關於 Apache Storm 你需要知道的一切
已發表: 2018-02-20大數據生產和分析的不斷增長不斷提出新的挑戰,數據科學家和程序員通過不斷改進他們開發的應用程序,優雅地從容應對。 一個這樣的問題是實時流。 實時數據對企業具有極高的價值,但它有一個時間窗口,在此之後它就會失去價值——如果你願意的話,還有一個到期日。 如果這個實時數據的價值沒有在窗口內實現,就不能從中提取任何有用的信息。 這種實時數據快速而連續地進入,因此稱為“流式傳輸”。
對這些實時數據的分析可以幫助您及時了解當前正在發生的事情,例如閱讀您的博客文章的人數,或訪問您的 Facebook 頁面的人數。 雖然它可能聽起來只是一個“不錯的”功能,但在實踐中,它是必不可少的。 想像一下,您是一家廣告公司的一員,對您的廣告活動進行實時分析——客戶為此付出了高昂的代價。 實時分析可以讓您隨時了解您的廣告在市場上的表現如何、用戶對其的反應以及其他類似的事情。 如果您這樣想的話,這是一個非常重要的工具,對吧?
著眼於實時數據所具有的價值,組織開始提出各種實時數據分析工具。 在本文中,我們將討論其中之一——Apache Storm。 我們將看看它是什麼,一個典型的 Storm 應用程序的架構,它的核心組件(也稱為抽象),以及它的真實生活用例。
我們走吧!
目錄
什麼是阿帕奇風暴?

Apache Storm – 由 Twitter 發布,是一個分佈式開源框架,有助於實時處理數據。 Apache Storm 處理實時數據,就像 Hadoop 處理數據批處理一樣(批處理與實時相反。在這裡,數據被分成批處理,每個批處理都被處理。這不是真正的-時間。)
Apache Storm 沒有任何狀態管理功能,並且嚴重依賴 Apache ZooKeeper(用於管理大數據應用程序中的配置的集中服務)來管理其集群狀態——例如消息確認、處理狀態和其他此類消息。 Apache Storm 的應用程序以有向無環圖的形式設計。 它以每個節點每秒處理超過一百萬個元組而聞名 - 這是高度可擴展的並提供處理作業保證。 Storm 是用 Clojure 編寫的,它是一種類似 Lisp 的函數式優先編程語言。

Apache Storm 的核心是用於定義和提交邏輯圖(也稱為拓撲)的“Thrift 定義”。 由於 Thrift 可以用您選擇的任何語言實現,因此也可以用任何語言創建拓撲。 這使得 Storm 支持多種語言 - 使其對開發人員更加友好。
Storm 在 YARN 上運行,並與 Hadoop 生態系統完美集成。 它是一個真正的實時數據處理框架,支持零批處理。 它將完整的數據流作為一個完整的“事件”,而不是將其分成一系列小批量。 因此,它最適合作為單個實體攝取的數據。
讓我們看一下 Storm 應用程序的一般架構——它將讓您更深入地了解 Storm 的工作原理!
Apache Storm:通用架構和重要組件
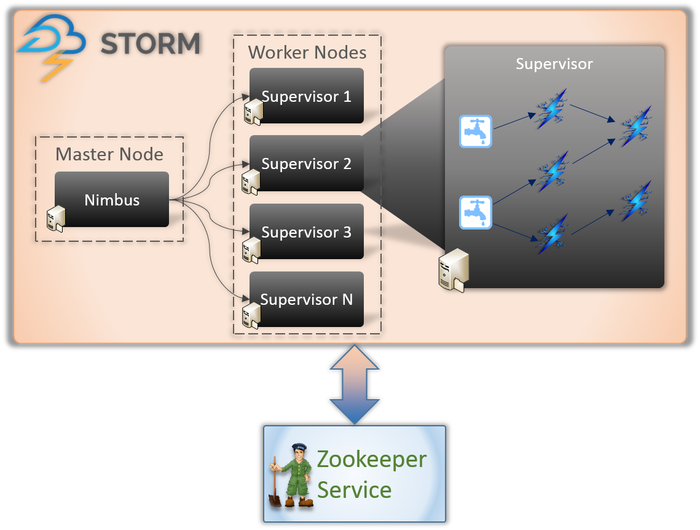
任何 Storm 應用程序都涉及兩種類型的節點(如上所示)。
主節點(Nimbus 服務)
如果您了解 Hadoop 的內部工作原理,那麼您必須知道什麼是“作業跟踪器”。 它是運行在 Hadoop 的 Master 節點上的守護進程,負責在節點之間分配任務。 Nimbus 是 Storm 的一種類似服務。 它運行在 Storm 集群的主節點上,負責在工作節點之間分配任務。
Nimbus 是 Apache 提供的 Thrift 服務,它允許您以您選擇的編程語言提交代碼。 這可以幫助您編寫應用程序,而無需學習專門針對 Storm 的新語言。
正如我們之前所說,Storm 缺乏任何狀態管理功能。 Nimbus 服務必須依靠 ZooKeeper 來監控工作節點在處理任務時發送的消息。 所有工作節點都會在 ZooKeeper 服務中更新其任務狀態,以供 Nimbus 查看和監控。
工作節點(主管服務)
這些是負責執行任務的節點。 Storm 中的工作節點運行一個名為 Supervisor 的服務。 Supervisor 負責接收 Nimbus 服務分配給機器的工作。 顧名思義,Supervisor 監督工作進程並幫助他們完成分配的任務。 這些工作進程中的每一個都執行完整拓撲的一個子集。

Storm 應用程序本質上具有四個組件/抽象,它們負責執行手頭的任務。 這些是:
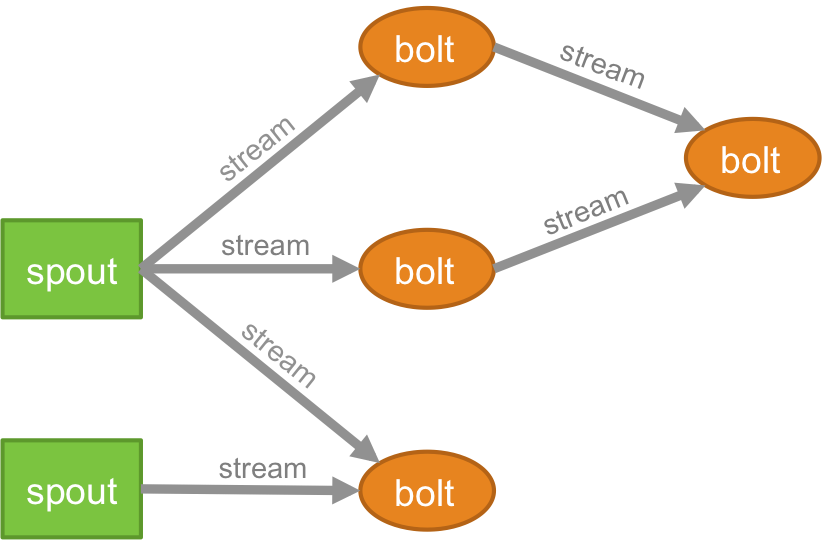
拓撲
任何實時應用程序的邏輯都以拓撲的形式打包——本質上是一個螺栓和噴口的網絡。 為了更好地理解,您可以將其與 MapReduce 作業進行比較(如果您不知道那是什麼,請閱讀我們關於 MapReduce 的文章!)。 一個關鍵的區別是 MapReduce 作業在其執行完成時完成,而 Storm 拓撲將永遠運行(除非您自己明確地殺死它)。 網絡由形成處理邏輯的節點和演示數據傳遞和流程執行的鏈接(也稱為流)組成。
溪流
在了解什麼是流之前,您需要了解什麼是元組。 元組是 Storm 集群中的主要數據結構。 這些是命名的值列表,其中值可以是從整數、長整數、短整數、字節、雙精度、字符串、布爾浮點數到字節數組的任何值。 現在,.streams 是在分佈式環境中實時創建和處理的元組序列。 它們構成了 Spark 集群的核心抽象單元。
噴口
新芽是 Storm 元組中流的來源。 它負責與實際的數據源取得聯繫,不斷地接收數據,將這些數據轉換成實際的元組流,最後發送到bolts進行處理。 它可以是可靠的,也可以是不可靠的。 如果 Storm 處理失敗,可靠的 Spout 將重播該元組,另一方面,不可靠的 Spout 將在發出元組後很快忘記該元組。
螺栓
螺栓負責執行拓撲的所有處理。 它們構成了 Storm 應用程序的處理邏輯單元。 可以利用 Bolt 執行許多基本操作,例如過濾、函數、連接、聚合、連接到數據庫等等。
誰使用風暴?
儘管在大數據市場中出現了許多功能強大且易於使用的工具,但 Storm 在該列表中找到了一個獨特的位置,因為它能夠處理您扔給它的任何編程語言。 許多組織使用 Storm。
讓我們看看幾個使用 Apache Storm 的大玩家以及如何使用它!
推特

Twitter 使用 Storm 為其各種系統提供動力——從您的訂閱源的個性化、收入優化到改進搜索結果和其他此類流程。 由於 Twitter 開發了 Storm(後來被 Apache 收購併命名為 Apache Storm),它與 Twitter 的其他基礎設施——數據庫系統(Cassandra、Memcached 等)、消息傳遞環境(Mesos)和監控系統無縫集成.
Spotify

Spotify 以向超過 5000 萬活躍用戶和 1000 萬訂閱者提供流媒體音樂而聞名。 它提供了廣泛的實時功能,如音樂推薦、監控、分析、廣告定位和播放列表創建。 為了實現這一壯舉,Spotify 使用了 Apache Storm。
Apache Storm 與基於 Kafka、Memcached 和 netty-zmtp 的消息傳遞環境堆疊在一起,使 Spotify 能夠輕鬆構建低延遲容錯分佈式系統。
總結…
如果您希望建立自己的大數據分析師職業生涯,那麼流媒體是您的最佳選擇。 如果您能夠掌握處理實時數據的藝術,那麼您將成為招聘分析師職位的公司的第一選擇。 現在是深入研究實時數據分析的最佳時機,因為這是真正意義上的小時需求!
如果您有興趣了解有關大數據的更多信息,請查看我們的 PG 大數據軟件開發專業文憑課程,該課程專為在職專業人士設計,提供 7 多個案例研究和項目,涵蓋 14 種編程語言和工具,實用的動手操作研討會,超過 400 小時的嚴格學習和頂級公司的就業幫助。

從世界頂級大學在線學習軟件工程學位。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。