كل ما تحتاج لمعرفته حول Apache Storm
نشرت: 2018-02-20يستمر النمو المتزايد باستمرار في إنتاج وتحليلات البيانات الضخمة في تقديم تحديات جديدة ، ويأخذها علماء البيانات والمبرمجون برشاقة في خطواتهم - من خلال التحسين المستمر للتطبيقات التي طوروها. إحدى هذه المشكلات كانت مشكلة البث المباشر في الوقت الفعلي. تحمل بيانات الوقت الفعلي قيمة عالية جدًا للشركات ، ولكن لها نافذة زمنية تفقد بعدها قيمتها - تاريخ انتهاء الصلاحية ، إذا صح التعبير. إذا لم تتحقق قيمة هذه البيانات في الوقت الفعلي داخل النافذة ، فلا يمكن استخراج أي معلومات قابلة للاستخدام منها. تأتي هذه البيانات في الوقت الفعلي بسرعة وباستمرار ، وبالتالي فإن مصطلح "التدفق".
يمكن أن تساعدك تحليلات هذه البيانات في الوقت الفعلي في البقاء على اطلاع دائم بما يحدث الآن ، مثل عدد الأشخاص الذين يقرؤون منشور المدونة أو عدد الأشخاص الذين يزورون صفحتك على Facebook. على الرغم من أنها قد تبدو وكأنها مجرد ميزة "لطيفة في امتلاكها" ، إلا أنها ضرورية من الناحية العملية. تخيل أنك جزء من وكالة إعلانية تقوم بإجراء تحليلات في الوقت الفعلي لحملاتك الإعلانية - والتي دفع العميل ثمنها بشكل كبير. يمكن أن تبقيك التحليلات في الوقت الفعلي على اطلاع دائم بكيفية أداء إعلانك في السوق ، وكيف يستجيب المستخدمون له ، وأشياء أخرى من هذا القبيل. إنها أداة أساسية تمامًا إذا كنت تفكر في الأمر بهذه الطريقة ، أليس كذلك؟
بالنظر إلى القيمة التي تحملها البيانات في الوقت الفعلي ، بدأت المؤسسات في ابتكار العديد من أدوات تحليل البيانات في الوقت الفعلي. في هذه المقالة ، سنتحدث عن أحد هؤلاء - Apache Storm. سننظر في ماهيته ، بنية تطبيق العاصفة النموذجي ، ومكوناته الأساسية (المعروفة أيضًا باسم التجريدات) ، وحالات استخدام الحياة الحقيقية.
دعنا نذهب!
جدول المحتويات
ما هو اباتشي ستورم؟

Apache Storm - تم إصداره بواسطة Twitter ، وهو إطار عمل موزع مفتوح المصدر يساعد في معالجة البيانات في الوقت الفعلي. يعمل Apache Storm مع البيانات في الوقت الفعلي تمامًا كما يعمل Hadoop مع المعالجة المجمعة للبيانات (المعالجة المجمعة هي عكس الوقت الفعلي. في هذا ، يتم تقسيم البيانات إلى مجموعات ، وتتم معالجة كل دفعة. لا يتم ذلك في الواقع -زمن.)
لا تمتلك Apache Storm أي إمكانيات لإدارة الحالة وتعتمد بشكل كبير على Apache ZooKeeper (خدمة مركزية لإدارة التكوينات في تطبيقات البيانات الضخمة) لإدارة حالة المجموعة - أشياء مثل إقرارات الرسائل وحالات المعالجة وغيرها من الرسائل. Apache Storm لها تطبيقاتها المصممة في شكل رسوم بيانية حلقية موجهة. تشتهر بمعالجة أكثر من مليون مجموعة في الثانية لكل عقدة - وهي قابلة للتطوير بدرجة كبيرة وتوفر ضمانات مهام المعالجة. تمت كتابة Storm بلغة Clojure وهي لغة البرمجة الوظيفية الأولى التي تشبه Lisp.

في قلب Apache Storm يوجد "تعريف التوفير" لتعريف وتقديم الرسم البياني المنطقي (المعروف أيضًا باسم الطبولوجيا). نظرًا لأنه يمكن تنفيذ Thrift بأي لغة من اختيارك ، يمكن أيضًا إنشاء الطبولوجيا بأي لغة. هذا يجعل Storm يدعم العديد من اللغات - مما يجعله أكثر ملاءمة للمطورين.
يعمل Storm على YARN ويتكامل تمامًا مع نظام Hadoop البيئي. إنه إطار عمل معالجة بيانات حقيقي في الوقت الحقيقي بدون دعم دفعة واحدة. يتطلب الأمر دفقًا كاملاً من البيانات كـ "حدث" كامل بدلاً من تقسيمه إلى سلسلة من الدفعات الصغيرة. ومن ثم ، فهي الأنسب للبيانات التي سيتم استيعابها ككيان واحد.
دعنا نلقي نظرة على البنية العامة لتطبيق Storm - سيمنحك المزيد من الأفكار حول كيفية عمل Storm!
أباتشي ستورم: العمارة العامة والمكونات الهامة
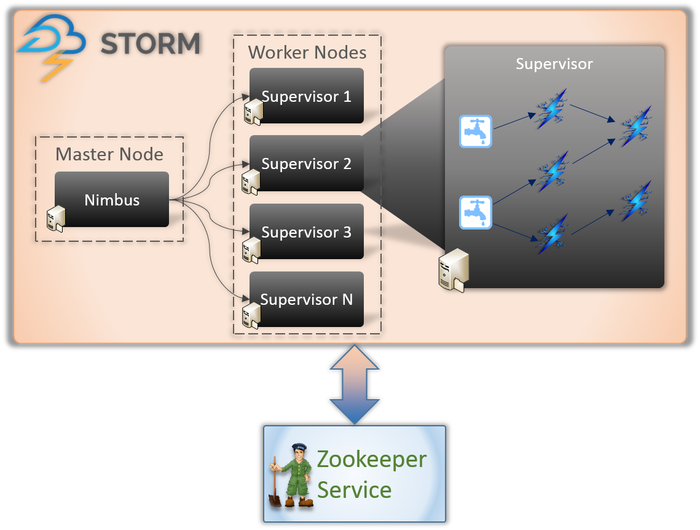
يوجد نوعان أساسيان من العقد المتضمنة في أي تطبيق Storm (كما هو موضح أعلاه).
العقدة الرئيسية (خدمة Nimbus)
إذا كنت على دراية بالأعمال الداخلية لـ Hadoop ، فيجب أن تعرف ما هو "Job Tracker". إنها خدمة تعمل على العقدة الرئيسية لـ Hadoop وهي مسؤولة عن توزيع المهام بين العقد. Nimbus هو نوع مشابه من الخدمة لـ Storm. يتم تشغيله على العقدة الرئيسية لمجموعة العاصفة وهو مسؤول عن توزيع المهام بين العقد العاملة.
Nimbus هي خدمة توفير تقدمها Apache تتيح لك إرسال التعليمات البرمجية بلغة البرمجة التي تختارها. يساعدك هذا في كتابة طلبك دون الحاجة إلى تعلم لغة جديدة خاصة بـ Storm.
كما تحدثنا سابقًا ، تفتقر Storm إلى أي قدرات إدارية للدولة. يجب أن تعتمد خدمة Nimbus على ZooKeeper لمراقبة الرسائل التي ترسلها العقد العاملة أثناء معالجة المهام. تقوم جميع العقد العاملة بتحديث حالة المهام الخاصة بهم في خدمة ZooKeeper لكي يتمكن Nimbus من رؤيتها ومراقبتها.

عقدة العامل (خدمة المشرف)
هذه هي العقد المسؤولة عن أداء المهام. تقوم العقد العاملة في Storm بتشغيل خدمة تسمى المشرف. يكون المشرف مسؤولاً عن استلام العمل المخصص للآلة بواسطة خدمة Nimbus. كما يوحي الاسم ، يشرف المشرف على عمليات العمال ومساعدتهم على إكمال المهام المعينة. كل من هذه العمليات العاملة تنفذ مجموعة فرعية من الهيكل الكامل.
يحتوي تطبيق Storm بشكل أساسي على أربعة مكونات / أفكار تكون مسؤولة عن أداء المهام المطروحة. وهذه هي:
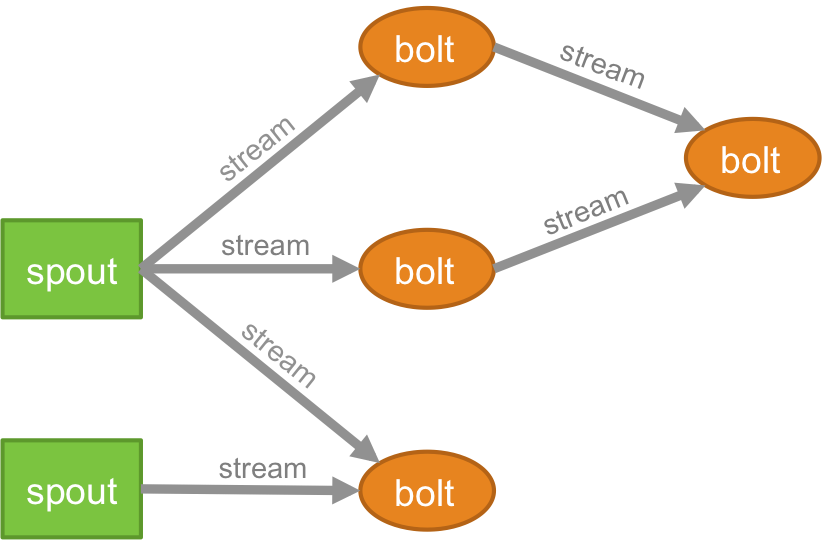
طوبولوجيا
يتم تجميع منطق أي تطبيق في الوقت الفعلي في شكل طوبولوجيا - والتي هي أساسًا شبكة من البراغي والصمامات. لفهم أفضل ، يمكنك مقارنتها بوظائف MapReduce (اقرأ مقالتنا على MapReduce إذا كنت غير مدرك لما هو!). يتمثل أحد الاختلافات الرئيسية في أن مهمة MapReduce تنتهي عند اكتمال تنفيذها ، بينما تعمل طوبولوجيا العاصفة إلى الأبد (ما لم تقتلها بنفسك صراحة). تتكون الشبكة من العقد التي تشكل منطق المعالجة ، والروابط (المعروفة أيضًا باسم الدفق) التي توضح مرور البيانات وتنفيذ العمليات.
مجرى
أنت بحاجة إلى فهم ما هي مجموعات tuple قبل فهم ما هي التدفقات. Tuples هي هياكل البيانات الرئيسية في مجموعة العاصفة. تسمى هذه قوائم من القيم حيث يمكن أن تكون القيم أي شيء من الأعداد الصحيحة ، والأرقام الطويلة ، والسراويل القصيرة ، والبايت ، والمضاعفات ، والسلاسل ، والعوامات المنطقية ، إلى مصفوفات البايت. الآن ،. Streams هي سلسلة من المجموعات التي يتم إنشاؤها ومعالجتها في الوقت الفعلي في بيئة موزعة. إنها تشكل وحدة التجريد الأساسية لمجموعة Spark.
صنبور
البرعم هو مصدر التدفقات في مجموعة العاصفة. وهي مسؤولة عن الاتصال بمصدر البيانات الفعلي ، وتلقي البيانات بشكل مستمر ، وتحويل هذه البيانات إلى التدفق الفعلي للبطاقات ، وأخيراً إرسالها إلى البراغي لتتم معالجتها. يمكن أن تكون موثوقة أو غير موثوقة. سوف يعيد Spout الموثوق به تشغيل tuple إذا فشلت معالجته بواسطة Storm ، ومن ناحية أخرى ، سوف ينسى Spout غير الموثوق به المجموعة بعد إصدارها بوقت قصير.
بولت
البراغي مسؤولة عن تنفيذ جميع عمليات المعالجة للطوبولوجيا. هم يشكلون وحدة منطق المعالجة لتطبيق Storm. يمكن للمرء استخدام الترباس لأداء العديد من العمليات الأساسية مثل التصفية والوظائف والصلات والتجميعات والاتصال بقواعد البيانات وغير ذلك الكثير.
من يستخدم العاصفة؟
على الرغم من وجود عدد من الأدوات القوية وسهلة الاستخدام في سوق البيانات الضخمة ، إلا أن Storm تجد مكانًا فريدًا في تلك القائمة نظرًا لقدرتها على التعامل مع أي لغة برمجة تستخدمها. تستخدم العديد من المنظمات Storm.
دعونا نلقي نظرة على اثنين من اللاعبين الكبار الذين يستخدمون Apache Storm وكيف!
تويتر

يستخدم Twitter Storm لتشغيل مجموعة متنوعة من أنظمته - بدءًا من تخصيص خلاصتك ، وتحسين الإيرادات ، إلى تحسين نتائج البحث والعمليات الأخرى المماثلة. نظرًا لأن Twitter طور Storm (الذي تم شراؤه لاحقًا بواسطة Apache واسمه Apache Storm) ، فإنه يتكامل بسلاسة مع بقية البنية التحتية لتويتر - أنظمة قواعد البيانات (Cassandra و Memcached وما إلى ذلك) وبيئة المراسلة (Mesos) وأنظمة المراقبة .
سبوتيفي

تشتهر Spotify ببث الموسيقى إلى أكثر من 50 مليون مستخدم نشط و 10 ملايين مشترك. يوفر مجموعة واسعة من الميزات في الوقت الفعلي مثل التوصية بالموسيقى والمراقبة والتحليلات واستهداف الإعلانات وإنشاء قوائم التشغيل. لتحقيق هذا العمل الفذ ، يستخدم Spotify Apache Storm.
مكدسًا ببيئة المراسلة المستندة إلى Kafka و Memcached و netty-zmtp ، يمكّن Apache Storm Spotify من إنشاء أنظمة موزعة منخفضة زمن الوصول ومتسامحة مع الأخطاء بسهولة.
للختام…
إذا كنت ترغب في تأسيس حياتك المهنية كمحلل بيانات ضخمة ، فإن التدفق هو الطريق الأفضل. إذا كنت قادرًا على إتقان فن التعامل مع البيانات في الوقت الفعلي ، فستكون المفضل الأول للشركات التي توظف لوظيفة محلل. لا يمكن أن يكون هناك وقت أفضل للغوص في تحليلات البيانات في الوقت الفعلي لأن هذه هي حاجة الساعة بالمعنى الحقيقي للكلمة!
إذا كنت مهتمًا بمعرفة المزيد عن البيانات الضخمة ، فراجع دبلومة PG في تخصص تطوير البرمجيات في برنامج البيانات الضخمة المصمم للمهنيين العاملين ويوفر أكثر من 7 دراسات حالة ومشاريع ، ويغطي 14 لغة وأدوات برمجة ، وتدريب عملي عملي ورش العمل ، أكثر من 400 ساعة من التعلم الصارم والمساعدة في التوظيف مع الشركات الكبرى.

تعلم شهادات هندسة البرمجيات عبر الإنترنت من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.