Tot ce trebuie să știți despre Apache Storm
Publicat: 2018-02-20Creșterea din ce în ce mai mare a producției și a analizei Big Data continuă să prezinte noi provocări, iar oamenii de știință de date și programatorii o iau cu grație pe pasul lor - îmbunătățind constant aplicațiile dezvoltate de ei. O astfel de problemă a fost cea a streamingului în timp real. Datele în timp real au o valoare extrem de mare pentru afaceri, dar au o fereastră de timp după care își pierd valoarea – o dată de expirare, dacă vreți. Dacă valoarea acestor date în timp real nu este realizată în fereastră, nu pot fi extrase informații utilizabile din aceasta. Aceste date în timp real vin rapid și continuu, prin urmare termenul „Streaming”.
Analiza acestor date în timp real vă poate ajuta să fiți la curent cu ceea ce se întâmplă acum, cum ar fi numărul de persoane care vă citesc postarea de pe blog sau numărul de persoane care vă vizitează pagina de Facebook. Deși s-ar putea să sune doar ca o caracteristică „drăguță de a avea”, în practică, este esențială. Imaginați-vă că faceți parte dintr-o agenție publicitară care efectuează analize în timp real asupra campaniilor dvs. publicitare – pentru care clientul a plătit foarte mult. Analizele în timp real vă pot ține la curent cu privire la performanța anunțului dvs. pe piață, la modul în care utilizatorii răspund la acesta și la alte lucruri de acest fel. Un instrument destul de esențial dacă te gândești la asta, nu?
Privind valoarea pe care o dețin datele în timp real, organizațiile au început să vină cu diverse instrumente de analiză a datelor în timp real. În acest articol, vom vorbi despre unul dintre acestea – Apache Storm. Ne vom uita la ce este, arhitectura unei aplicații tipice de furtună, componentele sale de bază (cunoscute și sub denumirea de abstracții) și cazurile sale reale de utilizare.
Să mergem!
Cuprins
Ce este Apache Storm?

Apache Storm – lansat de Twitter, este un cadru open-source distribuit care ajută la procesarea în timp real a datelor. Apache Storm funcționează pentru date în timp real, la fel cum Hadoop funcționează pentru procesarea în serie a datelor (Procesarea în lot este opusă în timp real. În acest sens, datele sunt împărțite în loturi și fiecare lot este procesat. Acest lucru nu se face în mod real. -timp.)
Apache Storm nu are capabilități de gestionare a stării și se bazează în mare măsură pe Apache ZooKeeper (un serviciu centralizat pentru gestionarea configurațiilor în aplicațiile Big Data) pentru a-și gestiona starea clusterului - lucruri precum recunoașterea mesajelor, stările de procesare și alte astfel de mesaje. Apache Storm are aplicațiile proiectate sub formă de grafice aciclice direcționate. Este cunoscut pentru procesarea a peste un milion de tupluri pe secundă pe nod – ceea ce este foarte scalabil și oferă garanții de procesare. Storm este scris în Clojure, care este limbajul de programare funcțional similar Lisp.

În centrul Apache Storm se află o „Definiție Thrift” pentru definirea și transmiterea graficului logic (cunoscut și ca topologii). Deoarece Thrift poate fi implementat în orice limbă la alegere, topologiile pot fi create și în orice limbă. Acest lucru face ca Storm să accepte o multitudine de limbi – făcându-l cu atât mai prietenos pentru dezvoltatori.
Storm rulează pe YARN și se integrează perfect cu ecosistemul Hadoop. Este un adevărat cadru de procesare a datelor în timp real, cu suport zero lot. Este nevoie de un flux complet de date ca un întreg „eveniment” în loc să-l divizeze în serii de loturi mici. Prin urmare, este cel mai potrivit pentru datele care urmează să fie ingerate ca o singură entitate.
Să aruncăm o privire asupra arhitecturii generale a unei aplicații Storm – Vă va oferi mai multe informații despre cum funcționează Storm!
Apache Storm: Arhitectură generală și componente importante
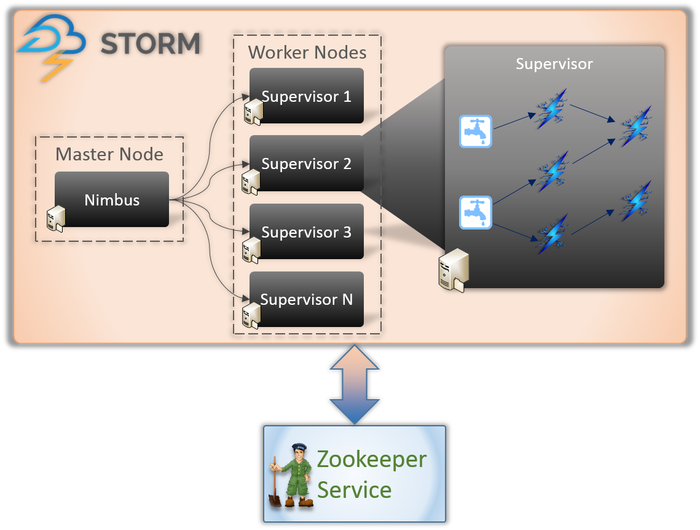
Există în esență două tipuri de noduri implicate în orice aplicație Storm (așa cum se arată mai sus).
Nod principal (Serviciul Nimbus)
Dacă sunteți conștient de funcționarea interioară a Hadoop, trebuie să știți ce este un „Job Tracker”. Este un demon care rulează pe nodul Master al Hadoop și este responsabil pentru distribuirea sarcinilor între noduri. Nimbus este un tip similar de serviciu pentru Storm. Se rulează pe nodul principal al unui cluster Storm și este responsabil pentru distribuirea sarcinilor între nodurile lucrătoare.
Nimbus este un serviciu Thrift oferit de Apache care vă permite să trimiteți codul în limbajul de programare la alegere. Acest lucru vă ajută să vă scrieți aplicația fără a fi nevoie să învățați o nouă limbă special pentru Storm.
După cum am vorbit mai devreme, Storm nu are nicio capacitate de gestionare a statului. Serviciul Nimbus trebuie să se bazeze pe ZooKeeper pentru a monitoriza mesajele trimise de nodurile de lucru în timpul procesării sarcinilor. Toate nodurile de lucru își actualizează starea sarcinii în serviciul ZooKeeper pentru ca Nimbus să le vadă și să le monitorizeze.
Worker Node (Serviciul de supraveghere)
Acestea sunt nodurile responsabile pentru îndeplinirea sarcinilor. Nodurile de lucru din Storm rulează un serviciu numit Supervisor. Supervizorul este responsabil pentru primirea lucrărilor atribuite unei mașini de către serviciul Nimbus. După cum sugerează și numele, supervizorul supraveghează procesele lucrătorilor și îi ajută să îndeplinească sarcinile atribuite. Fiecare dintre aceste procese de lucru execută un subset al topologiei complete.

O aplicație Storm are în esență patru componente/abstracte care sunt responsabile pentru îndeplinirea sarcinilor la îndemână. Acestea sunt:
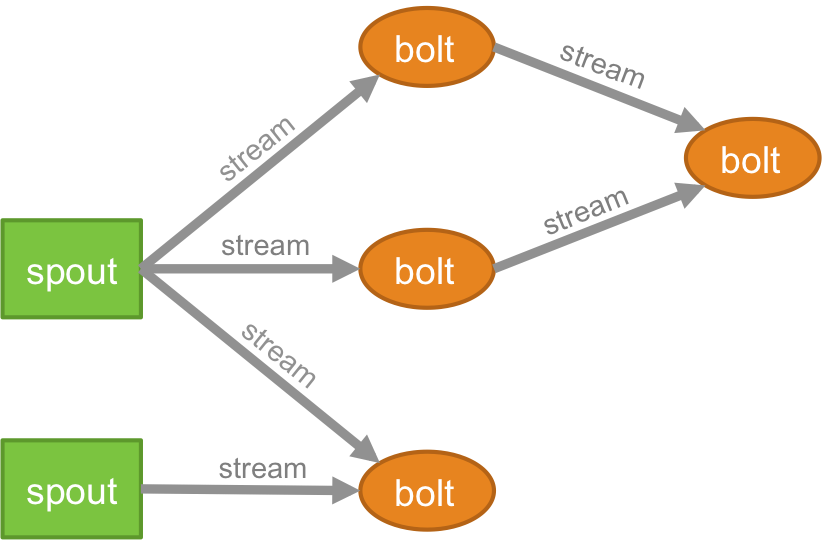
Topologie
Logica pentru orice aplicație în timp real este ambalată sub forma unei topologii – care este în esență o rețea de șuruburi și duze. Pentru a înțelege mai bine, îl puteți compara cu locurile de muncă MapReduce (citiți articolul nostru despre MapReduce dacă nu știți despre ce este asta!). O diferență cheie este că jobul MapReduce se termină când execuția sa este completă, în timp ce o topologie Storm rulează pentru totdeauna (cu excepția cazului în care o omorâți în mod explicit singur). Rețeaua constă din noduri care formează logica de procesare și legături (cunoscute și sub numele de flux) care demonstrează transmiterea datelor și execuția proceselor.
Curent
Trebuie să înțelegeți ce sunt tuplurile înainte de a înțelege ce sunt fluxurile. Tuplurile sunt principalele structuri de date dintr-un cluster Storm. Acestea sunt denumite liste de valori în care valorile pot fi orice, de la numere întregi, lungi, scurte, octeți, duble, șiruri de caractere, booleeni flotanți, până la matrice de octeți. Acum,.streamurile sunt o secvență de tupluri care sunt create și procesate în timp real într-un mediu distribuit. Ele formează unitatea de bază de abstractizare a unui cluster Spark.
Pipa
Un vlăstar este sursa fluxurilor într-un tuplu Storm. Este responsabil pentru intrarea în contact cu sursa reală de date, primirea datelor în mod continuu, transformarea acestor date în fluxul propriu-zis de tupluri și, în final, trimiterea lor către bolts pentru a fi procesate. Poate fi fie de încredere, fie nesigură. Un Spout de încredere va reda tuplu dacă nu a reușit să fie procesat de Storm, un Spout nesigur, pe de altă parte, va uita de tuplu imediat după ce l-a emis.
Bolt
Bolturile sunt responsabile pentru efectuarea întregii procesări a topologiei. Ele formează unitatea logică de procesare a unei aplicații Storm. Se poate folosi bolt pentru a efectua multe operațiuni esențiale, cum ar fi filtrarea, funcțiile, îmbinările, agregările, conectarea la baze de date și multe altele.
Cine folosește Storm?
Deși o serie de instrumente puternice și ușor de utilizat își au prezența pe piața Big Data, Storm își găsește un loc unic în această listă datorită capacității sale de a gestiona orice limbaj de programare pe care îl aruncați. Multe organizații folosesc Storm.
Să ne uităm la câțiva jucători mari care folosesc Apache Storm și cum!
Stare de nervozitate

Twitter folosește Storm pentru a alimenta o varietate de sisteme – de la personalizarea feedului dvs., optimizarea veniturilor, la îmbunătățirea rezultatelor căutării și alte astfel de procese. Deoarece Twitter a dezvoltat Storm (care a fost cumpărat ulterior de Apache și numit Apache Storm), se integrează perfect cu restul infrastructurii Twitter – sistemele de baze de date (Cassandra, Memcached etc.), mediul de mesagerie (Mesos) și sistemele de monitorizare. .
Spotify

Spotify este cunoscut pentru transmiterea de muzică la peste 50 de milioane de utilizatori activi și 10 milioane de abonați. Oferă o gamă largă de funcții în timp real, cum ar fi recomandarea muzicii, monitorizarea, analizele, direcționarea anunțurilor și crearea de liste de redare. Pentru a realiza această performanță, Spotify utilizează Apache Storm.
Împreună cu mediul de mesagerie bazat pe Kafka, Memcached și netty-zmtp, Apache Storm îi permite lui Spotify să construiască cu ușurință sisteme distribuite cu latență scăzută, tolerante la erori.
Pentru a încheia...
Dacă doriți să vă stabiliți cariera ca analist Big Data, streaming este calea de urmat. Dacă sunteți capabil să stăpâniți arta de a trata datele în timp real, veți fi preferința numărul unu pentru companiile care angajează pentru un rol de analist. Nu ar putea exista un moment mai bun pentru a te scufunda în analiza datelor în timp real, deoarece aceasta este nevoia oră în cel mai adevărat sens!
Dacă sunteți interesat să aflați mai multe despre Big Data, consultați programul nostru PG Diploma în Dezvoltare Software Specializare în Big Data, care este conceput pentru profesioniști care lucrează și oferă peste 7 studii de caz și proiecte, acoperă 14 limbaje și instrumente de programare, practică practică. ateliere de lucru, peste 400 de ore de învățare riguroasă și asistență pentru plasarea unui loc de muncă cu firme de top.

Învață diplome de Inginerie software online de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.