 在二維空間中,只需應用一條直線,我們就可以有效地劃分這兩個類。 但是可以有很多行可以對這些類進行分類。 有一組線或超平面(綠線)可供選擇。 顯而易見的問題是,在所有這些行中,哪一行適合分類?
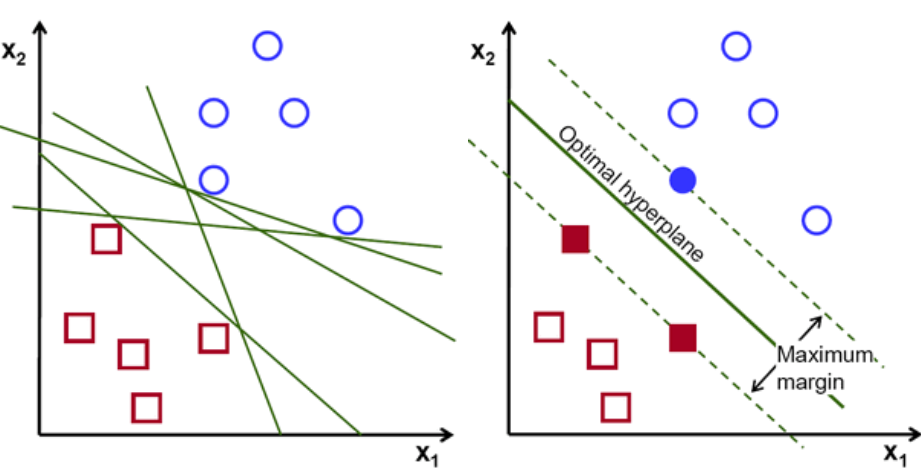
一組超平面,圖片來源
基本上,選擇能更好地分離這兩個類的超平面。 我們通過最大化最近數據點和超平面之間的距離來做到這一點。 距離越大,超平面越好,從而得到更好的分類結果。 從下圖中可以看出,選擇的超平面與每個類的最近點的距離最大。
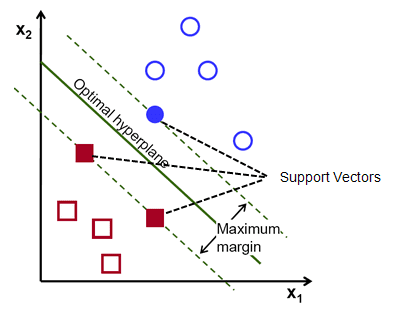
提醒一下,平行於超平面穿過每個類的最近點的兩條虛線稱為超平面的支持向量。 現在,支持向量和超平面之間的分離距離稱為邊距。 而 SVM 算法的目的就是最大化這個餘量。 最優超平面是具有最大餘量的超平面。
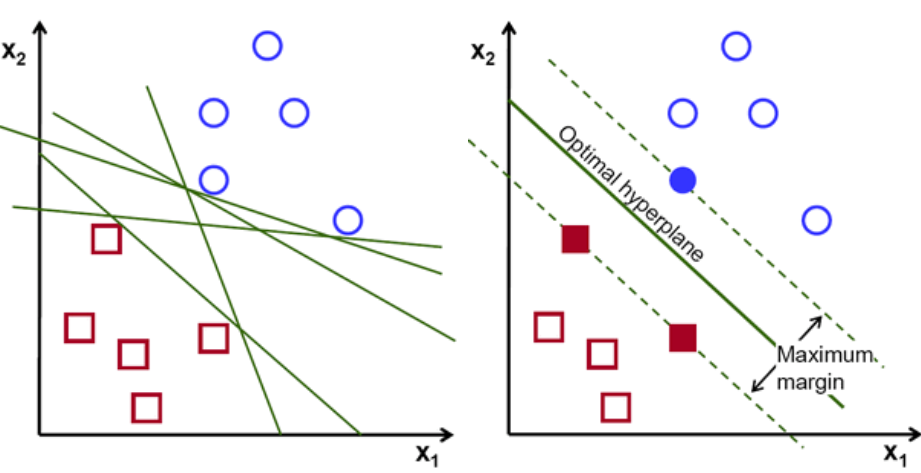
形象學分
以將細胞分類為好和壞為例。 單元格xᵢ被定義為可以在 n 維空間上繪製的這些特徵向量中的每一個都標有yᵢ 類。 yᵢ類可以是 +ve 或 -ve(例如,好=1,不好=-1)。 超平面的方程是 y= wx + b = 0。其中 W 和 b 是線參數。 對於 +ve 類的示例,前面的等式返回 ≥ 1 的值,對於 -ve 類的示例返回 ≤-1 的值。
但是,它是如何找到這個超平面的呢? 超平面是通過找到最佳值 w 或權重和 b 或截距來定義的。 這些最優值是通過最小化成本函數來找到的。 一旦算法收集到這些最優值,SVM 模型或線函數 f(x) 就會有效地對這兩個類別進行分類。
簡而言之,最優超平面具有方程 w.x+b = 0。左支持向量具有方程 w.x+b=-1,右支持向量具有 w.x+b=1。
因此,兩個平行留置權 Ay = Bx + c1 和 Ay = Bx + c2 之間的距離 d 由 d = |C1–C2|/√A^2 + B^2 給出。 有了這個公式,我們就有兩個支持向量之間的距離為 2/||w||。
SVM 的成本函數類似於以下等式:
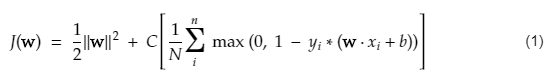

形象學分
SVM 損失函數
在上面的成本函數方程中,λ 參數表示較大的 λ 提供更寬的餘量,較小的 λ 將產生較小的餘量。 此外,計算成本函數的梯度,並在降低損失函數的方向上更新權重。
閱讀:機器學習的線性代數:關鍵概念,為什麼要在機器學習之前學習
非線性 SVM 算法
在 SVM 分類器中,在這兩個類之間有一個線性超平面是直截了當的。 但是,一個有趣的問題是,如果數據不是線性可分的,該怎麼辦? 為此,SVM 算法有一種稱為核技巧的方法。
SVM 核函數接受低維輸入空間並將其轉換為高維空間。 簡而言之,它將不可分離的問題轉換為可分離的問題。 它根據定義它們的標籤或輸出執行複雜的數據轉換
查看下圖以更好地理解數據轉換。 左邊的數據點集顯然不是線性可分的。 但是,當我們將函數 Φ 應用於數據點集時,我們會得到更高維度的轉換數據點,該維度可通過平面分離。
形象學分
為了分離非線性可分的數據點,我們必須添加一個額外的維度。 對於線性數據,使用了兩個維度,即 x 和 y。 對於這些數據點,我們添加了第三個維度,比如 z。 對於下面的示例,讓 z=x² +y²。
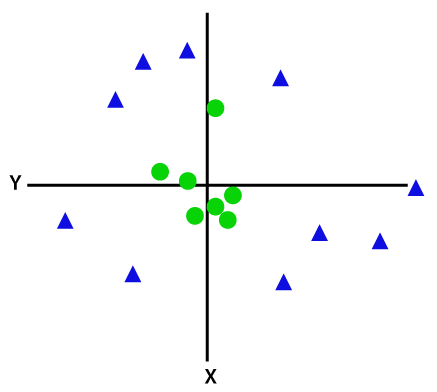
形象學分
這個 z 函數或添加的維度對樣本空間進行變換,上圖將變為如下:
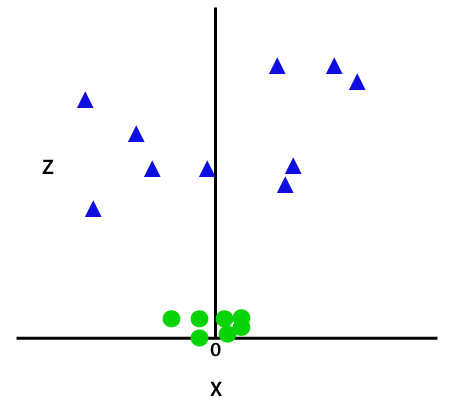
形象學分
仔細分析後,很明顯,上述數據點可以使用平行於 x 軸或傾斜角度的直線函數分離。 存在不同類型的核函數——線性、非線性、多項式、徑向基函數 (RBF) 和 sigmoid。
簡單來說,RBF 所做的是——如果我們選擇某個點,RBF 的結果將是該點與某個固定點之間距離的範數。 換句話說,我們可以用這個 RBF 的產量來設計 z 維度,它通常根據點與某個點的距離來給出“高度”。
查看:您需要了解的 6 種神經網絡激活函數
選擇哪個內核?
確定哪個內核最合適的一個好方法是製作具有不同內核的各種模型,然後估計它們的每個性能,並最終比較結果。 然後你選擇結果最好的內核。 特別是通過使用 K-Fold 交叉驗證來估計模型在不同觀測值上的性能,並考慮不同的指標,如準確度、F1 分數等。
Python 和 R 中的 SVM
python 中的 fit 方法只是在已分離的 Xtrain 和 ytrain 數據上訓練 SVM 模型。 更具體地說,fit 方法將組合 Xtrain 和 ytrain 中的數據,並據此計算兩個支持向量。
一旦估計了這些支持向量,分類器模型就完全設置為使用預測函數產生新的預測,因為它只需要支持向量來分離新數據。 現在你可能在 Python 和 R 中得到不同的結果,所以一定要檢查種子參數的值。
結論
在本文中,我們詳細研究了支持向量機算法。 謝謝你的時間。 收看更多此類文章。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
支持向量機模型適用於哪些類型的問題?
支持向量機 (SVM) 最適用於線性可分數據,即可以使用直線或超平面將數據分成兩個不同的類別。 SVM 最常見的用途之一是人臉識別。 eigenfaces 技術是 SVM 的一個例子,它對面部圖像進行降維並用於面部識別。 該技術基於這樣的前提,即人臉可以被認為是高維向量空間中的向量,並且通過將超球面擬合到數據來降低維數。 這允許我們匹配兩個不同大小或旋轉的面。 SVM 也用於分類。
SVM在現實生活中有哪些應用?
SVM 可以用於連續數據嗎?
SVM 用於創建分類模型。 所以,如果你有一個分類器,它只能與兩個類一起工作。 如果你有連續的數據,那麼你必須把這些數據變成類,這個過程稱為降維。 例如,如果您有年齡、身高、體重、年級等信息,那麼您可以取該數據的平均值,使其更接近某一類或另一類,這將使分類更容易。