ทุกสิ่งที่คุณจำเป็นต้องรู้เกี่ยวกับ Apache Storm
เผยแพร่แล้ว: 2018-02-20การเติบโตที่เพิ่มมากขึ้นเรื่อยๆ ในการผลิตและการวิเคราะห์ของ Big Data ทำให้เกิดความท้าทายใหม่ๆ อยู่เสมอ และนักวิทยาศาสตร์ข้อมูลและโปรแกรมเมอร์ก็นำมันไปสู่การก้าวย่างอย่างงดงาม ด้วยการปรับปรุงแอปพลิเคชันที่พัฒนาโดยพวกเขาอย่างต่อเนื่อง ปัญหาอย่างหนึ่งก็คือการสตรีมแบบเรียลไทม์ ข้อมูลแบบเรียลไทม์มีมูลค่าสูงมากสำหรับธุรกิจ แต่มีกรอบเวลาหลังจากนั้นจะสูญเสียมูลค่าไป – วันหมดอายุหากคุณต้องการ หากไม่ทราบค่าของข้อมูลตามเวลาจริงภายในหน้าต่าง จะไม่มีการดึงข้อมูลที่ใช้งานได้ออกมา ข้อมูลเรียลไทม์นี้เข้ามาอย่างรวดเร็วและต่อเนื่อง จึงเรียกว่า “สตรีมมิ่ง”
การวิเคราะห์ข้อมูลตามเวลาจริงนี้สามารถช่วยให้คุณได้รับการอัปเดตเกี่ยวกับสิ่งที่เกิดขึ้นในขณะนี้ เช่น จำนวนคนที่อ่านบล็อกโพสต์ของคุณ หรือจำนวนผู้ที่เข้าชมหน้า Facebook ของคุณ แม้ว่าอาจดูเหมือนเป็นคุณลักษณะที่ "น่ามี" แต่ในทางปฏิบัติ มันเป็นสิ่งจำเป็น ลองนึกภาพว่าคุณเป็นส่วนหนึ่งของเอเจนซี่โฆษณาที่ทำการวิเคราะห์แบบเรียลไทม์กับแคมเปญโฆษณาของคุณ ซึ่งลูกค้าจ่ายเงินให้จำนวนมาก การวิเคราะห์ตามเวลาจริงสามารถแจ้งให้คุณทราบเกี่ยวกับประสิทธิภาพของโฆษณาในตลาด วิธีที่ผู้ใช้ตอบสนองต่อโฆษณา และสิ่งอื่น ๆ ที่มีลักษณะเช่นนั้น ค่อนข้างเป็นเครื่องมือที่จำเป็นถ้าคุณคิดแบบนี้ใช่ไหม
เมื่อพิจารณาถึงคุณค่าของข้อมูลแบบเรียลไทม์ องค์กรต่างๆ ก็เริ่มสร้างเครื่องมือวิเคราะห์ข้อมูลแบบเรียลไทม์ต่างๆ ในบทความนี้ เราจะมาพูดถึงหนึ่งในนั้น – Apache Storm เราจะมาดูกันว่ามันคืออะไร สถาปัตยกรรมของแอปพลิเคชั่นพายุทั่วไป มันเป็นองค์ประกอบหลัก (หรือที่เรียกว่านามธรรม) และกรณีการใช้งานจริงของมัน
ไปกันเถอะ!
สารบัญ
Apache Storm คืออะไร?

Apache Storm – เผยแพร่โดย Twitter เป็นเฟรมเวิร์กโอเพนซอร์ซแบบกระจายที่ช่วยในการประมวลผลข้อมูลแบบเรียลไทม์ Apache Storm ทำงานสำหรับข้อมูลแบบเรียลไทม์ เช่นเดียวกับ Hadoop ทำงานสำหรับการประมวลผลข้อมูลแบบกลุ่ม (การประมวลผลแบบกลุ่มจะตรงกันข้ามกับแบบเรียลไทม์ ในที่นี้ ข้อมูลจะถูกแบ่งออกเป็นกลุ่ม และแต่ละกลุ่มจะได้รับการประมวลผล ซึ่งไม่ได้ทำจริง -เวลา.)
Apache Storm ไม่มีความสามารถในการจัดการสถานะและอาศัย Apache ZooKeeper (บริการส่วนกลางสำหรับจัดการการกำหนดค่าในแอปพลิเคชัน Big Data) เพื่อจัดการสถานะคลัสเตอร์ เช่น การรับรู้ข้อความ สถานะการประมวลผล และข้อความอื่นๆ Apache Storm มีแอพพลิเคชั่นที่ออกแบบในรูปแบบของกราฟอะไซคลิกโดยตรง เป็นที่รู้จักสำหรับการประมวลผลมากกว่าหนึ่งล้านทูเพิลต่อวินาทีต่อโหนด ซึ่งสามารถปรับขนาดได้สูงและให้การรับประกันงานในการประมวลผล Storm เขียนด้วย Clojure ซึ่งเป็นภาษาการเขียนโปรแกรมที่เน้นการทำงานแบบ Lisp

หัวใจของ Apache Storm คือ "คำจำกัดความของ Thrift" สำหรับการกำหนดและส่งกราฟลอจิก (หรือที่เรียกว่าโทโพโลยี) เนื่องจาก Thrift สามารถใช้งานได้ในภาษาใดก็ได้ที่คุณเลือก โทโพโลยีก็สามารถสร้างในภาษาใดก็ได้ สิ่งนี้ทำให้ Storm รองรับหลายภาษา – ทำให้เป็นมิตรกับนักพัฒนามากขึ้น
Storm ทำงานบน YARN และรวมเข้ากับระบบนิเวศ Hadoop ได้อย่างสมบูรณ์แบบ เป็นเฟรมเวิร์กการประมวลผลข้อมูลตามเวลาจริงที่มีการสนับสนุนแบตช์เป็นศูนย์ ใช้สตรีมข้อมูลทั้งหมดเป็น 'เหตุการณ์' ทั้งหมด แทนที่จะแบ่งเป็นกลุ่มย่อยๆ ดังนั้นจึงเหมาะที่สุดสำหรับข้อมูลที่จะนำเข้าเป็นเอนทิตีเดียว
มาดูสถาปัตยกรรมทั่วไปของแอปพลิเคชั่น Storm กันดีกว่า – มันจะทำให้คุณเข้าใจมากขึ้นว่า Storm ทำงานอย่างไร!
Apache Storm: สถาปัตยกรรมทั่วไปและส่วนประกอบที่สำคัญ
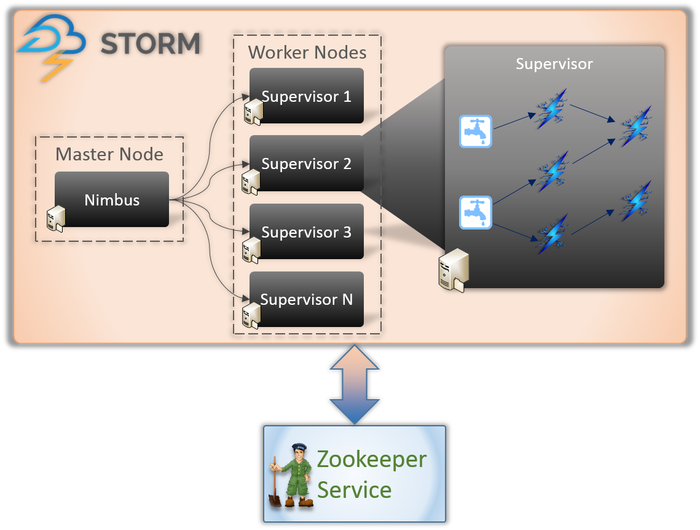
โดยพื้นฐานแล้วมีโหนดสองประเภทที่เกี่ยวข้องกับแอปพลิเคชัน Storm (ดังที่แสดงด้านบน)
มาสเตอร์โหนด (บริการ Nimbus)
หากคุณทราบถึงการทำงานภายในของ Hadoop คุณต้องรู้ว่า 'ตัวติดตามงาน' คืออะไร มันเป็นภูตที่ทำงานบนโหนดมาสเตอร์ของ Hadoop และมีหน้าที่รับผิดชอบในการกระจายงานระหว่างโหนด Nimbus เป็นบริการที่คล้ายคลึงกันสำหรับ Storm มันทำงานบน Master Node ของคลัสเตอร์ Storm และรับผิดชอบในการกระจายงานระหว่างโหนดของผู้ปฏิบัติงาน
Nimbus เป็นบริการ Thrift ที่ให้บริการโดย Apache ซึ่งช่วยให้คุณส่งรหัสของคุณในภาษาการเขียนโปรแกรมที่คุณเลือก ซึ่งจะช่วยให้คุณเขียนใบสมัครโดยไม่ต้องเรียนรู้ภาษาใหม่สำหรับ Storm โดยเฉพาะ
ดังที่เราได้กล่าวไว้ก่อนหน้านี้ Storm ขาดความสามารถในการจัดการของรัฐ บริการ Nimbus ต้องพึ่งพา ZooKeeper เพื่อตรวจสอบข้อความที่ส่งโดยโหนดผู้ปฏิบัติงานขณะประมวลผลงาน โหนดผู้ปฏิบัติงานทั้งหมดอัปเดตสถานะงานในบริการ ZooKeeper เพื่อให้ Nimbus ดูและตรวจสอบ
โหนดคนงาน (บริการหัวหน้างาน)
เหล่านี้เป็นโหนดที่รับผิดชอบในการปฏิบัติงาน โหนดผู้ปฏิบัติงานใน Storm เรียกใช้บริการที่เรียกว่า Supervisor หัวหน้างานมีหน้าที่รับผิดชอบในการรับงานที่มอบหมายให้กับเครื่องโดยบริการ Nimbus ตามชื่อที่แนะนำ หัวหน้างานจะกำกับดูแลกระบวนการของผู้ปฏิบัติงานและเพื่อช่วยให้พวกเขาทำงานที่ได้รับมอบหมายให้เสร็จสมบูรณ์ แต่ละกระบวนการของผู้ปฏิบัติงานเหล่านี้ดำเนินการชุดย่อยของโทโพโลยีที่สมบูรณ์

แอปพลิเคชัน Storm มีองค์ประกอบ/นามธรรมสี่ประการที่รับผิดชอบในการปฏิบัติงานในมือ เหล่านี้คือ:
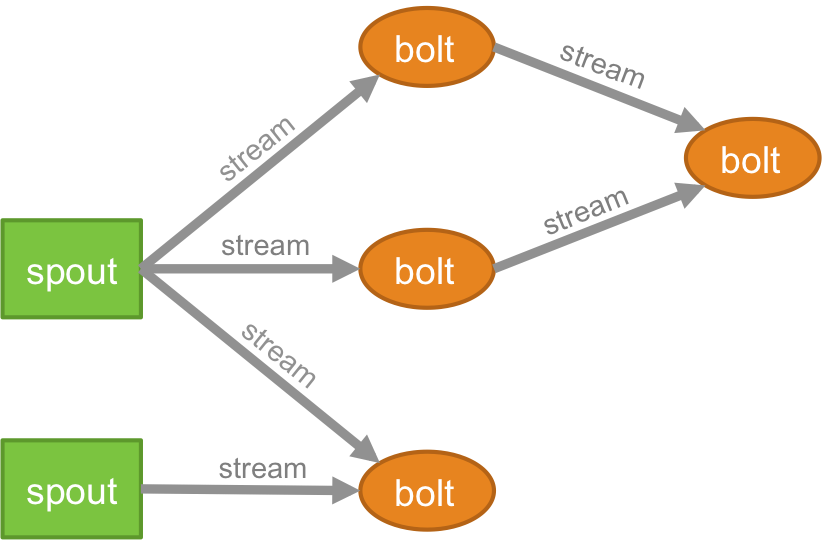
โทโพโลยี
ตรรกะสำหรับแอปพลิเคชันแบบเรียลไทม์ใดๆ ถูกบรรจุไว้ในรูปแบบของโทโพโลยี – ซึ่งโดยพื้นฐานแล้วคือเครือข่ายของสลักเกลียวและรางน้ำ เพื่อให้เข้าใจดีขึ้น คุณสามารถเปรียบเทียบกับงาน MapReduce ได้ (อ่านบทความของเราเกี่ยวกับ MapReduce หากคุณไม่ทราบว่ามันคืออะไร!) ข้อแตกต่างที่สำคัญประการหนึ่งคืองาน MapReduce จะเสร็จสิ้นเมื่อการดำเนินการเสร็จสิ้น ในขณะที่โทโพโลยีของ Storm จะทำงานตลอดไป (เว้นแต่คุณจะฆ่ามันเองอย่างชัดแจ้ง) เครือข่ายประกอบด้วยโหนดที่สร้างตรรกะการประมวลผล และลิงก์ (หรือที่เรียกว่าสตรีม) ที่แสดงการส่งข้อมูลและการดำเนินการของกระบวนการ
ลำธาร
คุณต้องเข้าใจสิ่งที่เป็นทูเพิลก่อนที่จะเข้าใจว่าอะไรคือสตรีม Tuples เป็นโครงสร้างข้อมูลหลักในกลุ่ม Storm เหล่านี้เป็นรายการของค่าที่มีชื่อซึ่งค่าสามารถเป็นอะไรก็ได้ตั้งแต่จำนวนเต็ม, ลอง, ชอร์ต, ไบต์, คู่, สตริง, บูลีนลอย, ไปจนถึงอาร์เรย์ไบต์ ตอนนี้ .streams เป็นลำดับของทูเพิลที่สร้างขึ้นและประมวลผลแบบเรียลไทม์ในสภาพแวดล้อมแบบกระจาย พวกเขาสร้างหน่วยนามธรรมหลักของคลัสเตอร์ Spark
พวยกา
ต้นอ่อนเป็นแหล่งกำเนิดของลำธารในทูเปิลสตอร์ม มีหน้าที่ติดต่อกับแหล่งข้อมูลจริง รับข้อมูลอย่างต่อเนื่อง แปลงข้อมูลเหล่านั้นให้เป็นกระแสข้อมูล tuples จริง และส่งไปยังสลักเกลียวเพื่อดำเนินการในที่สุด สามารถเชื่อถือได้หรือไม่น่าเชื่อถือ Spout ที่เชื่อถือได้จะเล่น tuple ซ้ำหาก Storm ไม่สามารถประมวลผล Spout ที่ไม่น่าเชื่อถือได้ ในทางกลับกัน จะลืม Tuple ทันทีหลังจากที่ปล่อยออกไป
สายฟ้า
สลักเกลียวมีหน้าที่ในการประมวลผลโทโพโลยีทั้งหมด พวกเขาสร้างหน่วยตรรกะการประมวลผลของแอปพลิเคชัน Storm คุณสามารถใช้โบลต์เพื่อดำเนินการที่จำเป็นหลายอย่าง เช่น การกรอง ฟังก์ชัน การรวม การรวม การเชื่อมต่อกับฐานข้อมูล และอื่นๆ อีกมากมาย
ใครใช้สตอร์ม?
แม้ว่าเครื่องมือที่ทรงพลังและใช้งานง่ายจำนวนหนึ่งจะมีอยู่ในตลาดของ Big Data แต่ Storm พบว่ามีสถานที่ที่ไม่เหมือนใครในรายการนั้น เนื่องจากความสามารถในการจัดการภาษาการเขียนโปรแกรมใดๆ ที่คุณสนใจ หลายองค์กรนำ Storm ไปใช้
มาดูผู้เล่นรายใหญ่สองสามรายที่ใช้ Apache Storm และทำอย่างไร!
ทวิตเตอร์

Twitter ใช้ Storm เพื่อขับเคลื่อนระบบที่หลากหลาย ตั้งแต่การปรับแต่งฟีดของคุณ การปรับรายได้ให้เหมาะสม ไปจนถึงการปรับปรุงผลการค้นหา และกระบวนการอื่นๆ เนื่องจาก Twitter พัฒนา Storm (ซึ่งต่อมาถูกซื้อโดย Apache และชื่อ Apache Storm) มันจึงรวมเข้ากับโครงสร้างพื้นฐานที่เหลือของ Twitter ได้อย่างราบรื่น – ระบบฐานข้อมูล (Cassandra, Memcached เป็นต้น) สภาพแวดล้อมการส่งข้อความ (Mesos) และระบบตรวจสอบ .
Spotify

Spotify ขึ้นชื่อเรื่องการสตรีมเพลงไปยังผู้ใช้งานมากกว่า 50 ล้านคนและสมาชิก 10 ล้านคน มีฟีเจอร์แบบเรียลไทม์มากมาย เช่น การแนะนำเพลง การตรวจสอบ การวิเคราะห์ การกำหนดเป้าหมายโฆษณา และการสร้างเพลย์ลิสต์ เพื่อให้บรรลุความสำเร็จนี้ Spotify ใช้ Apache Storm
Apache Storm ที่ซ้อนทับกับสภาพแวดล้อมการส่งข้อความที่ใช้ Kafka, Memcached และ netty-zmtp ทำให้ Spotify สามารถสร้างระบบกระจายที่ทนทานต่อข้อผิดพลาดที่มีเวลาแฝงต่ำได้อย่างง่ายดาย
เพื่อสรุป…
หากคุณต้องการสร้างอาชีพของคุณในฐานะนักวิเคราะห์ Big Data การสตรีมเป็นวิธีที่จะไป หากคุณสามารถเชี่ยวชาญศิลปะในการจัดการกับข้อมูลแบบเรียลไทม์ได้ คุณจะเป็นที่โปรดปรานอันดับหนึ่งสำหรับบริษัทที่จ้างตำแหน่งนักวิเคราะห์ ไม่มีเวลาไหนที่ดีไปกว่านี้แล้วในการดำดิ่งสู่การวิเคราะห์ข้อมูลแบบเรียลไทม์ เพราะนั่นคือความต้องการชั่วโมงอย่างแท้จริง!
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ

เรียนรู้ ปริญญาวิศวกรรมซอฟต์แวร์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว