Alles, was Sie über Apache Storm wissen müssen
Veröffentlicht: 2018-02-20Das ständig wachsende Wachstum bei der Produktion und Analyse von Big Data stellt immer wieder neue Herausforderungen dar, und die Datenwissenschaftler und Programmierer gehen damit gelassen um – indem sie die von ihnen entwickelten Anwendungen ständig verbessern. Ein solches Problem war das Echtzeit-Streaming. Echtzeitdaten haben einen extrem hohen Wert für Unternehmen, aber sie haben ein Zeitfenster, nach dem sie ihren Wert verlieren – ein Ablaufdatum, wenn Sie so wollen. Wenn der Wert dieser Echtzeitdaten nicht innerhalb des Fensters erkannt wird, können keine verwertbaren Informationen daraus extrahiert werden. Diese Echtzeitdaten kommen schnell und kontinuierlich herein, daher der Begriff „Streaming“.
Die Analyse dieser Echtzeitdaten kann Ihnen dabei helfen, auf dem Laufenden zu bleiben, was gerade passiert, wie z. B. die Anzahl der Personen, die Ihren Blogbeitrag lesen, oder die Anzahl der Personen, die Ihre Facebook-Seite besuchen. Auch wenn es nur nach einer „nice-to-have“-Funktion klingen mag, ist es in der Praxis unerlässlich. Stellen Sie sich vor, Sie sind Teil einer Werbeagentur, die Echtzeitanalysen zu Ihren Werbekampagnen durchführt – für die der Kunde viel bezahlt hat. Echtzeitanalysen können Sie darüber auf dem Laufenden halten, wie Ihre Anzeige auf dem Markt abschneidet, wie die Benutzer darauf reagieren und andere Dinge dieser Art. Ein ziemlich wichtiges Werkzeug, wenn Sie es so sehen, oder?
Betrachtet man den Wert, den Echtzeitdaten haben, begannen Unternehmen, verschiedene Echtzeit-Datenanalysetools zu entwickeln. In diesem Artikel werden wir über eines davon sprechen – Apache Storm. Wir werden uns ansehen, was es ist, die Architektur einer typischen Storm-Anwendung, ihre Kernkomponenten (auch bekannt als Abstraktionen) und ihre Anwendungsfälle im wirklichen Leben.
Lass uns gehen!
Inhaltsverzeichnis
Was ist Apache Storm?

Apache Storm – veröffentlicht von Twitter, ist ein verteiltes Open-Source-Framework, das bei der Echtzeitverarbeitung von Daten hilft. Apache Storm funktioniert für Echtzeitdaten genauso wie Hadoop für die Batch-Verarbeitung von Daten (Batch-Verarbeitung ist das Gegenteil von Echtzeit. Dabei werden Daten in Batches aufgeteilt und jeder Batch wird verarbeitet. Dies geschieht nicht in Wirklichkeit -Zeit.)
Apache Storm verfügt über keine Statusverwaltungsfunktionen und verlässt sich stark auf Apache ZooKeeper (einen zentralisierten Dienst zur Verwaltung der Konfigurationen in Big-Data-Anwendungen), um seinen Clusterstatus zu verwalten – Dinge wie Nachrichtenbestätigungen, Verarbeitungsstatus und andere solche Nachrichten. Apache Storm hat seine Anwendungen in Form von gerichteten azyklischen Graphen entworfen. Es ist bekannt für die Verarbeitung von über einer Million Tupeln pro Sekunde und Knoten – was hochgradig skalierbar ist und Garantien für Verarbeitungsaufträge bietet. Storm ist in Clojure geschrieben, der Lisp-ähnlichen Functional-First-Programmiersprache.

Das Herzstück von Apache Storm ist eine „Thrift-Definition“ zum Definieren und Übermitteln des Logikdiagramms (auch bekannt als Topologien). Da Thrift in jeder Sprache Ihrer Wahl implementiert werden kann, können Topologien auch in jeder Sprache erstellt werden. Dadurch unterstützt Storm eine Vielzahl von Sprachen – was es umso entwicklerfreundlicher macht.
Storm läuft auf YARN und lässt sich perfekt in das Hadoop-Ökosystem integrieren. Es ist ein echtes Echtzeit-Datenverarbeitungs-Framework ohne Batch-Unterstützung. Es nimmt einen vollständigen Datenstrom als ganzes „Ereignis“ auf, anstatt ihn in eine Reihe kleiner Stapel aufzuteilen. Daher eignet es sich am besten für Daten, die als einzelne Entität aufgenommen werden sollen.
Werfen wir einen Blick auf die allgemeine Architektur einer Storm-Anwendung – Sie erhalten mehr Einblicke in die Funktionsweise von Storm!
Apache Storm: Allgemeine Architektur und wichtige Komponenten
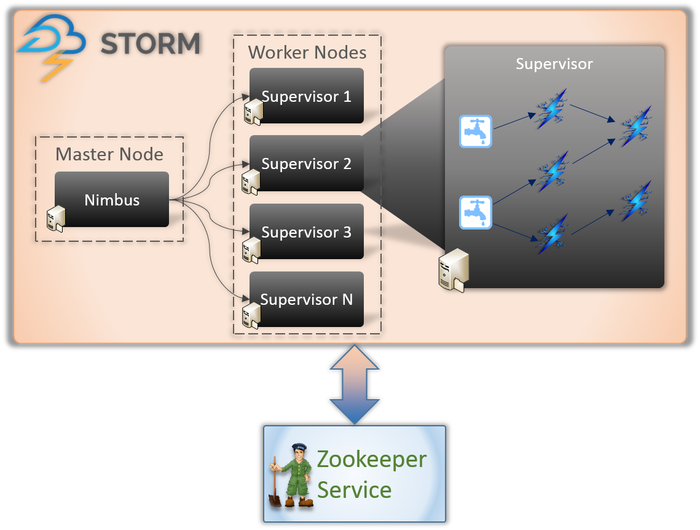
An jeder Storm-Anwendung sind im Wesentlichen zwei Arten von Knoten beteiligt (wie oben gezeigt).
Master-Knoten (Nimbus-Dienst)
Wenn Sie sich der inneren Funktionsweise von Hadoop bewusst sind, müssen Sie wissen, was ein „Job Tracker“ ist. Es ist ein Daemon, der auf dem Master-Knoten von Hadoop ausgeführt wird und für die Verteilung von Aufgaben auf die Knoten verantwortlich ist. Nimbus ist eine ähnliche Art von Service für Storm. Es läuft auf dem Master-Knoten eines Storm-Clusters und ist für die Verteilung der Aufgaben auf die Worker-Knoten verantwortlich.
Nimbus ist ein von Apache bereitgestellter Thrift-Dienst, mit dem Sie Ihren Code in der Programmiersprache Ihrer Wahl übermitteln können. Dies hilft Ihnen, Ihre Bewerbung zu schreiben, ohne eine neue Sprache speziell für Storm lernen zu müssen.
Wie wir bereits besprochen haben, fehlt Storm jegliche Fähigkeit zur Zustandsverwaltung. Der Nimbus-Dienst muss sich auf ZooKeeper verlassen, um die Nachrichten zu überwachen, die von den Worker-Knoten gesendet werden, während die Aufgaben verarbeitet werden. Alle Worker-Knoten aktualisieren ihren Aufgabenstatus im ZooKeeper-Dienst, damit Nimbus sie sehen und überwachen kann.
Worker-Knoten (Supervisor-Dienst)
Dies sind die Knoten, die für die Ausführung der Aufgaben verantwortlich sind. Worker-Knoten in Storm führen einen Dienst namens Supervisor aus. Der Supervisor ist dafür verantwortlich, die einer Maschine vom Nimbus-Service zugewiesene Arbeit entgegenzunehmen. Wie der Name schon sagt, überwacht Supervisor die Worker-Prozesse und hilft ihnen, die zugewiesenen Aufgaben zu erledigen. Jeder dieser Worker-Prozesse führt eine Teilmenge der vollständigen Topologie aus.

Eine Storm-Anwendung besteht im Wesentlichen aus vier Komponenten/Abstraktionen, die für die Ausführung der anstehenden Aufgaben verantwortlich sind. Diese sind:
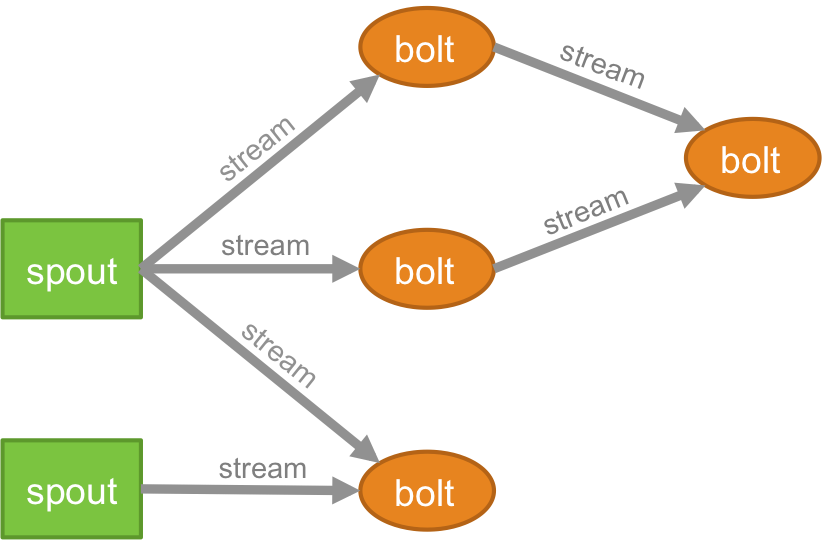
Topologie
Die Logik für jede Echtzeitanwendung ist in Form einer Topologie verpackt – die im Wesentlichen ein Netzwerk aus Schrauben und Spouts ist. Zum besseren Verständnis können Sie es mit den MapReduce-Jobs vergleichen (lesen Sie unseren Artikel über MapReduce, wenn Sie nicht wissen, was das ist!). Ein wesentlicher Unterschied besteht darin, dass der MapReduce-Job beendet wird, wenn seine Ausführung abgeschlossen ist, während eine Storm-Topologie für immer ausgeführt wird (es sei denn, Sie beenden ihn ausdrücklich selbst). Das Netzwerk besteht aus Knoten, die die Verarbeitungslogik bilden, und Links (auch als Stream bekannt), die die Weitergabe von Daten und die Ausführung von Prozessen demonstrieren.
Strom
Sie müssen verstehen, was Tupel sind, bevor Sie verstehen, was Streams sind. Tupel sind die Hauptdatenstrukturen in einem Storm-Cluster. Dies sind benannte Wertelisten, bei denen die Werte alles sein können, von Ganzzahlen, Longs, Shorts, Bytes, Doubles, Strings, Booleans Floats bis hin zu Byte-Arrays. Jetzt sind .streams eine Folge von Tupeln, die in Echtzeit in einer verteilten Umgebung erstellt und verarbeitet werden. Sie bilden die zentrale Abstraktionseinheit eines Spark-Clusters.
Tülle
Ein Sprout ist die Quelle von Streams in einem Storm-Tupel. Es ist dafür verantwortlich, mit der eigentlichen Datenquelle in Kontakt zu treten, Daten kontinuierlich zu empfangen, diese Daten in den tatsächlichen Tupelstrom umzuwandeln und sie schließlich zur Verarbeitung an die Bolts zu senden. Es kann entweder zuverlässig oder unzuverlässig sein. Ein zuverlässiger Spout gibt das Tupel erneut wieder, wenn es von Storm nicht verarbeitet werden konnte, ein unzuverlässiger Spout hingegen vergisst das Tupel bald nach der Ausgabe.
Bolzen
Bolts sind für die Durchführung der gesamten Verarbeitung der Topologie verantwortlich. Sie bilden die Verarbeitungslogik einer Storm-Anwendung. Man kann Bolt verwenden, um viele wichtige Operationen wie Filtern, Funktionen, Verknüpfungen, Aggregationen, Verbindungen zu Datenbanken und vieles mehr durchzuführen.
Wer verwendet Sturm?
Obwohl eine Reihe leistungsstarker und benutzerfreundlicher Tools auf dem Markt für Big Data präsent sind, nimmt Storm einen einzigartigen Platz in dieser Liste ein, da es mit jeder Programmiersprache umgehen kann, die Sie darauf werfen. Viele Organisationen setzen Storm ein.
Schauen wir uns ein paar große Spieler an, die Apache Storm verwenden und wie!
Twitter

Twitter verwendet Storm, um eine Vielzahl seiner Systeme zu betreiben – von der Personalisierung Ihres Feeds, der Umsatzoptimierung bis hin zur Verbesserung der Suchergebnisse und anderer derartiger Prozesse. Da Twitter Storm entwickelt hat (das später von Apache gekauft und Apache Storm genannt wurde), lässt es sich nahtlos in die restliche Infrastruktur von Twitter integrieren – die Datenbanksysteme (Cassandra, Memcached usw.), die Messaging-Umgebung (Mesos) und die Überwachungssysteme .
Spotify

Spotify ist dafür bekannt, Musik an über 50 Millionen aktive Benutzer und 10 Millionen Abonnenten zu streamen. Es bietet eine breite Palette von Echtzeitfunktionen wie Musikempfehlungen, Überwachung, Analysen, Anzeigenausrichtung und Erstellung von Wiedergabelisten. Um dieses Kunststück zu erreichen, verwendet Spotify Apache Storm.
Gestapelt mit Kafka, Memcached und einer netty-zmtp-basierten Messaging-Umgebung ermöglicht Apache Storm Spotify den einfachen Aufbau fehlertoleranter verteilter Systeme mit geringer Latenz.
Einwickeln…
Wenn Sie Ihre Karriere als Big-Data-Analyst aufbauen möchten, ist Streaming der richtige Weg. Wenn Sie in der Lage sind, mit Echtzeitdaten umzugehen, sind Sie die erste Wahl für Unternehmen, die eine Analystenrolle einstellen. Es könnte keinen besseren Zeitpunkt geben, um in die Echtzeit-Datenanalyse einzutauchen, denn das ist im wahrsten Sinne des Wortes das Gebot der Stunde!
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.

Lernen Sie Software-Engineering-Abschlüsse online von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.