Tutto quello che devi sapere su Apache Storm
Pubblicato: 2018-02-20La crescita sempre crescente nella produzione e nell'analisi dei Big Data continua a presentare nuove sfide e i data scientist e i programmatori lo prendono con grazia, migliorando costantemente le applicazioni da loro sviluppate. Uno di questi problemi era quello dello streaming in tempo reale. I dati in tempo reale hanno un valore estremamente elevato per le aziende, ma hanno una finestra temporale dopo la quale perdono il loro valore: una data di scadenza, se vuoi. Se il valore di questi dati in tempo reale non viene realizzato all'interno della finestra, non è possibile estrarre informazioni utilizzabili da essa. Questi dati in tempo reale arrivano rapidamente e continuamente, da qui il termine "Streaming".
L'analisi di questi dati in tempo reale può aiutarti a rimanere aggiornato su ciò che sta accadendo in questo momento, come il numero di persone che leggono il tuo post sul blog o il numero di persone che visitano la tua pagina Facebook. Sebbene possa sembrare solo una caratteristica "piacevole da avere", in pratica è essenziale. Immagina di far parte di un'agenzia pubblicitaria che esegue analisi in tempo reale sulle tue campagne pubblicitarie, per le quali il cliente ha pagato molto. L'analisi in tempo reale può tenerti aggiornato sulle prestazioni del tuo annuncio sul mercato, su come gli utenti stanno rispondendo ad esso e altre cose del genere. Uno strumento piuttosto essenziale se la pensi in questo modo, giusto?
Osservando il valore dei dati in tempo reale, le organizzazioni hanno iniziato a inventare vari strumenti di analisi dei dati in tempo reale. In questo articolo parleremo di uno di questi: Apache Storm. Vedremo di cosa si tratta, l'architettura di una tipica applicazione Storm, i suoi componenti principali (noti anche come astrazioni) e i suoi casi d'uso nella vita reale.
Andiamo!
Sommario
Cos'è Apache Storm?

Apache Storm – rilasciato da Twitter, è un framework open source distribuito che aiuta nell'elaborazione dei dati in tempo reale. Apache Storm funziona per i dati in tempo reale proprio come Hadoop funziona per l'elaborazione in batch dei dati (l'elaborazione in batch è l'opposto del tempo reale. In questo, i dati sono divisi in batch e ogni batch viene elaborato. Ciò non avviene in realtà -volta.)
Apache Storm non ha alcuna capacità di gestione dello stato e fa molto affidamento su Apache ZooKeeper (un servizio centralizzato per la gestione delle configurazioni nelle applicazioni Big Data) per gestire lo stato del cluster, ad esempio conferme di messaggi, stati di elaborazione e altri messaggi simili. Apache Storm ha le sue applicazioni progettate sotto forma di grafici aciclici diretti. È noto per l'elaborazione di oltre un milione di tuple al secondo per nodo, il che è altamente scalabile e fornisce garanzie di lavoro di elaborazione. Storm è scritto in Clojure, che è il linguaggio di programmazione funzionale-first simile a Lisp.

Al centro di Apache Storm c'è una "Definizione dell'usato" per la definizione e l'invio del grafico logico (noto anche come topologie). Poiché Thrift può essere implementato in qualsiasi lingua di tua scelta, le topologie possono anche essere create in qualsiasi lingua. Questo fa sì che Storm supporti una moltitudine di lingue, rendendolo ancora più adatto agli sviluppatori.
Storm funziona su YARN e si integra perfettamente con l'ecosistema Hadoop. È un vero framework di elaborazione dati in tempo reale con supporto batch zero. Richiede un flusso completo di dati come un intero "evento" invece di suddividerlo in serie di piccoli batch. Pertanto, è più adatto per i dati che devono essere acquisiti come una singola entità.
Diamo un'occhiata all'architettura generale di un'applicazione Storm: ti darà maggiori informazioni su come funziona Storm!
Apache Storm: architettura generale e componenti importanti
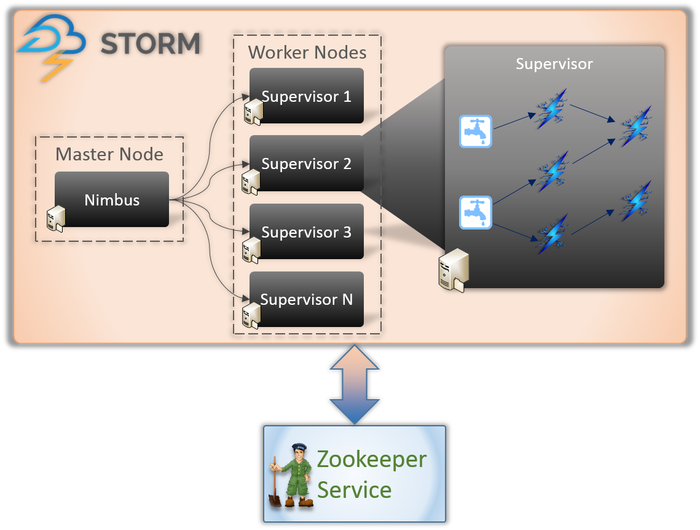
Ci sono essenzialmente due tipi di nodi coinvolti in qualsiasi applicazione Storm (come mostrato sopra).
Nodo principale (servizio Nimbus)
Se sei a conoscenza del funzionamento interno di Hadoop, devi sapere cos'è un "Job Tracker". È un demone che viene eseguito sul nodo Master di Hadoop ed è responsabile della distribuzione delle attività tra i nodi. Nimbus è un tipo di servizio simile per Storm. Viene eseguito sul nodo principale di un cluster Storm ed è responsabile della distribuzione delle attività tra i nodi di lavoro.
Nimbus è un servizio Thrift fornito da Apache che ti consente di inviare il tuo codice nel linguaggio di programmazione di tua scelta. Questo ti aiuta a scrivere la tua applicazione senza dover imparare una nuova lingua specifica per Storm.
Come abbiamo detto prima, Storm non ha alcuna capacità di gestione dello stato. Il servizio Nimbus deve fare affidamento su ZooKeeper per monitorare i messaggi inviati dai nodi di lavoro durante l'elaborazione delle attività. Tutti i nodi di lavoro aggiornano lo stato delle attività nel servizio ZooKeeper affinché Nimbus possa vederlo e monitorarlo.
Nodo di lavoro (servizio supervisore)
Questi sono i nodi responsabili dell'esecuzione dei compiti. I nodi di lavoro in Storm eseguono un servizio chiamato Supervisor. Il Supervisore è responsabile della ricezione del lavoro assegnato ad una macchina dal servizio Nimbus. Come suggerisce il nome, Supervisor supervisiona i processi dei lavoratori e li aiuta a completare i compiti assegnati. Ciascuno di questi processi di lavoro esegue un sottoinsieme della topologia completa.

Un'applicazione Storm ha essenzialmente quattro componenti/astrazioni che sono responsabili dell'esecuzione delle attività in corso. Questi sono:
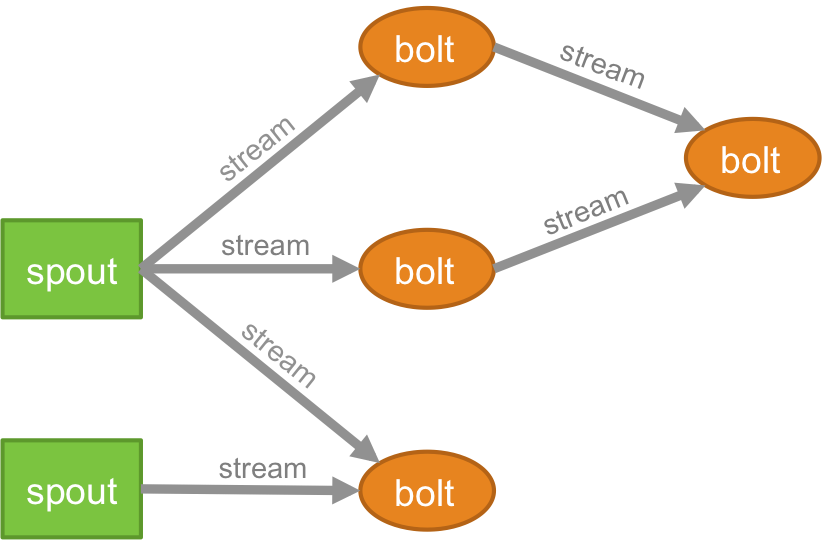
Topologia
La logica per qualsiasi applicazione in tempo reale è racchiusa sotto forma di una topologia, che è essenzialmente una rete di bulloni e beccucci. Per capire meglio, puoi confrontarlo con i lavori MapReduce (leggi il nostro articolo su MapReduce se non sai di cosa si tratta!). Una differenza fondamentale è che il processo MapReduce termina quando la sua esecuzione è completa, mentre una topologia Storm viene eseguita per sempre (a meno che tu non la uccida esplicitamente). La rete è costituita da nodi che costituiscono la logica di elaborazione e da collegamenti (detti anche stream) che dimostrano il passaggio dei dati e l'esecuzione dei processi.
Flusso
Devi capire cosa sono le tuple prima di capire cosa sono i flussi. Le tuple sono le principali strutture di dati in un cluster Storm. Questi sono elenchi di valori denominati in cui i valori possono essere qualsiasi cosa, da interi, long, short, byte, double, stringhe, float booleani, a array di byte. Ora, i .stream sono una sequenza di tuple che vengono create ed elaborate in tempo reale in un ambiente distribuito. Costituiscono l'unità di astrazione principale di un cluster Spark.
Becco
Un germoglio è la fonte dei flussi in una tupla Storm. È responsabile di entrare in contatto con l'effettiva fonte di dati, ricevere dati continuamente, trasformare quei dati nel flusso effettivo di tuple e infine inviarli ai bulloni da elaborare. Può essere affidabile o inaffidabile. Uno Spout affidabile riprodurrà la tupla se non viene elaborata da Storm, uno Spout inaffidabile, d'altra parte, dimenticherà la tupla subito dopo averla emessa.
Bullone
I bulloni sono responsabili dell'esecuzione di tutte le elaborazioni della topologia. Costituiscono l'unità logica di elaborazione di un'applicazione Storm. È possibile utilizzare bolt per eseguire molte operazioni essenziali come filtraggio, funzioni, join, aggregazioni, connessione a database e molte altre.
Chi usa Tempesta?
Sebbene una serie di strumenti potenti e facili da usare siano presenti nel mercato dei Big Data, Storm trova un posto unico in quell'elenco grazie alla sua capacità di gestire qualsiasi linguaggio di programmazione che gli viene lanciato. Molte organizzazioni utilizzano Storm.
Diamo un'occhiata a un paio di grandi giocatori che usano Apache Storm e come!
Twitter

Twitter utilizza Storm per alimentare una varietà dei suoi sistemi, dalla personalizzazione del feed, all'ottimizzazione delle entrate, al miglioramento dei risultati di ricerca e altri processi simili. Poiché Twitter ha sviluppato Storm (che è stato successivamente acquistato da Apache e chiamato Apache Storm), si integra perfettamente con il resto dell'infrastruttura di Twitter: i sistemi di database (Cassandra, Memcached, ecc.), L'ambiente di messaggistica (Mesos) e i sistemi di monitoraggio .
Spotify

Spotify è noto per lo streaming di musica a oltre 50 milioni di utenti attivi e 10 milioni di abbonati. Fornisce un'ampia gamma di funzionalità in tempo reale come consigli musicali, monitoraggio, analisi, targeting degli annunci e creazione di playlist. Per raggiungere questa impresa, Spotify utilizza Apache Storm.
Impilato con l'ambiente di messaggistica basato su Kafka, Memcached e netty-zmtp, Apache Storm consente a Spotify di creare facilmente sistemi distribuiti a tolleranza d'errore a bassa latenza.
Per concludere...
Se desideri affermare la tua carriera come analista di Big Data, lo streaming è la strada da percorrere. Se sei in grado di padroneggiare l'arte di gestire i dati in tempo reale, sarai la preferenza numero uno per le aziende che assumono per un ruolo di analista. Non potrebbe esserci momento migliore per immergersi nell'analisi dei dati in tempo reale perché questa è la necessità del momento nel vero senso della parola!
Se sei interessato a saperne di più sui Big Data, dai un'occhiata al nostro PG Diploma in Software Development Specialization nel programma Big Data, progettato per professionisti che lavorano e fornisce oltre 7 casi di studio e progetti, copre 14 linguaggi e strumenti di programmazione, pratiche pratiche workshop, oltre 400 ore di apprendimento rigoroso e assistenza all'inserimento lavorativo con le migliori aziende.

Impara le lauree in ingegneria del software online dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.