
使用人工神經網絡 (ANN) 的分類模型
已發表: 2020-12-01在機器學習術語中,分類是指預測建模問題,其中輸入數據被分類為預定義的標記類之一。 例如,預測是或否、真或假屬於二元分類類別,因為輸出的數量僅限於兩個標籤。
類似地,具有多個類別的輸出(例如對不同年齡組進行分類)稱為多類別分類問題。 分類問題是最常用或定義的 ML 問題類型之一,可用於各種用例。 有多種機器學習模型可用於分類問題。
從 Bagging 到 Boosting 技術雖然 ML 不僅能夠處理分類用例,但當我們擁有大量輸出類和大量數據來支持模型的性能時,神經網絡就會出現。 展望未來,我們將研究如何使用 Keras 上的神經網絡 (Python) 實現分類模型。
向世界頂尖大學學習人工智能課程。 獲得碩士、Executive PGP 或高級證書課程以加快您的職業生涯。
目錄
神經網絡
神經網絡鬆散地代表了人類大腦的學習。 人工神經網絡由神經元組成,而神經元又負責創建層。 這些神經元也稱為調諧參數。
每一層的輸出被傳遞到下一層。 每一層都有不同的非線性激活函數,這有助於學習過程和每一層的輸出。 輸出層也稱為終端神經元。

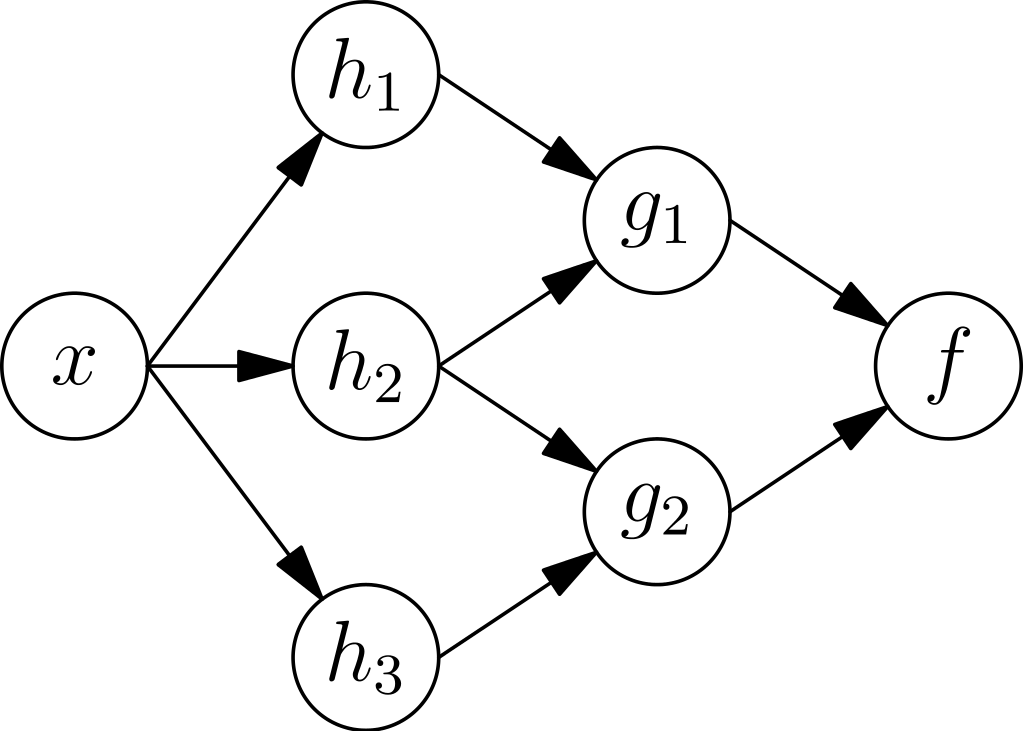
資料來源:維基百科
與神經元相關的權重和負責整體預測的權重在每個時期更新。 使用各種優化器優化學習率。 每個神經網絡都提供了一個成本函數,該函數隨著學習的繼續而最小化。 然後使用成本函數給出最佳結果的最佳權重。
閱讀:面向初學者的 TensorFlow 對象檢測教程
分類問題
在本文中,我們將使用 Keras 構建神經網絡。 可以使用以下命令在 python 中直接導入 Keras。
將張量流導入為 tf
從張量流導入 keras
從 keras.models 導入順序
從 keras.layers 導入密集
數據集和目標變量
我們將使用具有以下特徵的糖尿病數據集:
輸入變量 (X):
- 懷孕次數:懷孕次數
- 葡萄糖:口服葡萄糖耐量試驗中 2 小時的血漿葡萄糖濃度
- 血壓:舒張壓 (mm Hg)
- SkinThickness:三頭肌皮褶厚度(mm)
- 胰島素:2 小時血清胰島素 (mu U/ml)
- BMI:體重指數(體重公斤/(身高米)^2)
- DiabetesPedigreeFunction:糖尿病譜系函數
- 年齡:年齡(歲)
輸出變量(y):
結果:類別變量(0 或 1)[患者是否患有糖尿病]
# 加載數據集
df= loadtxt('pima-indians-diabetes.csv', delimiter=',')
# 將數據拆分為 X(輸入)和 Y(輸出)
X = 數據集[:,0:8]
y = 數據集[:,8]
定義 Keras 模型
我們可以開始使用順序模型構建神經網絡。 這種自上而下的方法有助於構建神經網絡架構並使用形狀和層。 第一層將具有可以使用 input_dim 修復的特徵數量。 在這種情況下,我們將其設置為 8。

創建神經網絡並不是一個非常容易的過程。 在建立一個好的模型之前,會發生許多試驗和錯誤。 我們將使用 keras 中的 Dense 類構建一個全連接的網絡結構。 神經元算作要提供給密集層的第一個參數。
可以使用激活參數設置激活函數。 在這種情況下,我們將使用 Rectified Linear Unit 作為激活函數。 還有其他選項,例如 Sigmoid 或 TanH,但 RELU 是一個非常通用且更好的選擇。
# 定義keras模型
模型=順序()
model.add(密集(12,input_dim=8,激活='relu'))
model.add(密集(8,激活='relu'))
model.add(密集(1,激活='sigmoid'))
編譯 Keras 模型
編譯模型是模型定義之後的下一步。 TensorFlow 用於模型編譯。 編譯是為模型訓練和預測設置參數的過程。 CPU/GPU 或分佈式內存可以在後台使用。
我們必須指定一個損失函數,用於評估不同層的權重。 優化器調整學習率並通過各種權重集。 在這種情況下,我們將使用二元交叉熵作為損失函數。 在優化器的情況下,我們將使用 ADAM,它是一種有效的隨機梯度下降算法。
它非常普遍地用於調音。 最後,因為這是一個分類問題,我們將收集並報告分類準確度,通過度量參數定義。 在這種情況下,我們將使用準確性。
# 編譯keras模型
model.compile(loss='binary_crossentropy',優化器='adam',metrics=['accuracy'])
模型擬合和評估
擬合模型本質上稱為模型訓練。 編譯模型後,模型準備好有效地檢查數據並進行自我訓練。 Keras 的 fit() 函數可用於模型訓練過程。 模型訓練前使用的兩個主要參數是:
- Epochs:遍歷整個數據集。
- 批量大小:每個批量大小都會更新權重。 時期由均勻分佈的數據批次組成。
# 在數據集上擬合 keras 模型
model.fit(X, y, epochs=150, batch_size=10)
在此過程中使用 GPU 或 CPU。 訓練可能是一個非常漫長的過程,具體取決於時期、批量大小,最重要的是數據的大小。
我們還可以使用 evaluate() 函數在訓練數據集上評估模型。 數據可分為訓練集和測試集,測試 X 和 Y 可用於模型評估。
對於每個輸入和輸出對,這將產生一個預測並收集分數,包括平均損失和我們安裝的任何測量值,例如精度。
evaluate() 函數將返回一個包含兩個值的列表。 第一個是數據集上的模型損失,第二個是模型在數據集上的準確性。 我們只對報告的準確性感興趣,因此我們將忽略損失的重要性。
# 評估 keras 模型
_, 準確度 = model.evaluate(Xtest, ytest)
print('準確度: %.2f' % (準確度*100))
另請閱讀:神經網絡模型介紹
結論
我們創建並評估了一個基於分類的神經網絡。 儘管在這種情況下使用的數據很小,但神經網絡主要適用於大型數值數據集。
查看 upGrad 的機器學習和 NLP 高級證書課程。 本課程的設計考慮到對機器學習感興趣的各種學生,提供 1-1 指導等等。
神經網絡如何用於分類?
分類是將對象分類為組。 一種分類是預測多個類別的地方。 在神經網絡中,神經單元被組織成層。 在第一層,處理輸入並產生輸出。 然後將該輸出通過其餘層發送以產生最終輸出。 通過層處理相同的輸入以產生不同的輸出。 這可以用多層感知器來表示。 用於分類的神經網絡類型取決於數據集,但神經網絡已用於分類問題。
為什麼人工神經網絡有利於分類?
為了回答這個問題,我們需要了解神經網絡的基本原理以及神經網絡旨在解決的問題。 顧名思義,神經網絡是受生物啟發的人腦模型。 基本思想是我們希望將神經元建模為數學函數。 每個神經元從其他神經元獲取輸入併計算輸出。 然後我們以一種模仿大腦神經網絡的方式連接這些神經元。 目標是學習一個可以接收一些數據並產生適當輸出的網絡。
我們什麼時候應該使用人工神經網絡?
人工神經網絡用於嘗試複製生物體的性能或檢測數據模式的情況。 醫療診斷、識別語音、可視化數據和預測手寫數字都是 ANN 的好用例。 當需要了解輸入和輸出之間的複雜關係時,會使用人工神經網絡。 例如,變量中可能存在很多噪聲,並且可能難以理解這些變量之間的關係。 因此,使用人工神經網絡是保留知識和數據的常見做法。