Todo lo que necesitas saber sobre Apache Storm
Publicado: 2018-02-20El crecimiento cada vez mayor en la producción y el análisis de Big Data sigue presentando nuevos desafíos, y los científicos y programadores de datos lo toman con calma, mejorando constantemente las aplicaciones desarrolladas por ellos. Uno de esos problemas era el de la transmisión en tiempo real. Los datos en tiempo real tienen un valor extremadamente alto para las empresas, pero tienen una ventana de tiempo después de la cual pierden su valor, una fecha de caducidad, por así decirlo. Si el valor de estos datos en tiempo real no se realiza dentro de la ventana, no se puede extraer información útil de ella. Estos datos en tiempo real llegan de forma rápida y continua, de ahí el término "Streaming".
El análisis de estos datos en tiempo real puede ayudarlo a mantenerse actualizado sobre lo que está sucediendo en este momento, como la cantidad de personas que leen la publicación de su blog o la cantidad de personas que visitan su página de Facebook. Aunque puede sonar como una característica "agradable de tener", en la práctica, es esencial. Imagine que es parte de una agencia de publicidad que realiza análisis en tiempo real en sus campañas publicitarias, por lo que el cliente pagó mucho. Los análisis en tiempo real pueden mantenerlo informado sobre el rendimiento de su anuncio en el mercado, cómo responden los usuarios y otras cosas de esa naturaleza. Una herramienta bastante esencial si lo piensas de esta manera, ¿verdad?
Al observar el valor que tienen los datos en tiempo real, las organizaciones comenzaron a idear varias herramientas de análisis de datos en tiempo real. En este artículo, hablaremos de uno de ellos: Apache Storm. Veremos qué es, la arquitectura de una aplicación de tormenta típica, sus componentes principales (también conocidos como abstracciones) y sus casos de uso de la vida real.
¡Vamos!
Tabla de contenido
¿Qué es Apache Storm?

Apache Storm: lanzado por Twitter, es un marco de código abierto distribuido que ayuda en el procesamiento de datos en tiempo real. Apache Storm funciona para datos en tiempo real al igual que Hadoop funciona para el procesamiento por lotes de datos (el procesamiento por lotes es lo opuesto al tiempo real. En esto, los datos se dividen en lotes y cada lote se procesa. Esto no se hace en tiempo real). -hora.)
Apache Storm no tiene capacidades de administración de estado y depende en gran medida de Apache ZooKeeper (un servicio centralizado para administrar las configuraciones en aplicaciones de Big Data) para administrar el estado de su clúster, como reconocimientos de mensajes, estados de procesamiento y otros mensajes similares. Apache Storm tiene sus aplicaciones diseñadas en forma de grafos acíclicos dirigidos. Es conocido por procesar más de un millón de tuplas por segundo por nodo, que es altamente escalable y proporciona garantías de trabajo de procesamiento. Storm está escrito en Clojure, que es el primer lenguaje de programación funcional similar a Lisp.

En el corazón de Apache Storm hay una "Definición de Thrift" para definir y enviar el gráfico lógico (también conocido como topologías). Dado que Thrift se puede implementar en cualquier idioma de su elección, las topologías también se pueden crear en cualquier idioma. Esto hace que Storm admita una multitud de idiomas, lo que lo hace aún más amigable para los desarrolladores.
Storm se ejecuta en YARN y se integra perfectamente con el ecosistema Hadoop. Es un verdadero marco de procesamiento de datos en tiempo real que no admite lotes. Toma un flujo completo de datos como un "evento" completo en lugar de dividirlo en una serie de pequeños lotes. Por lo tanto, es más adecuado para los datos que se van a ingerir como una sola entidad.
Echemos un vistazo a la arquitectura general de una aplicación Storm. ¡Le dará más información sobre cómo funciona Storm!
Apache Storm: arquitectura general y componentes importantes
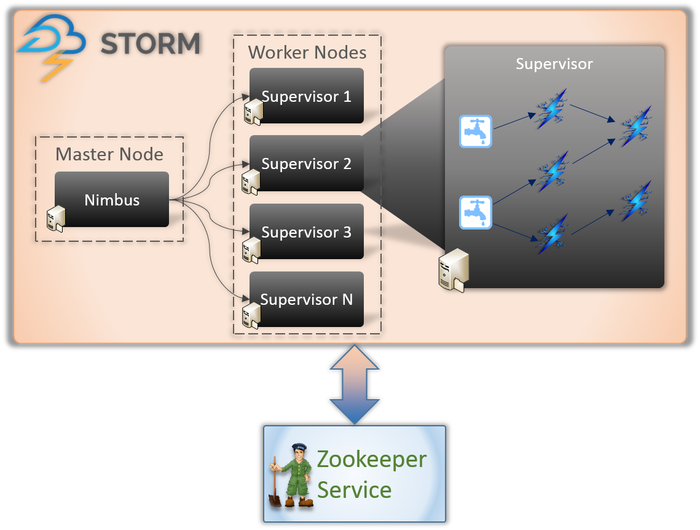
Hay esencialmente dos tipos de nodos involucrados en cualquier aplicación Storm (como se muestra arriba).
Nodo maestro (Servicio Nimbus)
Si conoce el funcionamiento interno de Hadoop, debe saber qué es un 'Rastreador de trabajos'. Es un demonio que se ejecuta en el nodo maestro de Hadoop y es responsable de distribuir tareas entre los nodos. Nimbus es un tipo de servicio similar para Storm. Se ejecuta en el nodo maestro de un clúster Storm y es responsable de distribuir las tareas entre los nodos trabajadores.
Nimbus es un servicio Thrift proporcionado por Apache que le permite enviar su código en el lenguaje de programación de su elección. Esto lo ayuda a escribir su aplicación sin tener que aprender un nuevo idioma específicamente para Storm.
Como hablamos anteriormente, Storm carece de capacidades de gestión de estado. El servicio Nimbus tiene que depender de ZooKeeper para monitorear los mensajes que envían los nodos trabajadores mientras procesan las tareas. Todos los nodos trabajadores actualizan el estado de sus tareas en el servicio ZooKeeper para que Nimbus los vea y supervise.

Nodo Trabajador (Servicio de Supervisor)
Estos son los nodos responsables de realizar las tareas. Los nodos trabajadores en Storm ejecutan un servicio llamado Supervisor. El Supervisor es responsable de recibir el trabajo asignado a una máquina por el servicio Nimbus. Como sugiere el nombre, Supervisor supervisa los procesos de los trabajadores y los ayuda a completar las tareas asignadas. Cada uno de estos procesos de trabajo ejecuta un subconjunto de la topología completa.
Una aplicación Storm tiene esencialmente cuatro componentes/abstracciones que son responsables de realizar las tareas en cuestión. Estos son:
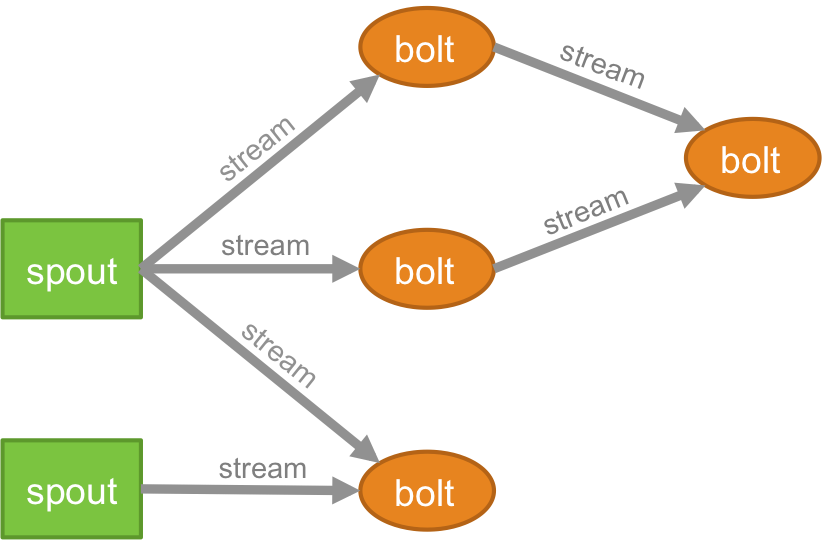
Topología
La lógica para cualquier aplicación en tiempo real se empaqueta en forma de topología, que es esencialmente una red de pernos y picos. Para comprenderlo mejor, puede compararlo con los trabajos de MapReduce (lea nuestro artículo sobre MapReduce si no sabe de qué se trata). Una diferencia clave es que el trabajo de MapReduce finaliza cuando se completa su ejecución, mientras que una topología de Storm se ejecuta para siempre (a menos que usted mismo lo elimine explícitamente). La red consta de nodos que forman la lógica de procesamiento y enlaces (también conocidos como flujo) que demuestran el paso de datos y la ejecución de procesos.
Arroyo
Debe comprender qué son las tuplas antes de comprender qué son los flujos. Las tuplas son las principales estructuras de datos en un clúster Storm. Estas son listas de valores con nombre donde los valores pueden ser cualquier cosa, desde enteros, largos, cortos, bytes, dobles, cadenas, booleanos flotantes, hasta matrices de bytes. Ahora, los flujos son una secuencia de tuplas que se crean y procesan en tiempo real en un entorno distribuido. Forman la unidad central de abstracción de un clúster Spark.
Canalón
Un brote es la fuente de flujos en una tupla Storm. Es responsable de ponerse en contacto con la fuente de datos real, recibir datos continuamente, transformar esos datos en el flujo real de tuplas y finalmente enviarlos a los tornillos para que sean procesados. Puede ser confiable o no confiable. Un Spout fiable reproducirá la tupla si Storm no la procesa, mientras que un Spout poco fiable se olvidará de la tupla poco después de emitirla.
Tornillo
Los pernos son los encargados de realizar todo el procesamiento de la topología. Forman la unidad lógica de procesamiento de una aplicación Storm. Uno puede utilizar bolt para realizar muchas operaciones esenciales como filtrado, funciones, uniones, agregaciones, conexión a bases de datos y muchas más.
¿Quién usa Tormenta?
Aunque varias herramientas poderosas y fáciles de usar tienen su presencia en el mercado de Big Data, Storm encuentra un lugar único en esa lista debido a su capacidad para manejar cualquier lenguaje de programación que le presente. Muchas organizaciones utilizan Storm.
¡Veamos un par de grandes jugadores que usan Apache Storm y cómo!
Gorjeo

Twitter utiliza Storm para impulsar una variedad de sus sistemas, desde la personalización de su feed, la optimización de ingresos, hasta la mejora de los resultados de búsqueda y otros procesos similares. Debido a que Twitter desarrolló Storm (que luego fue comprado por Apache y llamado Apache Storm), se integra a la perfección con el resto de la infraestructura de Twitter: los sistemas de base de datos (Cassandra, Memcached, etc.), el entorno de mensajería (Mesos) y los sistemas de monitoreo. .
Spotify

Spotify es conocido por transmitir música a más de 50 millones de usuarios activos y 10 millones de suscriptores. Proporciona una amplia gama de funciones en tiempo real como recomendación de música, monitoreo, análisis, orientación de anuncios y creación de listas de reproducción. Para lograr esta hazaña, Spotify utiliza Apache Storm.
Apilado con el entorno de mensajería basado en Kafka, Memcached y netty-zmtp, Apache Storm permite a Spotify crear fácilmente sistemas distribuidos tolerantes a fallas de baja latencia.
Para concluir…
Si desea establecer su carrera como analista de Big Data, la transmisión es el camino a seguir. Si puede dominar el arte de manejar datos en tiempo real, será la preferencia número uno para las empresas que contratan para un puesto de analista. ¡No podría haber un mejor momento para sumergirse en el análisis de datos en tiempo real porque esa es la necesidad del momento en el sentido más verdadero!
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.

Aprenda títulos de ingeniería de software en línea de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.