
卷積神經網絡架構:你需要知道什麼?
已發表: 2020-12-01卷積神經網絡通常被稱為 ConvNets 或 CNN 等名稱,是最常用的神經網絡架構之一。 CNN 通常用於基於圖像的數據。 圖像識別、圖像分類、對象檢測等是 CNN 廣泛使用的一些領域。
專門針對圖像數據的應用 AI 的分支被稱為計算機視覺。 自從引入 CNN 以來,計算機視覺有了巨大的發展。 CNN 的第一部分使用卷積和激活函數從圖像中提取特徵進行歸一化。
最後一個塊將這些功能與神經網絡一起使用來解決任何特定問題,例如,分類問題將具有“n”個輸出神經元,具體取決於分類存在的類數。 讓我們嘗試了解 CNN 的架構和工作原理。
目錄
卷積
卷積是一種圖像處理技術,它使用加權核(方陣)在圖像上旋轉,將核元素與圖像像素相乘和相加。 該方法可以通過下圖輕鬆可視化。
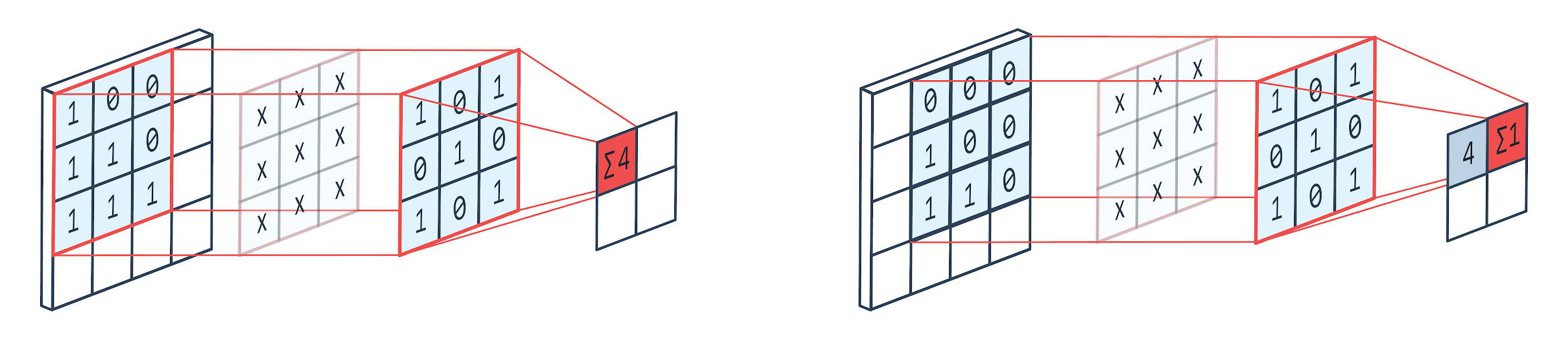
圖片提供: Peltarion
卷積濾波器和輸出

正如我們所看到的,當我們使用 3×3 卷積 kennel 時,對圖像的 3×3 部分進行運算,在乘法和隨後的加法之後,一個值作為輸出。 所以在一個 4×4 的圖像上,我們將得到一個 2×2 的捲積矩陣輸出,因為內核大小是 3×3。
卷積輸出可能會因用於卷積的內核大小而異。 這是 CNN 的典型起始層。 卷積輸出是從圖像中找到的特徵。 這與所使用的內核大小直接相關。
如果圖像的特徵是即使圖像中的微小差異也會使其落入不同的輸出類別,則使用較小的內核大小進行特徵提取。 否則可以使用更大的內核。 內核中使用的值通常稱為卷積權重。 這些被初始化,然後在使用梯度下降的反向傳播時更新。
閱讀:面向初學者的 TensorFlow 對象檢測教程
匯集
池化層位於卷積層之間。 它負責對卷積層發送的特徵圖進行池化操作。 池化操作減少了特徵的空間大小,也稱為降維。
池化的主要原因之一是減少處理數據所需的計算能力。 雖然,池化層減小了圖像的大小,但它保留了它們的重要特徵。 工作類似於 CNN 過濾器。 內核遍歷特徵並聚合過濾器覆蓋的值。
從圖像中可以清楚地看到可以有各種聚合函數。 平均池化和最大池化是最常用的池化操作。 池化減少了特徵的維度,但保持了特徵的完整性。
通過減少參數的數量,網絡中的計算也減少了。 這減少了過度學習並提高了網絡的效率。 最大池最常用,因為與卷積映射相比,在池化映射中發現最大值的準確度較低。
這對很多情況都有好處。假設如果要識別一隻狗,它的耳朵不需要盡可能精確地定位,知道它們幾乎位於頭部附近就足夠了。
Max Pooling 還可以用作噪聲抑制器。 它完全丟棄了嘈雜的激活,並在降維的同時執行去噪。 另一方面,平均池化只是簡單地執行降維作為一種噪聲抑制機制。 因此,我們可以說 Max Pooling 的性能比 Average Pooling 好很多。
激活函數
ReLU(Rectified Linear Units)是最常用的激活函數層。
相同的方程是:ReLU(x)=max(0,x)
圖形表示如下:
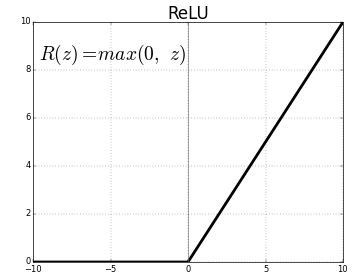
資料來源:中
ReLU 表示
ReLU 將負值映射為零並保持正值不變。
全連接層
全連接層通常是任何神經網絡的最後一層。 該層接收輸入向量並產生一個新的輸出層。 該輸出層有 n 個神經元,其中 n 是圖像分類中的類數。 向量的每個元素都提供了圖像屬於某個類別的概率。 因此,輸出層中所有向量的總和始終為 1。

輸出層中發生的計算如下:
- 元素乘以神經元的權重
- 在層上應用激活函數(n=2 時為邏輯,n>2 時為 sigmoid)
輸出現在將是圖像屬於某個類別的概率。 在訓練期間通過梯度的反向傳播來學習層的權重。
另請閱讀:神經網絡模型介紹
輟學層
Dropout 層用作正則化層,可減少過度擬合併改善泛化誤差。 使用神經網絡時,過度擬合是一個主要問題。 顧名思義,Dropout 在使用它的層中丟棄了一定百分比的神經元。
dropout 採用的正則化方法是近似訓練大量具有不同並行架構的神經網絡。 在訓練期間,一些層輸出被隨機丟棄或忽略。 這使得該層看起來像一個具有不同數量節點的層,並且一些神經元被關閉。 因此,連接性也會根據前一層而改變。
超參數
有一些參數可以根據所處理的圖像數據進行控制。 CNN 的每一層都可以參數化,無論是卷積層還是池化層。 參數影響作為該特定層輸出的特徵圖的大小。
每個圖像(輸入)或特徵圖(層的後續輸出)的尺寸為:W x H x D 其中 W x H 是寬 x 高,即圖或圖像的大小。 D 表示基於顏色段的尺寸。 單色圖像的 D=1 和 RGB 即彩色圖像的 D=3。
卷積層超參數
- 過濾器數量 (K)
- 尺寸 FxFxD 的過濾器大小 (F)
- 步幅:內核在圖像上移動所採取的步數。 S=1 表示內核將以 1 個像素為步長移動。
- 零填充:對尺寸較小的圖像進行零填充,因為卷積和最大池層在每次迭代時都會減小特徵圖的大小。
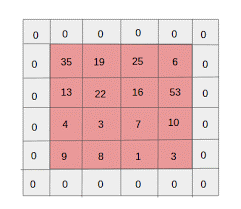
資料來源: XRDS
零填充增加了輸入圖像的大小
對於大小為 W×H×D 的每個輸入圖像,池化層返回一個維度為 Wc×Hc×Dc 的矩陣。 在哪裡
Wc= (W-F+2P)/S+1
Hc= (H-F+2P)/S+1
直流= K
求解方程以找到 Padding(P)=F-1/2 和 Stride(S)=1 的值
一般來說,我們然後選擇 F=3,P=1,S=1 或 F=5,P=2,S=1
池化層超參數
- 單元格大小 (F):將在其中劃分地圖以進行池化的方形單元格大小。 FxF
- 步長 (S):單元格被 S 個像素分隔
對於每個大小為 W×H×D 的輸入圖像,池化層返回一個維度為 Wp×Hp×Dp 的矩陣,其中
Wp= (WF)/S+1
Hp= (HF)/S+1
DP=D
對於池化層,廣泛選擇 F=2 和 S=2。 75% 的輸入像素被消除。 也可以選擇 F=3 和 S=2。 較大的單元格大小將導致大量信息丟失,因此僅適用於非常大尺寸的輸入圖像。
通用超參數
- 學習率:可以選擇 SGD、AdaGrad 或 RMSProp 等優化器來優化學習率。
- 時期:應該增加時期的數量,直到出現訓練和驗證錯誤的差距
- 批量大小:可以選擇 16 到 128。 取決於一個人擁有的處理能力。
- 激活函數:將非線性引入模型。 ReLu 通常用於 Conv Nets。 其他選項是:sigmoid、tanh。
- Dropout:0.1 的 dropout 值會丟棄 10% 的神經元。 0.5 是一個很好的起點。 0.25 是一個不錯的最終選擇。
- 權重初始化:可以初始化小的隨機權重以轉移死亡神經元的可能性。 但對於梯度下降來說不算太小。 適合均勻分佈。
- 隱藏層:可以增加隱藏層,直到測試誤差減小。 增加隱藏層將增加計算量並需要正則化。
結論
我們擁有從頭開始創建 CNN 的基本信息。 雖然它是一篇綜合性文章,涵蓋了基礎層面的所有內容,但可以深入研究每個參數或層。 每個概念背後的數學也是可以理解的,以改進模型
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。