
圍棋和對通用人工智能的挑戰
已發表: 2018-02-15本文旨在探討“圍棋”遊戲與人工智能之間的聯繫。 目標是回答問題——是什麼讓圍棋遊戲如此特別? 為什麼計算機很難掌握圍棋遊戲? 為什麼計算機程序能夠在 1997 年擊敗國際象棋大師? 為什麼破解圍棋花了將近二十年的時間?
“先生們不應該把時間浪費在瑣碎的遊戲上——他們應該學習圍棋”
——孔子
事實上,人工智能專家認為計算機只能在 2027 年之前擊敗世界圍棋冠軍。多虧了谷歌旗下的人工智能公司 DeepMind,這項艱鉅的任務在十年前就完成了。 本文將討論 DeepMind 用於擊敗世界圍棋冠軍的技術。 最後,這篇文章討論瞭如何使用這項技術來解決一些複雜的現實問題。
目錄
走——這是什麼?
圍棋是一款具有 3000 年曆史的中國戰略棋盤遊戲,歷久彌新。 圍棋由全球數以千萬計的人玩,是一款規則簡單、策略直觀的兩人棋盤遊戲。 玩這個遊戲時使用了不同的棋盤尺寸; 專業人士使用 19×19 板。

遊戲以空棋盤開始。 然後每個玩家輪流將黑色和白色的棋子(黑色先行)放在棋盤上的線交叉處(不像國際象棋,您將棋子放在方格中)。 玩家可以從四面八方包圍對手的石頭。 對於每塊捕獲的石頭,玩家都會獲得一些積分。 遊戲的目標是佔領棋盤上的最大領土,同時奪取對手的棋子。
圍棋是關於創造的,不像國際象棋是關於毀滅的。 圍棋需要自由、創造力、直覺、平衡、策略和智力深度來掌握遊戲。 下圍棋涉及大腦的兩側。 事實上,圍棋選手的大腦掃描顯示,圍棋通過改善兩個大腦半球之間的連接來幫助大腦發育。
傻瓜神經網絡:綜合指南
圍棋和人工智能 (AI) 的挑戰
計算機能夠在1952 年掌握井字遊戲。 深藍在1997 年擊敗了國際象棋大師加里卡斯帕羅夫。 該計算機程序在2001 年的Jeopardy (美國流行遊戲)中戰勝了世界冠軍。 DeepMind 的 AlphaGo 在2016 年擊敗了世界圍棋冠軍。 為什麼認為計算機程序掌握圍棋遊戲具有挑戰性?
國際象棋在 8×8 的棋盤上進行,而圍棋使用 19×19 的棋盤。 在國際象棋遊戲開始時,一名玩家將有 20 個可能的移動。 在圍棋開局中,玩家可以有 361 種可能的走法。可能的圍棋棋盤位置數等於 10 的 170 次方; 超過了我們宇宙中的原子數量! 棋盤位置的潛在數量使得 Go googol 次(10 的 100 次方)比國際象棋更複雜。
在國際象棋中,每走一步,玩家都面臨著 35 步的選擇。 平均而言,圍棋玩家每一步將有 250 次可能的走法。 在國際象棋中,在任何給定的位置上,計算機都相對容易進行蠻力搜索並選擇最大可能獲勝的最佳棋步。 在圍棋的情況下,暴力搜索是不可能的,因為每一步允許的合法移動的潛在數量是巨大的。
對於計算機掌握國際象棋,隨著遊戲的進行變得更容易,因為棋子已從棋盤上移開。 在圍棋中,隨著遊戲的進行,棋子被添加到棋盤上,計算機程序變得更加困難。 通常,圍棋遊戲的持續時間是國際象棋遊戲的 3 倍。
由於所有這些原因,在機器學習新技術大爆發之後,頂級計算機圍棋程序只能在 2016 年趕上圍棋世界冠軍。 在 DeepMind 工作的科學家們能夠想出一個名為AlphaGo的計算機程序,它擊敗了世界冠軍李世石。 完成任務並不容易。 DeepMind 的研究人員在創建 AlphaGo 的過程中提出了許多新穎的創新。
“圍棋規則如此優雅、有機且邏輯嚴密,以至於如果宇宙其他地方存在智慧生命形式,他們幾乎肯定會下圍棋。”
——愛德華·拉斯卡
神經網絡:現實世界中的應用
AlphaGo 的工作原理
AlphaGo 是一種通用算法,這意味著它也可以用於解決其他任務。 例如,IBM 的 Deep Blue 專為下棋而設計。 國際象棋規則以及數百年來積累的知識被編程到程序的大腦中。 Deep Blue 甚至不能用於玩 Tic-Tac-Toe 之類的瑣碎遊戲。 它只能做一件它非常擅長的特定事情,即下棋。 除了圍棋,AlphaGo 還可以學習玩其他遊戲。 這些通用算法構成了一個新的研究領域,稱為通用人工智能。
AlphaGo 使用最先進的方法——深度神經網絡 (DNN)、強化學習 (RL)、蒙特卡洛樹搜索 (MCTS)、深度 Q 網絡 (DQN)(DeepMind 引入和推廣的一種新技術,它結合了神經網絡具有強化學習的網絡),僅舉幾例。 然後將所有這些方法創新地結合起來,在圍棋遊戲中達到超人的水平。
讓我們先看看這個拼圖的每一部分,然後再了解這些部分是如何联系在一起來完成手頭的任務的。
深度神經網絡
DNN 是一種執行機器學習的技術,大致受到人腦功能的啟發。 DNN 的架構由神經元層組成。 DNN 可以識別數據中的模式,而無需對其進行顯式編程。
它將輸入映射到輸出,無需任何人專門對其進行編程。 作為一個例子,讓我們假設我們已經為網絡提供了很多貓狗照片。 同時,我們還通過告訴系統(以標籤的形式)特定圖像是貓還是狗來訓練系統(這稱為監督學習)。 DNN 將學習識別照片中的模式,以成功區分貓和狗。 訓練的主要目標是當 DNN 看到一張狗或貓的新圖片時,它應該能夠正確地對其進行分類,即預測它是貓還是狗。
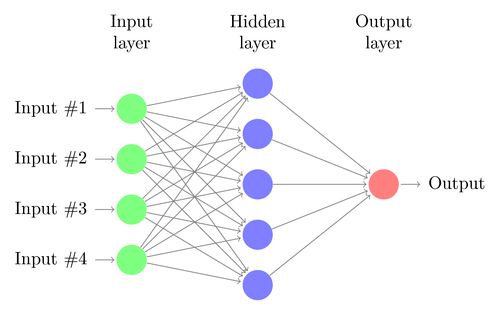
讓我們了解一個簡單 DNN 的架構。 輸入層中神經元的數量對應於輸入的大小。 讓我們假設我們的貓和狗照片是 28×28 的圖像。 每行和每列將由 28 個像素組成,這使得每張圖片總共有 784 個像素。 在這種情況下,輸入層將包含 784 個神經元,每個像素一個。 輸出層中神經元的數量將取決於輸出需要分類的類的數量。 在這種情況下,輸出層將由兩個神經元組成——一個對應於“cat”,另一個對應於“dog”。
密切關注下一件大事:機器學習
在輸入層和輸出層之間會有許多神經元層(這是在“深度神經網絡”中使用“深度”一詞的由來)。 這些被稱為“隱藏層”。 隱藏層的數量和每層的神經元數量是不固定的。 事實上,改變這些值正是導致性能優化的原因。 這些值稱為超參數,需要根據手頭的問題進行調整。 圍繞神經網絡的實驗主要涉及找出超參數的最佳數量。
DNN 的訓練階段將包括前向傳播和後向傳播。 首先,神經元之間的所有連接都用隨機權重初始化。 在前向傳遞過程中,網絡被饋入單個圖像。 輸入(來自圖像的像素數據)與網絡的參數(權重、偏差和激活函數)相結合,並通過隱藏層前饋,一直到輸出,它返回一張照片屬於每個人的概率的類。
然後,將該概率與實際的類標籤進行比較,併計算出一個“錯誤”。 在這一點上,執行反向傳播——這個錯誤信息通過一種稱為“反向傳播”的技術通過網絡傳回。 在訓練的初始階段,這個誤差會很高,一個好的訓練機制會逐漸減少這個誤差。
以這種方式對 DNN 進行前向和後向訓練,直到權重停止變化(這稱為收斂)。 然後,DNN 將能夠以高精度預測和分類圖像,即圖片中是否有貓或狗。

研究為我們提供了許多不同的深度神經網絡架構。 對於計算機視覺問題(即涉及圖像的問題),卷積神經網絡(CNN)傳統上已經給出了很好的結果。 對於涉及序列的問題——語音識別或語言翻譯——循環神經網絡 (RNN) 提供了出色的結果。
自然語言理解初學者指南
在 AlphaGo 的案例中,過程如下:首先,卷積神經網絡 (CNN) 在數百萬張棋盤位置圖像上進行訓練。 接下來,在網絡的訓練階段,網絡被告知人類專家在每種情況下所採取的後續行動。 以與前面提到的相同方式,將實際值與輸出進行比較,並找到某種“錯誤”指標。
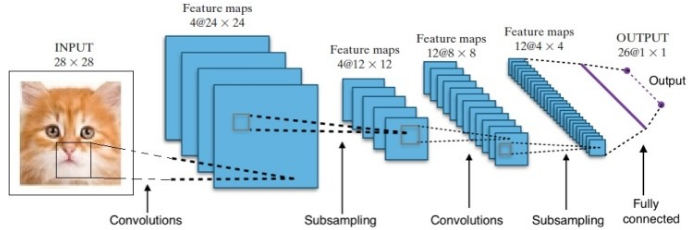
在訓練結束時,DNN 將輸出下一步動作以及專家玩家可能玩的概率。 這種網絡只能想出一個由人類專家玩家玩的步驟。 DeepMind 能夠達到 60% 的準確率來預測人類的動作。 然而,要擊敗圍棋專家,這還不夠。 DNN 的輸出由深度強化網絡進一步處理,深度強化網絡是 DeepMind 構想的一種方法,它結合了深度神經網絡和強化學習。

深度強化學習
強化學習(RL)並不是一個新概念。 諾貝爾獎獲得者 Ivan Pavlov 對狗進行了經典條件反射實驗,並於 1902 年發現了強化學習的原理。強化學習也是人類學習新技能的方法之一。 有沒有想過表演中的海豚是如何被訓練從水中跳到如此高的高度的? 它在 RL 的幫助下。 首先,將用於準備海豚的繩索浸入水池中。 每當海豚從頂部越過電纜時,它就會得到食物獎勵。 當它沒有越過繩索時,獎勵就會被撤回。 海豚會慢慢地知道,只要它從上面通過繩索,它就會得到報酬。 逐漸增加繩索的高度來訓練海豚。 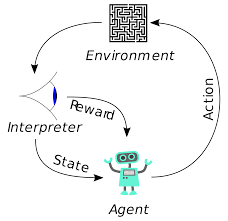
自然語言生成:你需要知道的最重要的事情
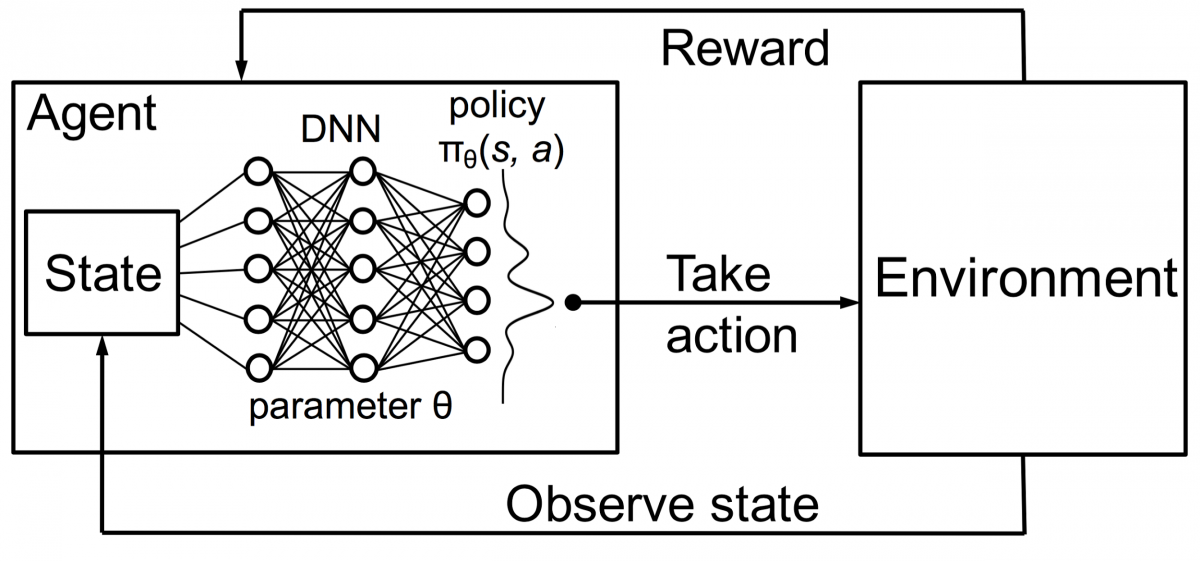
強化學習中的代理也使用相同的原理進行訓練。 代理將採取行動並與環境交互。 代理採取的行動會導致環境發生變化。 此外,代理收到有關環境的反饋。 代理人是否獲得獎勵,取決於其行動和手頭的目標。 重要的一點是,手頭的這個目標沒有為代理明確說明。 如果有足夠的時間,代理將學習如何最大化未來的獎勵。
將其與 DNN 相結合,DeepMind 發明了深度強化學習 (DRL) 或深度 Q 網絡 (DQN),其中 Q 代表獲得的最大未來獎勵。 DQN 最早應用於Atari遊戲。 DQN 學會瞭如何開箱即玩不同類型的 Atari 遊戲。 突破是不需要顯式編程來表示不同類型的 Atari 遊戲。 一個程序足夠聰明,可以了解遊戲的所有不同環境,並通過自我對戰,能夠掌握其中的許多環境。
2014 年,DQN 在 49 款遊戲中的 43 款中優於之前的機器學習方法(現在已經在 70 多款遊戲上進行了測試)。 事實上,在超過一半的比賽中,它的表現達到了職業人類玩家水平的 75% 以上。 在某些遊戲中,DQN 甚至提出了令人驚訝的高瞻遠矚的策略,使其能夠達到最高得分——例如,在Breakout中,它學會了先在磚牆的一端挖一條隧道,這樣球就會反彈繞在後面並從後面敲出磚塊。
政策和價值網絡
AlphaGo 內部有兩種主要的網絡類型:
AlphaGo 的 DQN 的目標之一是超越人類專家的遊戲並模仿新的創新動作,通過與自己對戰數百萬次,從而逐步提高權重。 這個 DQN 對常見 DNN 的勝率是 80%。 DeepMind 決定將這兩個神經網絡(DNN 和 DQN)結合起來形成第一種網絡——“策略網絡”。 簡而言之,政策網絡的工作是減少尋找下一步行動的廣度,並提出一些值得進一步探索的好行動。
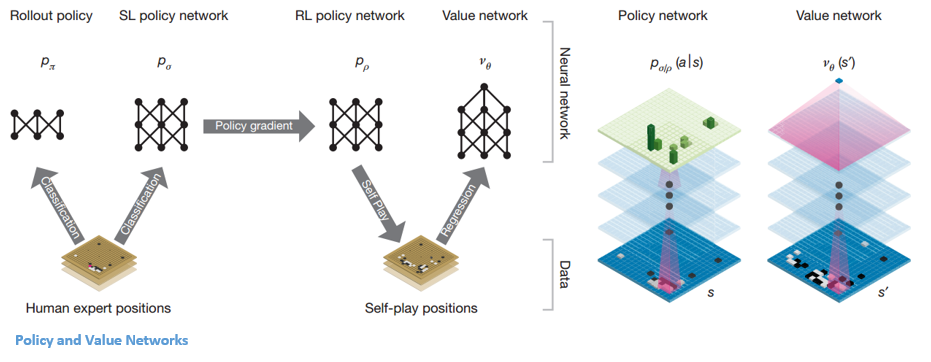 一旦策略網絡被凍結,它就會與自己對抗數百萬次。 這些遊戲生成一個新的圍棋數據集,包括各種棋盤位置和遊戲結果。 該數據集用於創建評估函數。 第二種功能——“價值網絡”用於預測遊戲的結果。 它學會將各種棋盤位置作為輸入,並預測遊戲的結果和衡量標準。
一旦策略網絡被凍結,它就會與自己對抗數百萬次。 這些遊戲生成一個新的圍棋數據集,包括各種棋盤位置和遊戲結果。 該數據集用於創建評估函數。 第二種功能——“價值網絡”用於預測遊戲的結果。 它學會將各種棋盤位置作為輸入,並預測遊戲的結果和衡量標準。
結合政策和價值網絡
經過所有這些訓練,DeepMind 最終得到了兩個神經網絡——策略網絡和價值網絡。 策略網絡將棋盤位置作為輸入,並將概率分佈作為該位置中每個動作的可能性輸出。 價值網絡再次將棋盤的位置作為輸入,輸出一個介於 0 和 1 之間的單個實數。如果網絡的輸出為零,則表示白方完全獲勝,而 1 表示黑方玩家完全獲勝石頭。
政策網絡評估當前位置,價值網絡評估未來走勢。 DeepMind 將任務劃分到這兩個網絡中是 AlphaGo 成功的主要原因之一。
將策略和價值網絡與蒙特卡洛樹搜索 (MCTS) 和推出相結合
僅靠神經網絡是不夠的。 為了贏得圍棋比賽,需要更多的策略。 該計劃是在 MCTS 的幫助下實現的。 蒙特卡洛樹搜索還有助於以創新的方式將兩個神經網絡縫合在一起。 神經網絡有助於有效搜索下一個最佳移動。
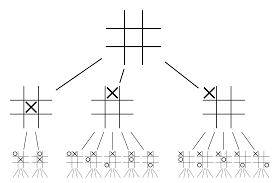
讓我們嘗試構建一個示例,它可以幫助您更好地可視化所有這些。 想像一下游戲處於一個新的位置,一個以前沒有遇到過的位置。 在這種情況下,需要一個政策網絡來評估當前情況和未來可能的路徑; 以及價值網絡的路徑的可取性和每一步的價值,由蒙特卡洛推出支持。
政策網絡發現所有可能的“好”動作,價值網絡評估它們的每一個結果。 在 Monte Carlo 部署中,從策略網絡識別的位置開始玩幾千場隨機遊戲。 進行了實驗以確定價值網絡相對於蒙特卡洛推出的相對重要性。 作為該實驗的結果,DeepMind 將 80% 的權重分配給了價值網絡,並將 20% 的權重分配給了 Monte Carlo 推出評估函數。
策略網絡將搜索的寬度從 200 多個可能的移動減少到 4 或 5 個最佳移動。 策略網絡從需要考慮的這 4 或 5 個步驟擴展樹。 價值網絡通過立即從該位置返回游戲結果來幫助減少樹搜索的深度。 最後選擇Q值最高的走法,即收益最大的一步。
“這個遊戲主要是通過直覺和感覺來玩的,由於它的美麗、微妙和智慧的深度,它在幾個世紀以來一直吸引著人類的想像力。”
——德米斯·哈薩比斯
AlphaGo 在現實問題中的應用
DeepMind 的願景,在他們的網站上,非常有說服力——“解決智能問題。 利用這些知識讓世界變得更美好”。 該算法的最終目標是使其具有通用性,以便用於解決複雜的現實問題。 DeepMind 的 AlphaGo 是尋求 AGI 的重要一步。 DeepMind 已經成功地利用其技術解決了現實世界的問題——讓我們看一些例子:
減少能源消耗
DeepMind 的 AI 成功用於將 Google 的數據中心冷卻成本降低 40%。 在任何大規模的能源消耗環境中,這種改進都是向前邁出的驚人一步。 數據中心的主要能耗來源之一是冷卻。 需要消除運行服務器產生的大量熱量以保持其運行。 這是通過泵、冷卻器和冷卻塔等大型工業設備實現的。 由於數據中心的環境非常動態,因此以最佳能源效率運行具有挑戰性。 DeepMind 的 AI 被用來解決這個問題。
首先,他們繼續使用由數據中心內數千個傳感器收集的歷史數據。 使用這些數據,他們訓練了一組 DNN 的平均未來電力使用效率 (PUE)。 由於這是一種通用算法,因此計劃將其應用於數據中心環境中的其他挑戰。
該技術的可能應用包括從相同的輸入單位獲得更多的能源、減少半導體製造能源和用水等。DeepMind 在其博客文章中宣布,這些知識將在未來的出版物中共享,以便其他數據中心、工業運營商和最終的環境可以從這一重要步驟中受益匪淺。
頭頸癌的放射治療計劃
DeepMind 與倫敦大學學院醫院 NHS 基金會信託的放射治療部門合作,後者是癌症治療的世界領導者。
大數據和機器學習如何联合對抗癌症
每 75 名男性中就有 1 名和 150 名女性中有 1 名在其一生中被診斷出患有口腔癌。 由於頭部和頸部區域的結構和器官的敏感性,放射科醫生在治療它們時需要格外小心。
在進行放射治療之前,需要準備一張詳細的地圖,其中包含要治療的區域和要避開的區域。 這稱為分段。 這張分割的地圖被輸入放射線照相機器,然後它會在不傷害健康細胞的情況下瞄準癌細胞。
對於頭部或頸部區域的癌症,這對放射科醫生來說是一項艱鉅的工作,因為它涉及非常敏感的器官。 放射科醫生大約需要四個小時才能為該區域創建分段地圖。 DeepMind 通過其算法旨在將生成分割地圖所需的時間從 4 小時減少到 1 小時。 這將大大節省放射科醫生的時間。 更重要的是,這種分割算法可以用於身體的其他部位。
總而言之,AlphaGo 在 2016 年的五強賽中四次成功擊敗了 18 次世界圍棋冠軍李世石。2017 年,它甚至擊敗了一支世界上最好的棋手。 它使用 DNN 和 DQN 的組合作為提出下一個最佳舉措的策略網絡,並使用一個 DNN 作為價值網絡來評估遊戲的結果。 蒙特卡洛樹搜索與策略和價值網絡一起使用,以減少搜索的寬度和深度——它們用於改進評估功能。 該算法的最終目的不是解決棋盤遊戲,而是發明一種通用人工智能算法。 AlphaGo 無疑是朝著這個方向邁出了一大步。
數據科學、機器學習和大數據之間的區別!
當然,還有其他影響。 隨著 AlphaGo Vs Lee Seedol 的消息在網上瘋傳,對圍棋棋盤的需求猛增了十倍。 許多商店報告了圍棋板缺貨的情況,購買圍棋板變得具有挑戰性。
幸運的是,我剛剛找到一個並為我自己和我的孩子訂購了它。 你打算買板子學圍棋嗎?
從世界頂級大學學習 ML 課程。 獲得碩士、Executive PGP 或高級證書課程以加快您的職業生涯。
深度強化學習的局限性是什麼?
當引入新數據或信息時,DL 會忘記先前獲得的知識,因此它不會挑戰它。 過多的強化有時會導致狀態過多,從而降低有效性。 由於數據模型的複雜性,訓練成本非常高。 深度學習還需要使用昂貴的 GPU 和數百個工作站。 結果,它的使用變得不那麼經濟。
使用蒙特卡洛樹搜索有什麼缺點?
雖然 MCTS 是一種簡單的執行算法,但它確實有一些缺點。 當樹在幾次迭代後變大時,需要大量內存。 當應用於回合製遊戲時,可能有一個分支或路徑會導致在特定條件下輸給對手。 結果,它不太可靠。 經過多次迭代,蒙特卡洛樹搜索需要很長時間才能確定最有效的路徑。
AlphaZero 與 AlphaGo Zero 有何不同?
早期版本的 AlphaGo 包含少量手工設計的功能,但 AlphaGo Zero 僅使用圍棋板上的黑白棋子作為輸入。 早期版本的 AlphaGo 依靠策略網絡來選擇下一步行動,並依靠價值網絡從每個位置估計遊戲的獲勝者。 這些被合併到 AlphaGo Zero 中,允許更有效的訓練和評估。 所有這些差異都有助於系統提高性能和泛化能力。 另一方面,算法調整使系統更加強大和高效。