ApacheStormについて知っておくべきことすべて
公開: 2018-02-20ビッグデータの生産と分析の絶え間ない成長は、新しい課題を提示し続けており、データサイエンティストとプログラマーは、開発したアプリケーションを絶えず改善することで、それを優雅に前進させています。 そのような問題の1つは、リアルタイムストリーミングの問題でした。 リアルタイムデータは企業にとって非常に高い価値を持っていますが、それ以降はその価値を失う時間枠があります。必要に応じて、有効期限があります。 このリアルタイムデータの価値がウィンドウ内で実現されない場合、そこから有用な情報を抽出することはできません。 このリアルタイムデータは迅速かつ継続的に受信されるため、「ストリーミング」という用語が使用されます。
このリアルタイムデータの分析は、ブログ投稿を読んでいる人の数やFacebookページにアクセスしている人の数など、現在何が起こっているかを常に最新の状態に保つのに役立ちます。 単なる「便利な」機能のように聞こえるかもしれませんが、実際には、これは不可欠です。 あなたが広告キャンペーンのリアルタイム分析を実行している広告代理店の一部であると想像してください-クライアントは多額の費用を支払いました。 リアルタイム分析により、広告が市場でどのように機能しているか、ユーザーがどのように反応しているかなど、その性質に関する情報を常に把握できます。 このように考えると、非常に重要なツールですよね?
リアルタイムデータが持つ価値を見て、組織はさまざまなリアルタイムデータ分析ツールを考案し始めました。 この記事では、そのうちの1つであるApacheStormについて説明します。 それが何であるか、典型的なストームアプリケーションのアーキテクチャ、コアコンポーネント(抽象化とも呼ばれる)、および実際のユースケースを見ていきます。
さあ行こう!
目次
Apache Stormとは何ですか?

TwitterからリリースされたApacheStormは、データのリアルタイム処理を支援する分散型オープンソースフレームワークです。 Apache Stormは、Hadoopがデータのバッチ処理で機能するのと同じように、リアルタイムデータで機能します(バッチ処理はリアルタイムの反対です。この場合、データはバッチに分割され、各バッチが処理されます。これは実際には実行されません。 -時間。)
Apache Stormには状態管理機能がなく、Apache ZooKeeper(ビッグデータアプリケーションの構成を管理するための集中型サービス)に大きく依存して、メッセージの確認応答、処理ステータス、その他のメッセージなどのクラスター状態を管理します。 Apache Stormのアプリケーションは、有向非巡回グラフの形式で設計されています。 ノードごとに1秒あたり100万を超えるタプルを処理することで知られています。これは、拡張性が高く、処理ジョブの保証を提供します。 Stormは、Lispのような機能優先プログラミング言語であるClojureで書かれています。

Apache Stormの中心には、ロジックグラフ(トポロジとも呼ばれます)を定義して送信するための「ThriftDefinition」があります。 Thriftは任意の言語で実装できるため、トポロジは任意の言語で作成することもできます。 これにより、Stormは多数の言語をサポートするようになり、開発者にとってさらに使いやすくなります。
StormはYARNで実行され、Hadoopエコシステムと完全に統合されます。 これは、バッチをサポートしない真のリアルタイムデータ処理フレームワークです。 データの完全なストリームを一連の小さなバッチに分割するのではなく、「イベント」全体として受け取ります。 したがって、単一のエンティティとして取り込まれるデータに最適です。
Stormアプリケーションの一般的なアーキテクチャを見てみましょう– Stormがどのように機能するかについて、より多くの洞察が得られます。
Apache Storm:一般的なアーキテクチャと重要なコンポーネント
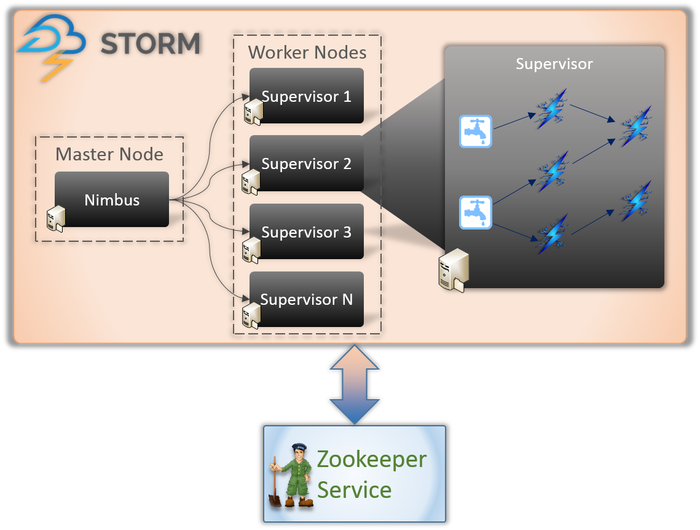
Stormアプリケーションに関係するノードには基本的に2つのタイプがあります(上記のように)。
マスターノード(ニンバスサービス)
Hadoopの内部動作を知っている場合は、「ジョブトラッカー」が何であるかを知っている必要があります。 これは、Hadoopのマスターノードで実行され、ノード間でタスクを分散する役割を担うデーモンです。 Nimbusは、Stormの同様の種類のサービスです。 Stormクラスターのマスターノードで実行され、ワーカーノード間でタスクを分散します。
Nimbusは、Apacheが提供するThriftサービスであり、選択したプログラミング言語でコードを送信できます。 これにより、Storm専用の新しい言語を習得しなくても、アプリケーションを作成できます。
前に説明したように、Stormには状態管理機能がありません。 Nimbusサービスは、タスクの処理中にワーカーノードによって送信されるメッセージを監視するためにZooKeeperに依存する必要があります。 すべてのワーカーノードは、Nimbusが表示および監視できるようにZooKeeperサービスのタスクステータスを更新します。
ワーカーノード(スーパーバイザーサービス)
これらは、タスクの実行を担当するノードです。 Stormのワーカーノードは、Supervisorと呼ばれるサービスを実行します。 スーパーバイザーは、ニンバスサービスによってマシンに割り当てられた作業を受け取る責任があります。 名前が示すように、スーパーバイザーはワーカープロセスを監視し、割り当てられたタスクの完了を支援します。 これらの各ワーカープロセスは、完全なトポロジのサブセットを実行します。

Stormアプリケーションには、基本的に、手元のタスクの実行を担当する4つのコンポーネント/抽象化があります。 これらは:
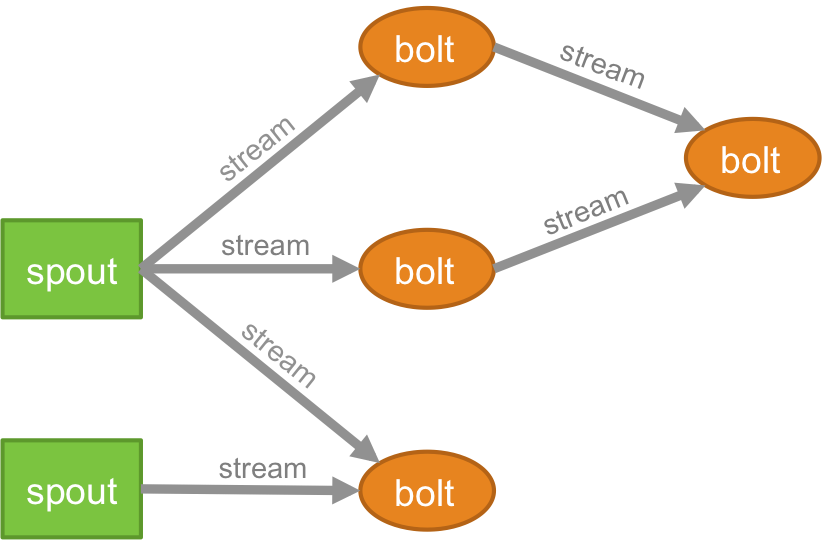
トポロジー
リアルタイムアプリケーションのロジックは、トポロジの形式でパッケージ化されています。これは、基本的にボルトと注ぎ口のネットワークです。 よりよく理解するために、それをMapReduceジョブと比較することができます(それが何であるかを知らない場合は、MapReduceに関する記事を読んでください!)。 主な違いの1つは、MapReduceジョブは実行が完了すると終了するのに対し、Stormトポロジは永久に実行されることです(明示的に自分で強制終了しない限り)。 ネットワークは、処理ロジックを形成するノードと、データの受け渡しとプロセスの実行を示すリンク(ストリームとも呼ばれます)で構成されます。
ストリーム
ストリームとは何かを理解する前に、タプルとは何かを理解する必要があります。 タプルは、Stormクラスターの主要なデータ構造です。 これらは値の名前付きリストであり、値は整数、ロング、ショート、バイト、ダブル、文字列、ブール値の浮動小数点数からバイト配列まで何でもかまいません。 現在、.streamsは、分散環境でリアルタイムに作成および処理される一連のタプルです。 これらは、Sparkクラスターのコア抽象化ユニットを形成します。
注ぎ口
スプラウトは、ストームタプルのストリームのソースです。 実際のデータソースと連絡を取り、データを継続的に受信し、それらのデータを実際のタプルストリームに変換し、最終的にボルトに送信して処理する責任があります。 信頼できる場合と信頼できない場合があります。 信頼できるスパウトは、ストームによる処理に失敗した場合にタプルを再生しますが、信頼できないスパウトは、タプルを発行した直後にタプルを忘れます。
ボルト
ボルトは、トポロジーのすべての処理を実行する責任があります。 これらは、Stormアプリケーションの処理ロジックユニットを形成します。 ボルトを利用して、フィルタリング、関数、結合、集計、データベースへの接続など、多くの重要な操作を実行できます。
誰がストームを使用しますか?
多数の強力で使いやすいツールがビッグデータの市場に存在していますが、Stormは、スローするプログラミング言語を処理できるため、そのリストの中でユニークな場所を見つけます。 多くの組織がStormを使用しています。
Apache Stormを使用している2、3のビッグプレーヤーとその方法を見てみましょう!
ツイッター

Twitterは、Stormを使用して、フィードのパーソナライズ、収益の最適化、検索結果の改善など、さまざまなシステムを強化しています。 TwitterはStorm(後にApacheに買収され、Apache Stormという名前)を開発したため、Twitterの他のインフラストラクチャ(データベースシステム(Cassandra、Memcachedなど)、メッセージング環境(Mesos)、監視システム)とシームレスに統合されます。 。
Spotify

Spotifyは、5,000万人を超えるアクティブユーザーと1,000万人のサブスクライバーに音楽をストリーミングすることで知られています。 これは、音楽の推奨、監視、分析、広告ターゲティング、プレイリストの作成など、幅広いリアルタイム機能を提供します。 この偉業を達成するために、SpotifyはApacheStormを利用しています。
Kafka、Memcached、およびnetty-zmtpベースのメッセージング環境とスタックされたApache Stormにより、Spotifyは低遅延のフォールトトレラント分散システムを簡単に構築できます。
まとめる…
ビッグデータアナリストとしてのキャリアを確立したい場合は、ストリーミングが最適です。 リアルタイムデータを扱う技術を習得できれば、アナリストの役割を採用する企業にとって一番の好みになります。 リアルタイムのデータ分析に飛び込むのにこれ以上の時間はありません。それは本当の意味での時間の必要性だからです。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。

世界のトップ大学からオンラインでソフトウェアエンジニアリングの学位を学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。