Semua yang Perlu Anda Ketahui tentang Apache Storm
Diterbitkan: 2018-02-20Pertumbuhan yang terus meningkat dalam produksi dan analitik Big Data terus menghadirkan tantangan baru, dan para ilmuwan data dan pemrogram dengan anggun mengambil langkah mereka – dengan terus meningkatkan aplikasi yang dikembangkan oleh mereka. Salah satu masalah tersebut adalah streaming real-time. Data real-time memiliki nilai yang sangat tinggi untuk bisnis, tetapi memiliki jendela waktu setelah itu kehilangan nilainya – tanggal kedaluwarsa, jika Anda mau. Jika nilai data real-time ini tidak direalisasikan di dalam jendela, tidak ada informasi yang dapat digunakan yang dapat diekstraksi darinya. Data real-time ini masuk dengan cepat dan terus menerus, oleh karena itu istilah “Streaming”.
Analisis data waktu nyata ini dapat membantu Anda tetap mengetahui apa yang terjadi saat ini, seperti jumlah orang yang membaca posting blog Anda, atau jumlah orang yang mengunjungi halaman Facebook Anda. Meskipun mungkin terdengar seperti fitur yang "bagus untuk dimiliki", dalam praktiknya, Ini penting. Bayangkan Anda adalah bagian dari Biro Iklan yang melakukan analisis waktu nyata pada kampanye iklan Anda – yang dibayar mahal oleh klien. Analitik real-time dapat membuat Anda tetap diposting tentang bagaimana kinerja Iklan Anda di pasar, bagaimana pengguna meresponsnya, dan hal-hal lain semacam itu. Alat yang cukup penting jika Anda memikirkannya seperti ini, bukan?
Melihat nilai yang dimiliki data real-time, organisasi mulai datang dengan berbagai alat analisis data real-time. Pada artikel ini, kita akan berbicara tentang salah satunya – Apache Storm. Kita akan melihat apa itu, arsitektur aplikasi badai yang khas, komponen intinya (juga dikenal sebagai abstraksi), dan kasus penggunaan nyatanya.
Ayo pergi!
Daftar isi
Apa itu Apache Storm?

Apache Storm – dirilis oleh Twitter, adalah framework open-source terdistribusi yang membantu pemrosesan data secara real-time. Apache Storm bekerja untuk data real-time seperti Hadoop bekerja untuk pemrosesan batch data (Pemrosesan batch adalah kebalikan dari real-time. Dalam hal ini, data dibagi menjadi batch, dan setiap batch diproses. Ini tidak dilakukan secara nyata -waktu.)
Apache Storm tidak memiliki kemampuan pengelolaan status dan sangat bergantung pada Apache ZooKeeper (layanan terpusat untuk mengelola konfigurasi dalam aplikasi Big Data) untuk mengelola status klasternya – hal-hal seperti pengakuan pesan, status pemrosesan, dan pesan sejenis lainnya. Apache Storm memiliki aplikasi yang dirancang dalam bentuk grafik asiklik terarah. Ia dikenal untuk memproses lebih dari satu juta tupel per detik per node – yang sangat skalabel dan memberikan jaminan pekerjaan pemrosesan. Storm ditulis dalam Clojure yang merupakan bahasa pemrograman fungsional-pertama seperti Lisp.

Di jantung Apache Storm adalah "Definisi Hemat" untuk mendefinisikan dan mengirimkan grafik logika (juga dikenal sebagai topologi). Karena Hemat dapat diimplementasikan dalam bahasa apa pun pilihan Anda, topologi juga dapat dibuat dalam bahasa apa pun. Ini membuat Storm mendukung banyak bahasa – menjadikannya lebih ramah pengembang.
Storm berjalan di YARN dan terintegrasi sempurna dengan ekosistem Hadoop. Ini adalah kerangka kerja pemrosesan data real-time yang benar-benar memiliki dukungan batch nol. Dibutuhkan aliran data yang lengkap sebagai keseluruhan 'peristiwa' alih-alih memecahnya menjadi serangkaian kumpulan kecil. Oleh karena itu, ini paling cocok untuk data yang akan diserap sebagai satu entitas.
Mari kita lihat arsitektur umum aplikasi Storm – Ini akan memberi Anda lebih banyak wawasan tentang cara kerja Storm!
Apache Storm: Arsitektur Umum dan Komponen Penting
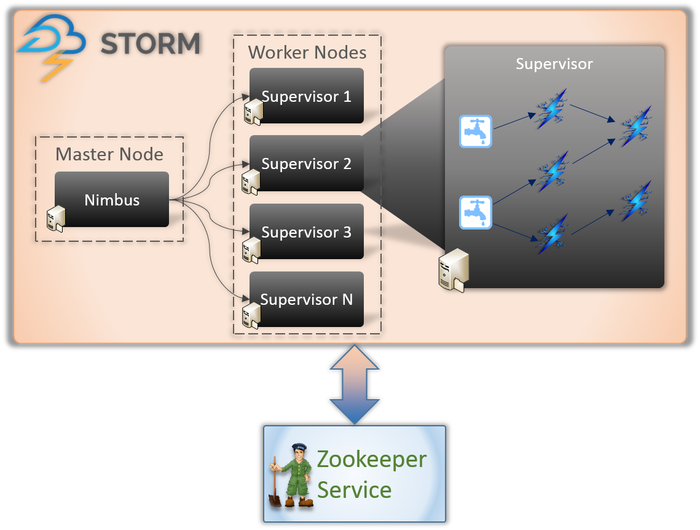
Pada dasarnya ada dua jenis node yang terlibat dalam aplikasi Storm (seperti yang ditunjukkan di atas).
Node Master (Layanan Nimbus)
Jika Anda mengetahui cara kerja Hadoop, Anda pasti tahu apa itu 'Pelacak Pekerjaan'. Ini adalah daemon yang berjalan di node Master Hadoop dan bertanggung jawab untuk mendistribusikan tugas di antara node. Nimbus adalah layanan serupa untuk Storm. Ini berjalan di Master Node dari cluster Storm dan bertanggung jawab untuk mendistribusikan tugas di antara node pekerja.
Nimbus adalah layanan Hemat yang disediakan oleh Apache yang memungkinkan Anda untuk mengirimkan kode Anda dalam bahasa pemrograman pilihan Anda. Ini membantu Anda menulis aplikasi tanpa harus mempelajari bahasa baru khusus untuk Storm.
Seperti yang kita bicarakan sebelumnya, Storm tidak memiliki kemampuan mengelola status. Layanan Nimbus harus mengandalkan ZooKeeper untuk memantau pesan yang dikirim oleh node pekerja saat memproses tugas. Semua node pekerja memperbarui status tugas mereka di layanan ZooKeeper untuk dilihat dan dipantau Nimbus.
Node Pekerja (Layanan Supervisor)
Ini adalah node yang bertanggung jawab untuk melakukan tugas. Node pekerja di Storm menjalankan layanan yang disebut Supervisor. Supervisor bertanggung jawab untuk menerima pekerjaan yang ditugaskan ke mesin oleh layanan Nimbus. Seperti namanya, Supervisor mengawasi proses pekerja dan membantu mereka menyelesaikan tugas yang diberikan. Masing-masing proses pekerja ini mengeksekusi subset dari topologi lengkap.

Aplikasi Storm pada dasarnya memiliki empat komponen/abstraksi yang bertanggung jawab untuk melakukan tugas yang ada. Ini adalah:
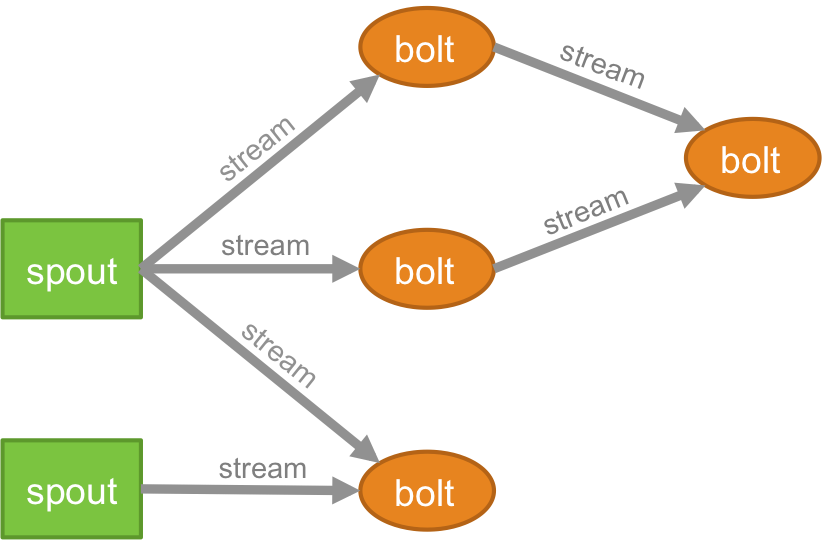
Topologi
Logika untuk aplikasi waktu nyata apa pun dikemas dalam bentuk topologi – yang pada dasarnya adalah jaringan baut dan cerat. Untuk memahami lebih baik, Anda dapat membandingkannya dengan pekerjaan MapReduce (baca artikel kami di MapReduce jika Anda tidak mengetahui apa itu!). Satu perbedaan utama adalah bahwa pekerjaan MapReduce selesai ketika eksekusinya selesai, sedangkan topologi Storm berjalan selamanya (kecuali jika Anda secara eksplisit membunuhnya sendiri). Jaringan terdiri dari node yang membentuk logika pemrosesan, dan link (juga dikenal sebagai aliran) yang menunjukkan lewatnya data dan eksekusi proses.
Sungai kecil
Anda perlu memahami apa itu tupel sebelum memahami apa itu stream. Tuple adalah struktur data utama dalam cluster Storm. Ini diberi nama daftar nilai di mana nilainya bisa apa saja mulai dari bilangan bulat, panjang, pendek, byte, ganda, string, boolean float, hingga array byte. Sekarang,.stream adalah urutan tupel yang dibuat dan diproses secara real-time dalam lingkungan terdistribusi. Mereka membentuk unit abstraksi inti dari cluster Spark.
Menyemburkan
Tunas adalah sumber aliran dalam tupel Storm. Ini bertanggung jawab untuk berhubungan dengan sumber data aktual, menerima data secara terus menerus, mengubah data tersebut menjadi aliran tupel yang sebenarnya dan akhirnya mengirimkannya ke baut untuk diproses. Itu bisa diandalkan atau tidak bisa diandalkan. Spout yang andal akan memutar ulang tuple jika gagal diproses oleh Storm, Spout yang tidak dapat diandalkan, di sisi lain, akan melupakan tuple segera setelah memancarkannya.
Baut
Baut bertanggung jawab untuk melakukan semua pemrosesan topologi. Mereka membentuk unit logika pemrosesan dari aplikasi Storm. Seseorang dapat menggunakan baut untuk melakukan banyak operasi penting seperti pemfilteran, fungsi, penggabungan, agregasi, koneksi ke database, dan banyak lagi.
Siapa yang Menggunakan Badai?
Meskipun sejumlah alat yang kuat dan mudah digunakan hadir di pasar Big Data, Storm menemukan tempat unik dalam daftar itu karena kemampuannya untuk menangani bahasa pemrograman apa pun yang Anda gunakan. Banyak organisasi menggunakan Storm.
Mari kita lihat beberapa pemain besar yang menggunakan Apache Storm dan bagaimana caranya!
Indonesia

Twitter menggunakan Storm untuk memberi daya pada berbagai sistemnya – mulai dari personalisasi feed Anda, pengoptimalan pendapatan, hingga peningkatan hasil pencarian dan proses serupa lainnya. Karena Twitter mengembangkan Storm (yang kemudian dibeli oleh Apache dan diberi nama Apache Storm), ia terintegrasi secara mulus dengan infrastruktur Twitter lainnya – sistem basis data (Cassandra, Memcached, dll.), lingkungan pengiriman pesan (Mesos), dan sistem pemantauan. .
Spotify

Spotify dikenal untuk streaming musik ke lebih dari 50 juta pengguna aktif dan 10 juta pelanggan. Ini menyediakan berbagai fitur waktu nyata seperti rekomendasi musik, pemantauan, analitik, penargetan iklan, dan pembuatan daftar putar. Untuk mencapai prestasi ini, Spotify menggunakan Apache Storm.
Ditumpuk dengan lingkungan perpesanan berbasis Kafka, Memcached, dan netty-zmtp, Apache Storm memungkinkan Spotify membangun sistem terdistribusi yang toleran terhadap kesalahan latensi rendah dengan mudah.
Untuk Mengakhiri…
Jika Anda ingin membangun karir Anda sebagai analis Big Data, streaming adalah cara yang harus dilakukan. Jika Anda mampu menguasai seni menangani data real-time, Anda akan menjadi pilihan nomor satu bagi perusahaan yang mempekerjakan peran analis. Tidak ada waktu yang lebih baik untuk menyelami analitik data waktu nyata karena itulah kebutuhan saat ini dalam arti yang sebenarnya!
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.

Pelajari gelar Rekayasa Perangkat Lunak secara online dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.