Tudo o que você precisa saber sobre o Apache Storm
Publicados: 2018-02-20O crescimento cada vez maior na produção e análise de Big Data continua apresentando novos desafios, e os cientistas de dados e programadores levam isso a sério – melhorando constantemente os aplicativos desenvolvidos por eles. Um desses problemas foi o de streaming em tempo real. Os dados em tempo real têm um valor extremamente alto para as empresas, mas têm uma janela de tempo após a qual perdem seu valor – uma data de expiração, se você preferir. Se o valor desses dados em tempo real não for percebido dentro da janela, nenhuma informação utilizável poderá ser extraída dela. Esses dados em tempo real chegam de forma rápida e contínua, daí o termo “Streaming”.
A análise desses dados em tempo real pode ajudá-lo a se manter atualizado sobre o que está acontecendo no momento, como o número de pessoas que lêem sua postagem no blog ou o número de pessoas que visitam sua página do Facebook. Embora possa parecer apenas um recurso “bom de se ter”, na prática, é essencial. Imagine que você faz parte de uma agência de publicidade realizando análises em tempo real em suas campanhas de anúncios – pelas quais o cliente pagou caro. A análise em tempo real pode mantê-lo informado sobre o desempenho do seu anúncio no mercado, como os usuários estão respondendo a ele e outras coisas dessa natureza. Uma ferramenta bastante essencial se você pensar dessa maneira, certo?
Observando o valor dos dados em tempo real, as organizações começaram a criar várias ferramentas de análise de dados em tempo real. Neste artigo, falaremos sobre um deles – Apache Storm. Veremos o que é, a arquitetura de um aplicativo de tempestade típico, seus componentes principais (também conhecidos como abstrações) e seus casos de uso na vida real.
Vamos lá!
Índice
O que é Apache Storm?

Apache Storm – lançado pelo Twitter, é um framework distribuído de código aberto que auxilia no processamento de dados em tempo real. O Apache Storm funciona para dados em tempo real, assim como o Hadoop funciona para processamento em lote de dados (processamento em lote é o oposto de tempo real. Neste, os dados são divididos em lotes e cada lote é processado. Isso não é feito em -Tempo.)
O Apache Storm não possui nenhum recurso de gerenciamento de estado e depende muito do Apache ZooKeeper (um serviço centralizado para gerenciar as configurações em aplicativos de Big Data) para gerenciar seu estado de cluster – coisas como reconhecimentos de mensagens, status de processamento e outras mensagens. O Apache Storm tem suas aplicações desenhadas na forma de grafos acíclicos direcionados. Ele é conhecido por processar mais de um milhão de tuplas por segundo por nó – o que é altamente escalável e fornece garantias de trabalho de processamento. Storm é escrito em Clojure, que é a primeira linguagem de programação funcional do tipo Lisp.

No coração do Apache Storm está uma “Definição de Thrift” para definir e enviar o gráfico lógico (também conhecido como topologias). Como o Thrift pode ser implementado em qualquer idioma de sua escolha, as topologias também podem ser criadas em qualquer idioma. Isso faz com que o Storm suporte uma infinidade de idiomas – tornando-o ainda mais amigável ao desenvolvedor.
O Storm é executado no YARN e se integra perfeitamente ao ecossistema Hadoop. É uma verdadeira estrutura de processamento de dados em tempo real com suporte a lote zero. É preciso um fluxo completo de dados como um 'evento' inteiro, em vez de dividi-lo em séries de pequenos lotes. Portanto, é mais adequado para dados que devem ser ingeridos como uma única entidade.
Vamos dar uma olhada na arquitetura geral de um aplicativo Storm – Ela lhe dará mais informações sobre como o Storm funciona!
Apache Storm: Arquitetura geral e componentes importantes
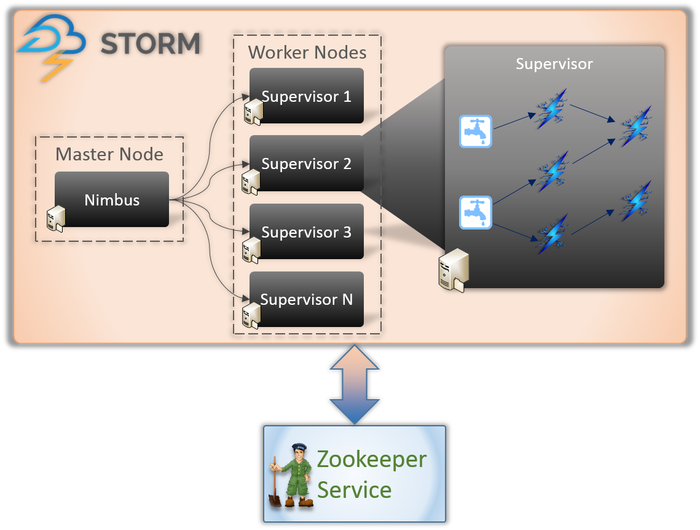
Existem essencialmente dois tipos de nós envolvidos em qualquer aplicativo Storm (como mostrado acima).
Nó Mestre (Serviço Nimbus)
Se você conhece o funcionamento interno do Hadoop, deve saber o que é um 'Job Tracker'. É um daemon que roda no nó mestre do Hadoop e é responsável por distribuir tarefas entre os nós. Nimbus é um tipo de serviço semelhante para Storm. Ele é executado no nó mestre de um cluster do Storm e é responsável por distribuir as tarefas entre os nós do trabalhador.
Nimbus é um serviço Thrift fornecido pelo Apache que permite que você envie seu código na linguagem de programação de sua escolha. Isso ajuda você a escrever seu aplicativo sem ter que aprender um novo idioma especificamente para o Storm.
Como falamos anteriormente, o Storm não possui recursos de gerenciamento de estado. O serviço Nimbus precisa contar com o ZooKeeper para monitorar as mensagens enviadas pelos nós do trabalhador durante o processamento das tarefas. Todos os nós do trabalhador atualizam seu status de tarefa no serviço ZooKeeper para que o Nimbus veja e monitore.
Nó do trabalhador (Serviço de supervisor)
Estes são os nós responsáveis pela execução das tarefas. Os nós de trabalho no Storm executam um serviço chamado Supervisor. O Supervisor é responsável por receber o trabalho atribuído a uma máquina pelo serviço Nimbus. Como o nome sugere, o Supervisor supervisiona os processos de trabalho e os ajuda a concluir as tarefas atribuídas. Cada um desses processos de trabalho executa um subconjunto da topologia completa.

Um aplicativo Storm tem essencialmente quatro componentes/abstrações que são responsáveis por executar as tarefas em questão. Estes são:
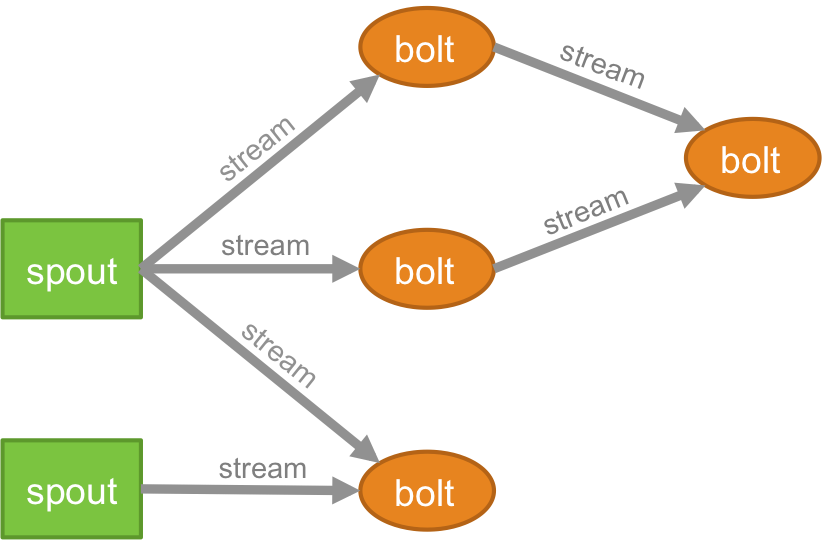
Topologia
A lógica para qualquer aplicação em tempo real é empacotada na forma de uma topologia – que é essencialmente uma rede de bolts e spouts. Para entender melhor, você pode compará-lo com os trabalhos do MapReduce (leia nosso artigo sobre MapReduce se você não sabe o que é isso!). Uma diferença importante é que o trabalho MapReduce termina quando sua execução é concluída, enquanto uma topologia Storm é executada para sempre (a menos que você a mate explicitamente). A rede consiste em nós que formam a lógica de processamento e links (também conhecidos como stream) que demonstram a passagem de dados e execução de processos.
Stream
Você precisa entender o que são tuplas antes de entender o que são streams. Tuplas são as principais estruturas de dados em um cluster Storm. Estas são listas nomeadas de valores onde os valores podem ser qualquer coisa de inteiros, longos, curtos, bytes, duplos, strings, floats booleanos, até arrays de bytes. Agora, .streams são uma sequência de tuplas que são criadas e processadas em tempo real em um ambiente distribuído. Eles formam a unidade de abstração principal de um cluster Spark.
Bico; esquichar
Um broto é a fonte de fluxos em uma tupla Storm. Ele é responsável por entrar em contato com a fonte de dados real, receber dados continuamente, transformar esses dados no fluxo real de tuplas e, finalmente, enviá-los para os bolts para serem processados. Pode ser confiável ou não confiável. Um Spout confiável irá reproduzir a tupla se ela não for processada pelo Storm, um Spout não confiável, por outro lado, esquecerá a tupla logo após a emissão.
Parafuso
Os parafusos são responsáveis por realizar todo o processamento da topologia. Eles formam a unidade lógica de processamento de um aplicativo Storm. Pode-se utilizar o bolt para realizar muitas operações essenciais, como filtragem, funções, junções, agregações, conexão com bancos de dados e muito mais.
Quem usa tempestade?
Embora uma série de ferramentas poderosas e fáceis de usar estejam presentes no mercado de Big Data, o Storm encontra um lugar único nessa lista devido à sua capacidade de lidar com qualquer linguagem de programação que você usar. Muitas organizações usam o Storm.
Vejamos alguns grandes jogadores que usam o Apache Storm e como!
Twitter

O Twitter usa o Storm para alimentar uma variedade de seus sistemas – desde a personalização de seu feed, otimização de receita, até a melhoria dos resultados de pesquisa e outros processos semelhantes. Como o Twitter desenvolveu o Storm (que mais tarde foi comprado pela Apache e chamado Apache Storm), ele se integra perfeitamente com o restante da infraestrutura do Twitter – os sistemas de banco de dados (Cassandra, Memcached etc.), o ambiente de mensagens (Mesos) e os sistemas de monitoramento .
Spotify

O Spotify é conhecido por transmitir música para mais de 50 milhões de usuários ativos e 10 milhões de assinantes. Ele fornece uma ampla gama de recursos em tempo real, como recomendação de música, monitoramento, análise, segmentação de anúncios e criação de playlists. Para conseguir esse feito, o Spotify utiliza o Apache Storm.
Empilhado com ambiente de mensagens baseado em Kafka, Memcached e netty-zmtp, o Apache Storm permite que o Spotify crie facilmente sistemas distribuídos tolerantes a falhas de baixa latência.
Para encerrar…
Se você deseja estabelecer sua carreira como analista de Big Data, o streaming é o caminho a percorrer. Se você for capaz de dominar a arte de lidar com dados em tempo real, será a preferência número um das empresas que contratam para uma função de analista. Não poderia haver um momento melhor para mergulhar na análise de dados em tempo real, porque essa é a necessidade da hora no sentido mais verdadeiro!
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.

Aprenda os graus de Engenharia de Software online das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.