Wszystko, co musisz wiedzieć o Apache Storm
Opublikowany: 2018-02-20Stale rosnący wzrost produkcji i analityki Big Data wciąż stawia nowe wyzwania, a data science i programiści z wdziękiem podchodzą do tego ze spokojem – stale ulepszając tworzone przez siebie aplikacje. Jednym z takich problemów był streaming w czasie rzeczywistym. Dane w czasie rzeczywistym mają niezwykle dużą wartość dla firm, ale mają okno czasowe, po którym tracą swoją wartość – datę wygaśnięcia, jeśli wolisz. Jeśli wartość tych danych czasu rzeczywistego nie jest realizowana w oknie, nie można z niego wydobyć użytecznych informacji. Te dane w czasie rzeczywistym przychodzą szybko i nieprzerwanie, stąd termin „streaming”.
Analiza tych danych w czasie rzeczywistym może pomóc Ci być na bieżąco z bieżącymi wydarzeniami, takimi jak liczba osób czytających Twój post na blogu lub liczba osób odwiedzających Twoją stronę na Facebooku. Chociaż może to brzmieć jak funkcja „fajna do posiadania”, w praktyce jest to niezbędne. Wyobraź sobie, że jesteś częścią agencji reklamowej, która przeprowadza analizy w czasie rzeczywistym w swoich kampaniach reklamowych – za które klient dużo zapłacił. Analizy w czasie rzeczywistym mogą informować Cię o tym, jak Twoja reklama radzi sobie na rynku, jak reagują na nią użytkownicy i inne rzeczy tego rodzaju. Całkiem niezbędne narzędzie, jeśli myślisz o tym w ten sposób, prawda?
Patrząc na wartość, jaką mają dane w czasie rzeczywistym, organizacje zaczęły wymyślać różne narzędzia do analizy danych w czasie rzeczywistym. W tym artykule będziemy mówić o jednym z nich – Apache Storm. Przyjrzymy się, co to jest, architekturze typowej aplikacji burzowej, jej podstawowym komponentom (znanym również jako abstrakcje) i rzeczywistym przypadkom użycia.
Chodźmy!
Spis treści
Co to jest Apache Storm?

Apache Storm – wydany przez Twittera, to rozproszona platforma open source, która pomaga w przetwarzaniu danych w czasie rzeczywistym. Apache Storm działa dla danych w czasie rzeczywistym, tak jak Hadoop działa w przypadku przetwarzania wsadowego danych (przetwarzanie wsadowe jest przeciwieństwem czasu rzeczywistego. W tym przypadku dane są dzielone na partie, a każda partia jest przetwarzana. Nie odbywa się to w rzeczywistości -czas.)
Apache Storm nie ma żadnych możliwości zarządzania stanem i polega w dużej mierze na Apache ZooKeeper (scentralizowanej usłudze do zarządzania konfiguracjami w aplikacjach Big Data) do zarządzania stanem klastra — takimi rzeczami, jak potwierdzenia wiadomości, statusy przetwarzania i inne tego typu komunikaty. Apache Storm ma swoje aplikacje zaprojektowane w postaci skierowanych grafów acyklicznych. Jest znany z przetwarzania ponad miliona krotek na sekundę na węzeł – co jest wysoce skalowalne i zapewnia gwarancje przetwarzania. Storm jest napisany w Clojure, który jest językiem programowania podobnym do Lisp.

Sercem Apache Storm jest „definicja oszczędności” służąca do definiowania i przesyłania wykresów logicznych (znanych również jako topologie). Ponieważ Thrift można zaimplementować w dowolnym wybranym języku, topologie można również tworzyć w dowolnym języku. To sprawia, że Storm obsługuje wiele języków, co czyni go jeszcze bardziej przyjaznym dla programistów.
Storm działa na YARN i doskonale integruje się z ekosystemem Hadoop. Jest to platforma przetwarzania danych w czasie rzeczywistym z zerową obsługą partii. Zajmuje cały strumień danych jako całe „zdarzenie”, zamiast dzielić go na serie małych partii. Dlatego najlepiej nadaje się do danych, które mają być pozyskiwane jako jeden podmiot.
Przyjrzyjmy się ogólnej architekturze aplikacji Storm — dzięki niej uzyskasz więcej informacji na temat działania Storm!
Apache Storm: ogólna architektura i ważne komponenty
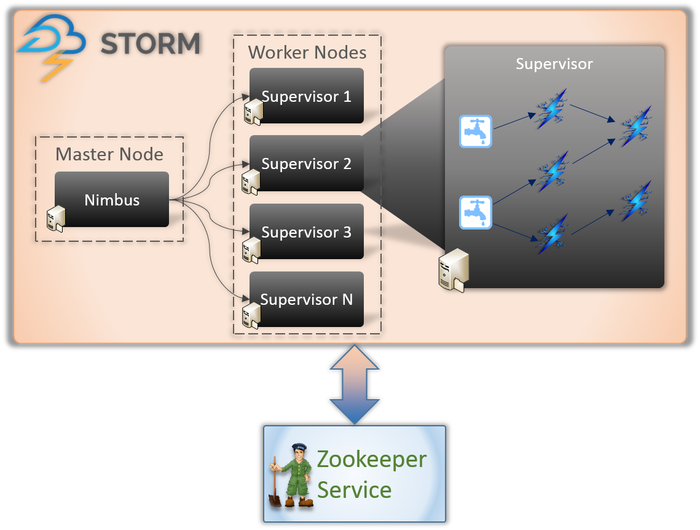
W każdej aplikacji Storm występują zasadniczo dwa typy węzłów (jak pokazano powyżej).
Węzeł główny (usługa Nimbus)
Jeśli jesteś świadomy wewnętrznego działania Hadoopa, musisz wiedzieć, czym jest „Job Tracker”. Jest to demon, który działa na węźle głównym Hadoop i jest odpowiedzialny za dystrybucję zadań między węzłami. Nimbus to podobny rodzaj usługi dla Storm. Działa na węźle głównym klastra Storm i odpowiada za dystrybucję zadań między węzłami roboczymi.
Nimbus to usługa Thrift świadczona przez Apache, która umożliwia przesłanie kodu w wybranym języku programowania. Pomaga to napisać aplikację bez konieczności uczenia się nowego języka specjalnie dla Storm.
Jak mówiliśmy wcześniej, Storm nie ma żadnych możliwości zarządzania stanem. Usługa Nimbus musi polegać na ZooKeeper, aby monitorować wiadomości wysyłane przez węzły robocze podczas przetwarzania zadań. Wszystkie węzły robocze aktualizują swój status zadań w usłudze ZooKeeper, aby Nimbus mógł je zobaczyć i monitorować.
Węzeł roboczy (usługa nadzorcy)
Są to węzły odpowiedzialne za wykonywanie zadań. Węzły robocze w programie Storm uruchamiają usługę o nazwie Supervisor. Nadzorca jest odpowiedzialny za odebranie pracy przypisanej do maszyny przez serwis Nimbus. Jak sama nazwa wskazuje, Supervisor nadzoruje procesy pracownicze i pomaga im w realizacji przydzielonych zadań. Każdy z tych procesów roboczych wykonuje podzbiór pełnej topologii.

Aplikacja Storm zawiera zasadniczo cztery komponenty/abstrakcje, które są odpowiedzialne za wykonywanie zadań. To są:
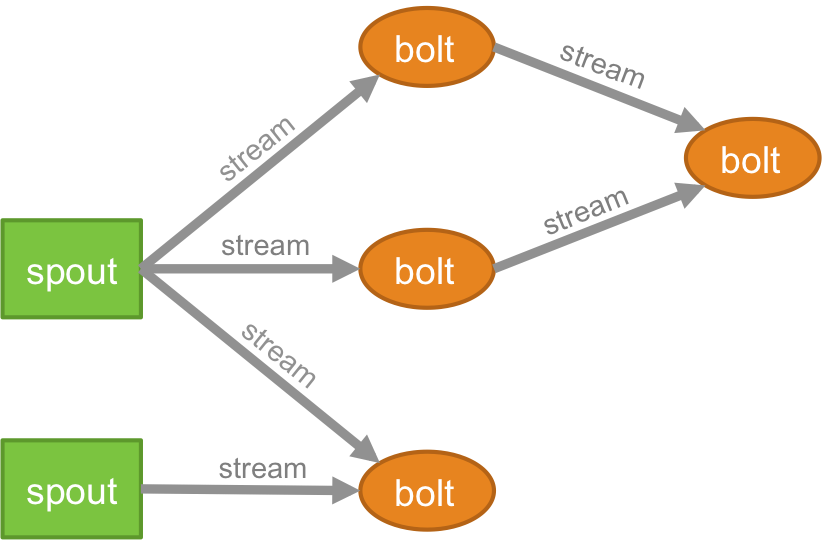
Topologia
Logika dla każdej aplikacji działającej w czasie rzeczywistym jest spakowana w formie topologii – która jest zasadniczo siecią śrub i dziobków. Aby lepiej zrozumieć, możesz porównać to z zadaniami MapReduce (przeczytaj nasz artykuł na temat MapReduce, jeśli nie wiesz, co to jest!). Jedną z kluczowych różnic jest to, że zadanie MapReduce kończy się po zakończeniu jego wykonywania, podczas gdy topologia Storm działa w nieskończoność (chyba że sam ją zabijesz). Sieć składa się z węzłów tworzących logikę przetwarzania oraz łączy (znanych również jako strumień), które demonstrują przekazywanie danych i wykonywanie procesów.
Strumień
Musisz zrozumieć, czym są krotki, zanim zrozumiesz, czym są strumienie. Krotki to główne struktury danych w klastrze Storm. Są to nazwane listy wartości, gdzie wartości mogą być dowolne, od liczb całkowitych, długich, krótkich, bajtów, podwójnych, łańcuchów, liczb zmiennoprzecinkowych do tablic bajtowych. Teraz .streams to sekwencja krotek, które są tworzone i przetwarzane w czasie rzeczywistym w środowisku rozproszonym. Tworzą podstawową jednostkę abstrakcji klastra Spark.
Rynna
Kiełek jest źródłem strumieni w krotce Storm. Odpowiada za kontakt z rzeczywistym źródłem danych, ciągłe odbieranie danych, przekształcanie tych danych w rzeczywisty strumień krotek i wreszcie wysyłanie ich do śrub w celu przetworzenia. Może być albo niezawodny, albo zawodny. Niezawodny Spout odtworzy krotkę, jeśli nie zostanie przetworzony przez Storm, z drugiej strony niewiarygodny Spout zapomni o krotce wkrótce po jej wyemitowaniu.
Śruba
Bolty są odpowiedzialne za wykonanie całej obróbki topologii. Tworzą jednostkę logiczną przetwarzania aplikacji Storm. Można wykorzystać śrubę do wykonywania wielu istotnych operacji, takich jak filtrowanie, funkcje, łączenia, agregacje, łączenie z bazami danych i wiele innych.
Kto używa burzy?
Chociaż na rynku Big Data pojawiło się wiele potężnych i łatwych w użyciu narzędzi, Storm znajduje na tej liście wyjątkowe miejsce ze względu na jego zdolność do obsługi dowolnego języka programowania, który na niego rzucisz. Wiele organizacji korzysta ze Storm.
Przyjrzyjmy się kilku dużym graczom, którzy używają Apache Storm i jak!
Świergot

Twitter wykorzystuje Storm do obsługi różnych swoich systemów – od personalizacji Twojego kanału, optymalizacji przychodów, po ulepszanie wyników wyszukiwania i innych podobnych procesów. Ponieważ Twitter opracował Storm (który później został kupiony przez Apache i nazwany Apache Storm), bezproblemowo integruje się z resztą infrastruktury Twittera – systemami baz danych (Cassandra, Memcached itp.), środowiskiem przesyłania wiadomości (Mesos) i systemami monitorowania .
Spotify

Spotify jest znane z przesyłania strumieniowego muzyki do ponad 50 milionów aktywnych użytkowników i 10 milionów subskrybentów. Zapewnia szeroki zakres funkcji w czasie rzeczywistym, takich jak polecanie muzyki, monitorowanie, analityka, kierowanie reklam i tworzenie list odtwarzania. Aby osiągnąć ten wyczyn, Spotify wykorzystuje Apache Storm.
W połączeniu ze środowiskiem komunikacyjnym opartym na Kafka, Memcached i netty-zmtp, Apache Storm umożliwia Spotify łatwe budowanie odpornych na błędy systemów rozproszonych o niskim opóźnieniu.
Owinąć…
Jeśli chcesz rozpocząć karierę jako analityk Big Data, najlepszym rozwiązaniem jest przesyłanie strumieniowe. Jeśli potrafisz opanować sztukę radzenia sobie z danymi w czasie rzeczywistym, będziesz preferowanym numerem jeden wśród firm zatrudniających na stanowisko analityka. Nie może być lepszego czasu, aby zagłębić się w analizę danych w czasie rzeczywistym, ponieważ jest to potrzeba godziny w najprawdziwszym tego słowa znaczeniu!
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.

Ucz się stopni inżynierii oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.