Tout ce que vous devez savoir sur Apache Storm
Publié: 2018-02-20La croissance toujours croissante de la production et de l'analyse du Big Data continue de présenter de nouveaux défis, et les data scientists et les programmeurs le relèvent avec élégance - en améliorant constamment les applications qu'ils développent. L'un de ces problèmes était celui du streaming en temps réel. Les données en temps réel ont une valeur extrêmement élevée pour les entreprises, mais elles ont une fenêtre de temps après laquelle elles perdent leur valeur - une date d'expiration, si vous voulez. Si la valeur de ces données en temps réel n'est pas réalisée dans la fenêtre, aucune information utilisable ne peut en être extraite. Ces données en temps réel arrivent rapidement et en continu, d'où le terme "Streaming".
L'analyse de ces données en temps réel peut vous aider à rester informé de ce qui se passe en ce moment, comme le nombre de personnes lisant votre article de blog ou le nombre de personnes visitant votre page Facebook. Bien que cela puisse sembler être juste une fonctionnalité "agréable à avoir", dans la pratique, c'est essentiel. Imaginez que vous faites partie d'une agence de publicité effectuant des analyses en temps réel sur vos campagnes publicitaires - pour lesquelles le client a payé cher. Les analyses en temps réel peuvent vous tenir au courant des performances de votre annonce sur le marché, de la réaction des utilisateurs et d'autres éléments de cette nature. Un outil assez essentiel si vous y pensez de cette façon, n'est-ce pas?
En examinant la valeur des données en temps réel, les organisations ont commencé à proposer divers outils d'analyse de données en temps réel. Dans cet article, nous parlerons de l'un d'eux - Apache Storm. Nous verrons ce que c'est, l'architecture d'une application Storm typique, ses composants de base (également appelés abstractions) et ses cas d'utilisation réels.
Allons-y!
Table des matières
Qu'est-ce qu'Apache Storm ?

Apache Storm - publié par Twitter, est un framework open source distribué qui aide au traitement en temps réel des données. Apache Storm fonctionne pour les données en temps réel tout comme Hadoop fonctionne pour le traitement par lots des données (le traitement par lots est l'opposé du temps réel. En cela, les données sont divisées en lots et chaque lot est traité. Ce n'est pas fait en temps réel. -temps.)
Apache Storm ne dispose d'aucune capacité de gestion d'état et s'appuie fortement sur Apache ZooKeeper (un service centralisé de gestion des configurations dans les applications Big Data) pour gérer l'état de son cluster - des éléments tels que les accusés de réception de message, les statuts de traitement et d'autres messages de ce type. Apache Storm voit ses applications conçues sous la forme de graphes acycliques dirigés. Il est connu pour traiter plus d'un million de tuples par seconde par nœud, ce qui est hautement évolutif et offre des garanties de travail de traitement. Storm est écrit en Clojure qui est le premier langage de programmation fonctionnel de type Lisp.

Au cœur d'Apache Storm se trouve une "Thrift Definition" pour définir et soumettre le graphe logique (également appelé topologies). Étant donné que Thrift peut être implémenté dans n'importe quelle langue de votre choix, les topologies peuvent également être créées dans n'importe quelle langue. Cela permet à Storm de prendre en charge une multitude de langues, ce qui le rend d'autant plus convivial pour les développeurs.
Storm fonctionne sur YARN et s'intègre parfaitement à l'écosystème Hadoop. Il s'agit d'un véritable cadre de traitement de données en temps réel sans prise en charge des lots. Il prend un flux complet de données comme un "événement" entier au lieu de le diviser en séries de petits lots. Par conséquent, il convient mieux aux données qui doivent être ingérées en tant qu'entité unique.
Jetons un coup d'œil à l'architecture générale d'une application Storm – Cela vous donnera plus d'informations sur le fonctionnement de Storm !
Apache Storm : architecture générale et composants importants
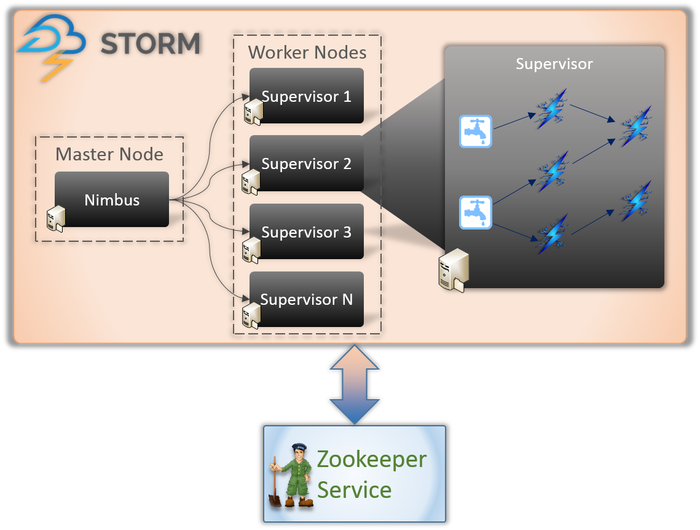
Il existe essentiellement deux types de nœuds impliqués dans toute application Storm (comme indiqué ci-dessus).
Nœud maître (service Nimbus)
Si vous connaissez le fonctionnement interne de Hadoop, vous devez savoir ce qu'est un « Job Tracker ». C'est un démon qui s'exécute sur le nœud maître de Hadoop et est responsable de la répartition des tâches entre les nœuds. Nimbus est un type de service similaire pour Storm. Il s'exécute sur le nœud maître d'un cluster Storm et est responsable de la répartition des tâches entre les nœuds de travail.
Nimbus est un service Thrift fourni par Apache qui vous permet de soumettre votre code dans le langage de programmation de votre choix. Cela vous aide à écrire votre application sans avoir à apprendre un nouveau langage spécifiquement pour Storm.
Comme nous en avons parlé plus tôt, Storm ne dispose d'aucune capacité de gestion d'état. Le service Nimbus doit s'appuyer sur ZooKeeper pour surveiller les messages envoyés par les nœuds de travail lors du traitement des tâches. Tous les nœuds de travail mettent à jour l'état de leur tâche dans le service ZooKeeper pour que Nimbus puisse le voir et le surveiller.

Nœud de travail (service de supervision)
Ce sont les nœuds responsables de l'exécution des tâches. Les nœuds de travail dans Storm exécutent un service appelé Supervisor. Le Superviseur est responsable de la réception des travaux confiés à une machine par le service Nimbus. Comme son nom l'indique, le superviseur supervise les processus de travail et les aide à accomplir les tâches assignées. Chacun de ces processus de travail exécute un sous-ensemble de la topologie complète.
Une application Storm comporte essentiellement quatre composants/abstractions qui sont responsables de l'exécution des tâches à accomplir. Ceux-ci sont:
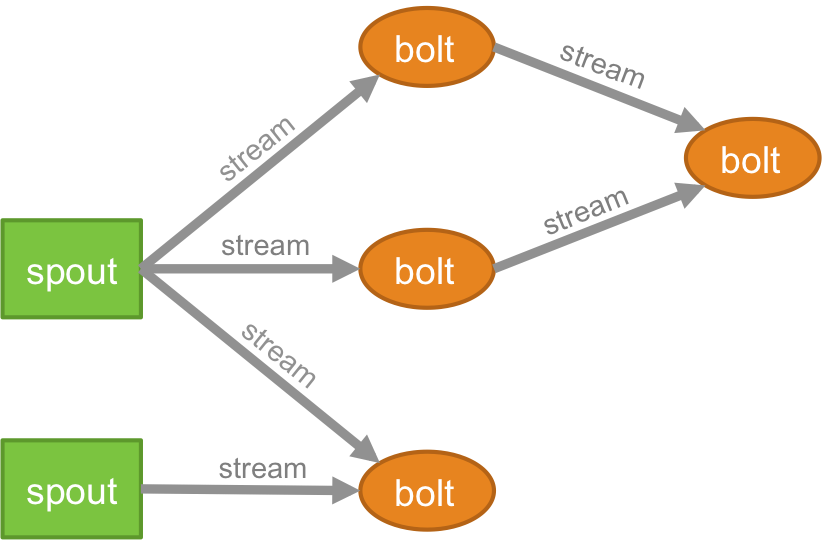
Topologie
La logique de toute application en temps réel est conditionnée sous la forme d'une topologie - qui est essentiellement un réseau de boulons et de becs. Pour mieux comprendre, vous pouvez le comparer aux jobs MapReduce (lisez notre article sur MapReduce si vous ne savez pas de quoi il s'agit !). Une différence essentielle est que la tâche MapReduce se termine lorsque son exécution est terminée, alors qu'une topologie Storm s'exécute indéfiniment (sauf si vous la tuez explicitement vous-même). Le réseau se compose de nœuds qui forment la logique de traitement et de liens (également appelés flux) qui démontrent la transmission des données et l'exécution des processus.
Flux
Vous devez comprendre ce que sont les tuples avant de comprendre ce que sont les flux. Les tuples sont les principales structures de données dans un cluster Storm. Ce sont des listes de valeurs nommées où les valeurs peuvent être n'importe quoi, des entiers, longs, courts, octets, doubles, chaînes, booléens flottants, aux tableaux d'octets. Désormais, les flux sont une séquence de tuples qui sont créés et traités en temps réel dans un environnement distribué. Ils forment l'unité d'abstraction centrale d'un cluster Spark.
Bec
Un germe est la source des flux dans un tuple Storm. Il est chargé d'entrer en contact avec la source de données réelle, de recevoir des données en continu, de transformer ces données en flux réel de tuples et enfin de les envoyer aux boulons à traiter. Il peut être fiable ou non fiable. Un Spout fiable rejouera le tuple s'il n'a pas été traité par Storm, un Spout non fiable, d'autre part, oubliera le tuple peu de temps après l'avoir émis.
Verrouiller
Les boulons sont chargés d'effectuer tout le traitement de la topologie. Ils forment l'unité logique de traitement d'une application Storm. On peut utiliser bolt pour effectuer de nombreuses opérations essentielles telles que le filtrage, les fonctions, les jointures, les agrégations, la connexion aux bases de données, etc.
Qui utilise Storm ?
Bien qu'un certain nombre d'outils puissants et faciles à utiliser soient présents sur le marché du Big Data, Storm trouve une place unique dans cette liste en raison de sa capacité à gérer n'importe quel langage de programmation que vous lui lancez. De nombreuses organisations utilisent Storm.
Regardons quelques gros joueurs qui utilisent Apache Storm et comment !
Twitter

Twitter utilise Storm pour alimenter une variété de ses systèmes - de la personnalisation de votre flux, l'optimisation des revenus, à l'amélioration des résultats de recherche et d'autres processus similaires. Parce que Twitter a développé Storm (qui a ensuite été acheté par Apache et nommé Apache Storm), il s'intègre de manière transparente au reste de l'infrastructure de Twitter - les systèmes de base de données (Cassandra, Memcached, etc.), l'environnement de messagerie (Mesos) et les systèmes de surveillance. .
Spotify

Spotify est connu pour diffuser de la musique à plus de 50 millions d'utilisateurs actifs et 10 millions d'abonnés. Il fournit un large éventail de fonctionnalités en temps réel telles que la recommandation de musique, la surveillance, l'analyse, le ciblage des publicités et la création de listes de lecture. Pour réaliser cet exploit, Spotify utilise Apache Storm.
Empilé avec l'environnement de messagerie basé sur Kafka, Memcached et netty-zmtp, Apache Storm permet à Spotify de créer facilement des systèmes distribués à faible latence tolérants aux pannes.
Envelopper…
Si vous souhaitez établir votre carrière en tant qu'analyste Big Data, le streaming est la voie à suivre. Si vous êtes capable de maîtriser l'art de traiter des données en temps réel, vous serez la préférence numéro un pour les entreprises qui embauchent pour un rôle d'analyste. Il ne pouvait pas y avoir de meilleur moment pour se plonger dans l'analyse de données en temps réel, car c'est le besoin de l'heure dans le vrai sens du terme !
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.

Apprenez des diplômes en génie logiciel en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.