关于 Apache Storm 你需要知道的一切
已发表: 2018-02-20大数据生产和分析的不断增长不断提出新的挑战,数据科学家和程序员通过不断改进他们开发的应用程序,优雅地从容应对。 一个这样的问题是实时流。 实时数据对企业具有极高的价值,但它有一个时间窗口,在此之后它就会失去价值——如果你愿意的话,还有一个到期日。 如果这个实时数据的价值没有在窗口内实现,就不能从中提取任何有用的信息。 这种实时数据快速而连续地进入,因此称为“流式传输”。
对这些实时数据的分析可以帮助您及时了解当前正在发生的事情,例如阅读您的博客文章的人数,或访问您的 Facebook 页面的人数。 虽然它可能听起来只是一个“不错的”功能,但在实践中,它是必不可少的。 想象一下,您是一家广告公司的一员,对您的广告活动进行实时分析——客户为此付出了高昂的代价。 实时分析可以让您随时了解您的广告在市场上的表现如何、用户对其的反应以及其他类似的事情。 如果您这样想的话,这是一个非常重要的工具,对吧?
着眼于实时数据所具有的价值,组织开始提出各种实时数据分析工具。 在本文中,我们将讨论其中之一——Apache Storm。 我们将看看它是什么,一个典型的 Storm 应用程序的架构,它的核心组件(也称为抽象),以及它的真实生活用例。
我们走吧!
目录
什么是阿帕奇风暴?

Apache Storm – 由 Twitter 发布,是一个分布式开源框架,有助于实时处理数据。 Apache Storm 处理实时数据,就像 Hadoop 处理数据批处理一样(批处理与实时相反。在这里,数据被分成批处理,每个批处理都被处理。这不是真正的-时间。)
Apache Storm 没有任何状态管理功能,并且严重依赖 Apache ZooKeeper(用于管理大数据应用程序中的配置的集中服务)来管理其集群状态——例如消息确认、处理状态和其他此类消息。 Apache Storm 的应用程序以有向无环图的形式设计。 它以每个节点每秒处理超过一百万个元组而闻名 - 这是高度可扩展的并提供处理作业保证。 Storm 是用 Clojure 编写的,它是一种类似 Lisp 的函数式优先编程语言。

Apache Storm 的核心是用于定义和提交逻辑图(也称为拓扑)的“Thrift 定义”。 由于 Thrift 可以用您选择的任何语言实现,因此也可以用任何语言创建拓扑。 这使得 Storm 支持多种语言 - 使其对开发人员更加友好。
Storm 在 YARN 上运行,并与 Hadoop 生态系统完美集成。 它是一个真正的实时数据处理框架,支持零批处理。 它将完整的数据流作为一个完整的“事件”,而不是将其分成一系列小批量。 因此,它最适合作为单个实体摄取的数据。
让我们看一下 Storm 应用程序的一般架构——它将让您更深入地了解 Storm 的工作原理!
Apache Storm:通用架构和重要组件
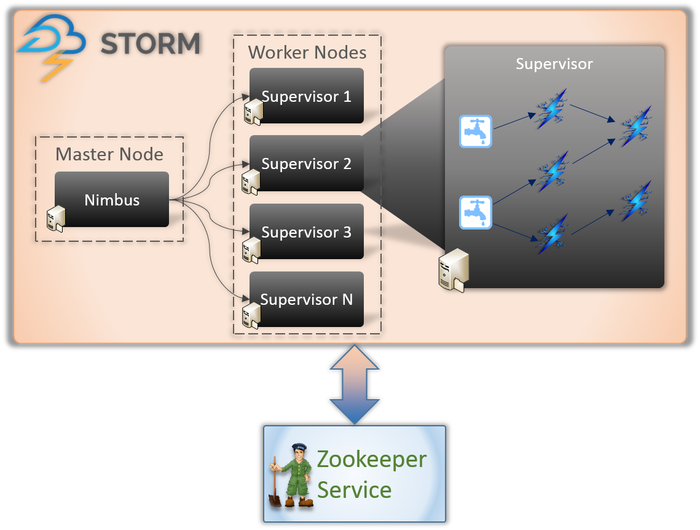
任何 Storm 应用程序都涉及两种类型的节点(如上所示)。
主节点(Nimbus 服务)
如果您了解 Hadoop 的内部工作原理,那么您必须知道什么是“作业跟踪器”。 它是运行在 Hadoop 的 Master 节点上的守护进程,负责在节点之间分配任务。 Nimbus 是 Storm 的一种类似服务。 它运行在 Storm 集群的主节点上,负责在工作节点之间分配任务。
Nimbus 是 Apache 提供的 Thrift 服务,它允许您以您选择的编程语言提交代码。 这可以帮助您编写应用程序,而无需学习专门针对 Storm 的新语言。
正如我们之前所说,Storm 缺乏任何状态管理功能。 Nimbus 服务必须依靠 ZooKeeper 来监控工作节点在处理任务时发送的消息。 所有工作节点都会在 ZooKeeper 服务中更新其任务状态,以供 Nimbus 查看和监控。
工作节点(主管服务)
这些是负责执行任务的节点。 Storm 中的工作节点运行一个名为 Supervisor 的服务。 Supervisor 负责接收 Nimbus 服务分配给机器的工作。 顾名思义,Supervisor 监督工作进程并帮助他们完成分配的任务。 这些工作进程中的每一个都执行完整拓扑的一个子集。

Storm 应用程序本质上具有四个组件/抽象,它们负责执行手头的任务。 这些是:
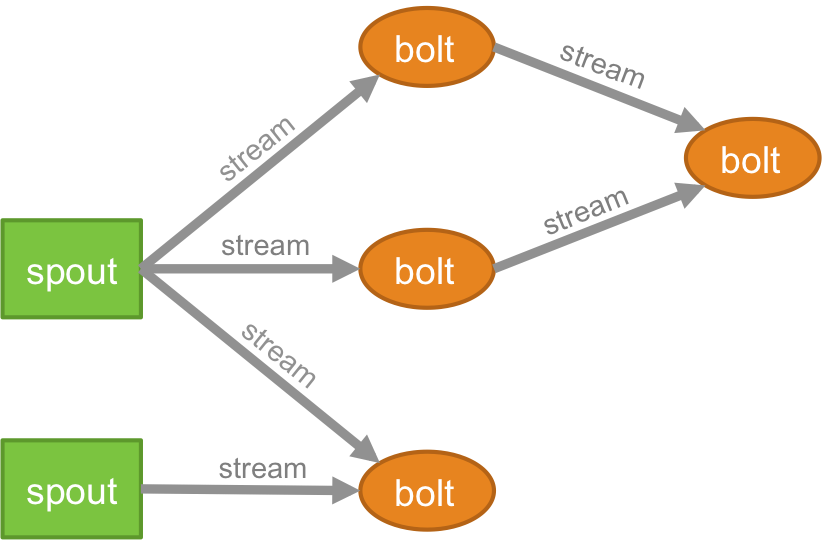
拓扑
任何实时应用程序的逻辑都以拓扑的形式打包——本质上是一个螺栓和喷口的网络。 为了更好地理解,您可以将其与 MapReduce 作业进行比较(如果您不知道那是什么,请阅读我们关于 MapReduce 的文章!)。 一个关键的区别是 MapReduce 作业在其执行完成时完成,而 Storm 拓扑将永远运行(除非您自己明确地杀死它)。 网络由形成处理逻辑的节点和演示数据传递和流程执行的链接(也称为流)组成。
溪流
在了解什么是流之前,您需要了解什么是元组。 元组是 Storm 集群中的主要数据结构。 这些是命名的值列表,其中值可以是从整数、长整数、短整数、字节、双精度、字符串、布尔浮点数到字节数组的任何值。 现在,.streams 是在分布式环境中实时创建和处理的元组序列。 它们构成了 Spark 集群的核心抽象单元。
喷口
新芽是 Storm 元组中流的来源。 它负责与实际的数据源取得联系,不断地接收数据,将这些数据转换成实际的元组流,最后发送到bolts进行处理。 它可以是可靠的,也可以是不可靠的。 如果 Storm 处理失败,可靠的 Spout 将重播该元组,另一方面,不可靠的 Spout 将在发出元组后很快忘记该元组。
螺栓
螺栓负责执行拓扑的所有处理。 它们构成了 Storm 应用程序的处理逻辑单元。 可以利用 Bolt 执行许多基本操作,例如过滤、函数、连接、聚合、连接到数据库等等。
谁使用风暴?
尽管在大数据市场中出现了许多功能强大且易于使用的工具,但 Storm 在该列表中找到了一个独特的位置,因为它能够处理您扔给它的任何编程语言。 许多组织使用 Storm。
让我们看看几个使用 Apache Storm 的大玩家以及如何使用它!
推特

Twitter 使用 Storm 为其各种系统提供动力——从您的订阅源的个性化、收入优化到改进搜索结果和其他此类流程。 由于 Twitter 开发了 Storm(后来被 Apache 收购并命名为 Apache Storm),它与 Twitter 的其他基础设施——数据库系统(Cassandra、Memcached 等)、消息传递环境(Mesos)和监控系统无缝集成.
Spotify

Spotify 以向超过 5000 万活跃用户和 1000 万订阅者提供流媒体音乐而闻名。 它提供了广泛的实时功能,如音乐推荐、监控、分析、广告定位和播放列表创建。 为了实现这一壮举,Spotify 使用了 Apache Storm。
Apache Storm 与基于 Kafka、Memcached 和 netty-zmtp 的消息传递环境堆叠在一起,使 Spotify 能够轻松构建低延迟容错分布式系统。
总结…
如果您希望建立自己的大数据分析师职业生涯,那么流媒体是您的最佳选择。 如果您能够掌握处理实时数据的艺术,那么您将成为招聘分析师职位的公司的第一选择。 现在是深入研究实时数据分析的最佳时机,因为这是真正意义上的小时需求!
如果您有兴趣了解有关大数据的更多信息,请查看我们的 PG 大数据软件开发专业文凭课程,该课程专为在职专业人士设计,提供 7 多个案例研究和项目,涵盖 14 种编程语言和工具,实用的动手操作研讨会,超过 400 小时的严格学习和顶级公司的就业帮助。

从世界顶级大学在线学习软件工程学位。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。