
机器学习中的 K-Nearest Neighbors 算法 [附示例]
已发表: 2020-10-28目录
介绍
机器学习无疑是当今数据驱动的世界中最流行和最强大的技术之一,我们每秒钟都在收集更多的数据。 这是快速发展的技术之一,每个领域和每个部门都有自己的用例和项目。
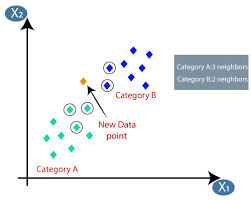
机器学习或模型开发是数据科学项目生命周期中的阶段之一,这似乎也是最重要的阶段之一。 本文旨在介绍机器学习中的 KNN(K-Nearest Neighbors)。
K-最近邻
如果您熟悉机器学习或者曾经是数据科学或 AI 团队的一员,那么您可能听说过 k-最近邻算法,或者简称为 KNN。 该算法是机器学习中常用的算法之一,因为它易于实现、非参数、惰性学习并且计算时间短。
k-Nearest Neighbors 算法的另一个优点是它可以用于分类和回归类型的问题。 如果您不知道这两者之间的区别,那么让我向您说明,分类和回归之间的主要区别在于回归中的输出变量是数值(连续),而分类输出变量是分类(离散)。
阅读: R 中的 KNN 算法
k-最近邻是如何工作的?
K-最近邻(KNN)算法使用“特征相似性”或“最近邻”技术来预测新数据点落入的集群。 以下是我们可以更好地理解该算法的工作的几个步骤

第 1 步-为了在机器学习中实现任何算法,我们需要准备好用于建模的清洁数据集。 假设我们已经有一个清理过的数据集,该数据集已分为训练和测试数据集。
第 2 步-由于我们已经准备好数据集,我们需要选择 K(整数)的值,它告诉我们需要考虑多少最近的数据点来实现算法。 我们可以在文章的后期了解如何确定k值。
Step 3 -此步骤是一个迭代步骤,需要应用于数据集中的每个数据点
I. 使用任意距离度量计算测试数据与每行训练数据之间的距离
一种。 欧几里得距离
湾。 曼哈顿距离
C。 闵可夫斯基距离
d。 汉明距离。
许多数据科学家倾向于使用欧几里得距离,但我们可以在本文的后期了解每一个的意义。
二、 我们需要根据我们在上述步骤中使用的距离度量对数据进行排序。
三、 选择转换后的排序数据中的前 K 行。
四。 然后它将根据这些行中最常见的类为测试点分配一个类。
第 4 步-结束
如何确定K值?
我们需要选择一个合适的 K 值来达到模型的最大精度,但是没有预先定义的统计方法来找到最有利的 K 值。但大多数使用肘部方法。
肘部方法首先计算某些 k 值的平方误差和 (SSE)。 SSE 是集群的每个成员与其质心之间的平方距离之和。
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
如果根据 SSE 绘制不同的 k 值,我们可以看到随着 k 的值变大,误差会减小,这是因为当聚类数量增加时,聚类会趋于变小,因此失真也会变小. 肘部法的思想是选择 SSE 突然下降的 k 值,表示肘部的形状。
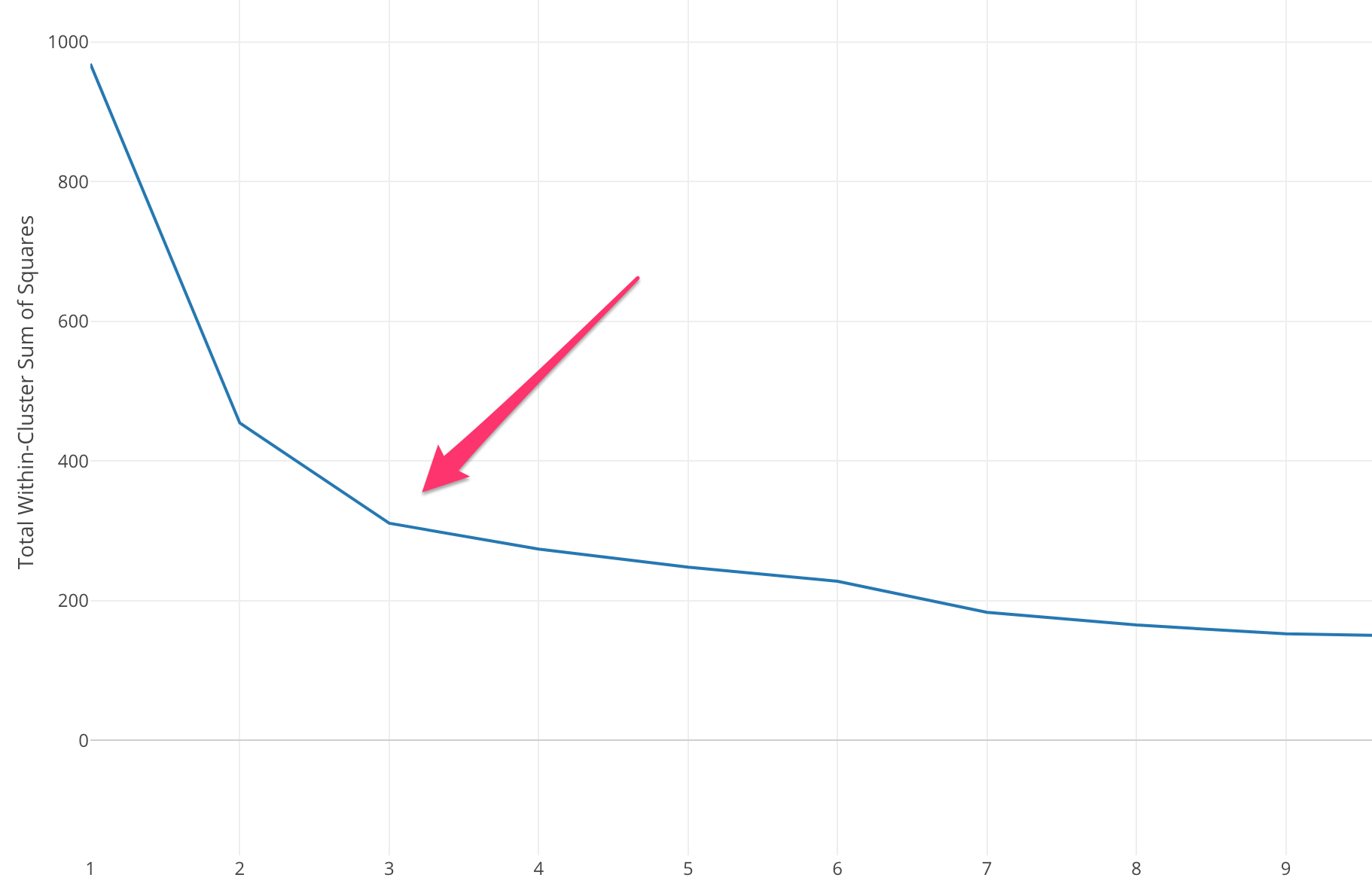
在某些情况下,有不止一个肘部,或者根本没有肘部。 在这种情况下,我们通常通过评估 k-means ML 算法在您尝试解决的问题的上下文中的执行情况来计算最佳 k。

另请阅读:机器学习模型
距离度量的类型
让我们一一了解用于计算两个数据点之间距离的不同距离度量。
1.欧几里得距离——欧几里得距离是两点间距离平方和的平方根。
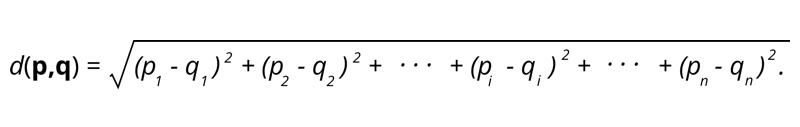 2. 曼哈顿距离——曼哈顿距离是两点之间差异的绝对值之和。
2. 曼哈顿距离——曼哈顿距离是两点之间差异的绝对值之和。
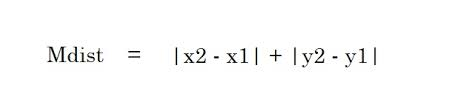 3. 闵可夫斯基距离——闵可夫斯基距离用于查找两点之间的距离相似度。 根据以下公式更改为曼哈顿距离(当 p=1 时)和欧几里德距离(当 p=2 时)。
3. 闵可夫斯基距离——闵可夫斯基距离用于查找两点之间的距离相似度。 根据以下公式更改为曼哈顿距离(当 p=1 时)和欧几里德距离(当 p=2 时)。
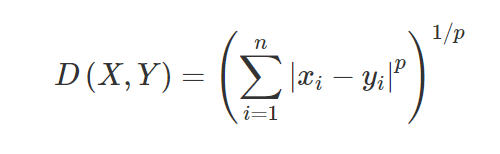 4. 汉明距离——汉明距离用于分类变量。 该指标将判断两个分类变量是否相同。
4. 汉明距离——汉明距离用于分类变量。 该指标将判断两个分类变量是否相同。
KNN 的应用
根据已有客户的信用使用情况和评级预测新客户的信用评级。
- 是否批准贷款? 给候选人。
- 对给定交易进行分类是否具有欺诈性。
- 推荐系统(YouTube、Netflix)
- 手写检测(如 OCR)。
- 图像识别。
- 视频识别。
KNN 的优缺点
机器学习由许多算法组成,因此每种算法都有自己的优点和缺点。 根据行业、领域和数据类型以及每种算法的不同评估指标,数据科学家应该选择适合并回答业务问题的最佳算法。 让我们看看 K-Nearest Neighbors 的一些优点和缺点。
优点
- 易于使用、理解和解释。
- 计算时间快。
- 没有关于数据的假设。
- 预测准确率高。
- 多功能——可用于分类和回归业务问题。
- 也可用于多类问题。
- 在 Hyperparameter Tuning 步骤中,我们只有一个 Hyper 参数需要调整。
缺点
- 由于算法存储所有训练数据,因此计算成本高且需要高内存。
- 随着变量的增加,算法变慢。
- 它对不相关的特征非常敏感。
- 维度的诅咒。
- 选择 K 的最优值。
- 类不平衡数据集会导致问题。
- 数据中的缺失值也会导致问题。
必读:机器学习项目理念
结论
这是一种基本的机器学习算法,以易用性和快速计算时间而闻名。 如果您是机器学习世界的新手,并且希望轻松完成给定的任务,这将是一个不错的算法。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT- B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
K-Nearest Neighbors 算法成本高吗?
在大量数据集的情况下,K-Nearest Neighbors 算法在计算时间和存储方面都可能很昂贵。 这是因为此 KNN 算法必须保存和存储所有训练数据集才能工作。 KNN 对训练数据的规模高度敏感,因为它取决于计算距离。 该算法不会根据有关训练数据的假设来获取结果。 尽管在考虑其他监督学习算法时这可能不是一般情况,但 KNN 算法被认为在解决非线性数据点带来的问题方面非常有效。
K-NN算法有哪些实际应用?
KNN算法经常被企业用来向有共同兴趣的个人推荐产品。 例如,公司可以根据观众的选择推荐电视节目,根据之前的购买推荐服装设计,并根据预订历史推荐旅行期间的酒店和住宿选择。 金融机构也可以使用它根据类似的金融特征为客户分配信用评级。 银行根据似乎与违约者具有相似特征的特定申请做出贷款支付决定。 该算法的高级应用包括图像识别、使用 OCR 的手写检测以及视频识别。
机器学习工程师的未来会是什么样子?
随着人工智能和机器学习的进一步发展,机器学习工程师的市场或需求看起来非常有希望。 到 2021 年下半年,LinkedIn 上列出了大约 23,000 个机器学习工程师职位。 从亚马逊、谷歌到 PayPal、Autodesk、摩根士丹利、埃森哲等全球巨头组织,一直在寻找顶尖人才。 凭借在编程、统计、机器学习等学科的坚实基础,工程师还可以在数据分析、自动化、人工智能集成和其他领域担任领导角色。