
Algoritma K-Nearest Neighbors dalam Pembelajaran Mesin [Dengan Contoh]
Diterbitkan: 2020-10-28Daftar isi
pengantar
Machine Learning tidak diragukan lagi merupakan salah satu teknologi paling canggih dan paling canggih di dunia berbasis data saat ini di mana kami mengumpulkan lebih banyak data setiap detik. Ini adalah salah satu teknologi yang berkembang pesat di mana setiap domain dan setiap sektor memiliki kasus penggunaan dan proyeknya sendiri.
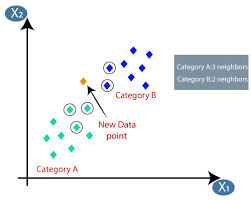
Pembelajaran Mesin atau Pengembangan Model adalah salah satu fase dalam Siklus Hidup Proyek Ilmu Data yang tampaknya menjadi salah satu yang paling penting juga. Artikel ini dirancang sebagai pengantar KNN (K-Nearest Neighbors) dalam Machine Learning.
K-Tetangga Terdekat
Jika Anda terbiasa dengan pembelajaran mesin atau pernah menjadi bagian dari Data Science atau tim AI, maka Anda mungkin pernah mendengar tentang algoritma k-Nearest Neighbors, atau yang biasa disebut KNN. Algoritma ini merupakan salah satu algoritma yang digunakan dalam pembelajaran mesin karena mudah diterapkan, non-parametrik, malas belajar dan memiliki waktu perhitungan yang rendah.
Keuntungan lain dari algoritma k-Nearest Neighbors adalah dapat digunakan untuk jenis Masalah Klasifikasi dan Regresi. Jika Anda tidak mengetahui perbedaan antara keduanya maka izinkan saya menjelaskan kepada Anda, perbedaan utama antara Klasifikasi dan Regresi adalah bahwa variabel keluaran dalam regresi adalah numerik (Berkelanjutan) sedangkan untuk klasifikasi adalah kategoris (Diskrit).
Baca: Algoritma KNN dalam R
Bagaimana cara kerja k-Nearest Neighbors?
Algoritma K-nearest neighbor (KNN) menggunakan teknik 'feature similarity' atau 'nearest neighbor' untuk memprediksi cluster tempat titik data baru masuk. Di bawah ini adalah beberapa langkah berdasarkan mana kita dapat memahami cara kerja algoritma ini dengan lebih baik

Langkah 1 - Untuk mengimplementasikan algoritme apa pun dalam Machine learning, kita memerlukan kumpulan data yang telah dibersihkan yang siap untuk dimodelkan. Mari kita asumsikan bahwa kita sudah memiliki kumpulan data yang telah dibersihkan yang telah dipecah menjadi kumpulan data pelatihan dan pengujian.
Langkah 2 - Karena kita sudah menyiapkan kumpulan data, kita perlu memilih nilai K (bilangan bulat) yang memberi tahu kita berapa banyak titik data terdekat yang perlu kita pertimbangkan untuk mengimplementasikan algoritma. Kita bisa mengetahui cara menentukan nilai k di artikel tahap selanjutnya.
Langkah 3 – Langkah ini merupakan langkah berulang dan perlu diterapkan untuk setiap titik data dalam kumpulan data
I. Hitung jarak antara data uji dan setiap baris data pelatihan menggunakan salah satu metrik jarak
Sebuah. Jarak Euclidean
B. jarak Manhattan
C. Jarak Minkowski
D. Jarak hamming.
Banyak ilmuwan data cenderung menggunakan jarak Euclidean, tetapi kita dapat mengetahui pentingnya masing-masing jarak pada tahap selanjutnya dari artikel ini.
II. Kita perlu mengurutkan data berdasarkan metrik jarak yang telah kita gunakan pada langkah di atas.
AKU AKU AKU. Pilih baris K teratas dalam data terurut yang diubah.
IV. Kemudian akan menetapkan kelas ke titik tes berdasarkan kelas yang paling sering dari baris ini.
Langkah 4 Akhir
Bagaimana cara menentukan nilai K?
Kita perlu memilih nilai K yang sesuai untuk mencapai akurasi maksimum model, tetapi tidak ada metode statistik yang ditentukan sebelumnya untuk menemukan nilai K yang paling disukai. Tetapi kebanyakan dari mereka menggunakan Metode Elbow.
Metode Elbow dimulai dengan menghitung Sum of Squared Error (SSE) untuk beberapa nilai k. SSE adalah jumlah kuadrat jarak antara setiap anggota cluster dan centroid-nya.
SSE=∑Ki=1∑x asam (x,ci)2SSE= x asam ( x ,ci)2
Jika Anda memplot nilai k yang berbeda terhadap SSE, kita dapat melihat bahwa kesalahan berkurang ketika nilai k semakin besar, ini terjadi karena ketika jumlah cluster meningkat, cluster akan cenderung menjadi lebih kecil, sehingga distorsi juga akan lebih kecil . Ide dari metode elbow adalah untuk memilih k dimana SSE turun secara tiba-tiba yang menandakan bentuk dari elbow.
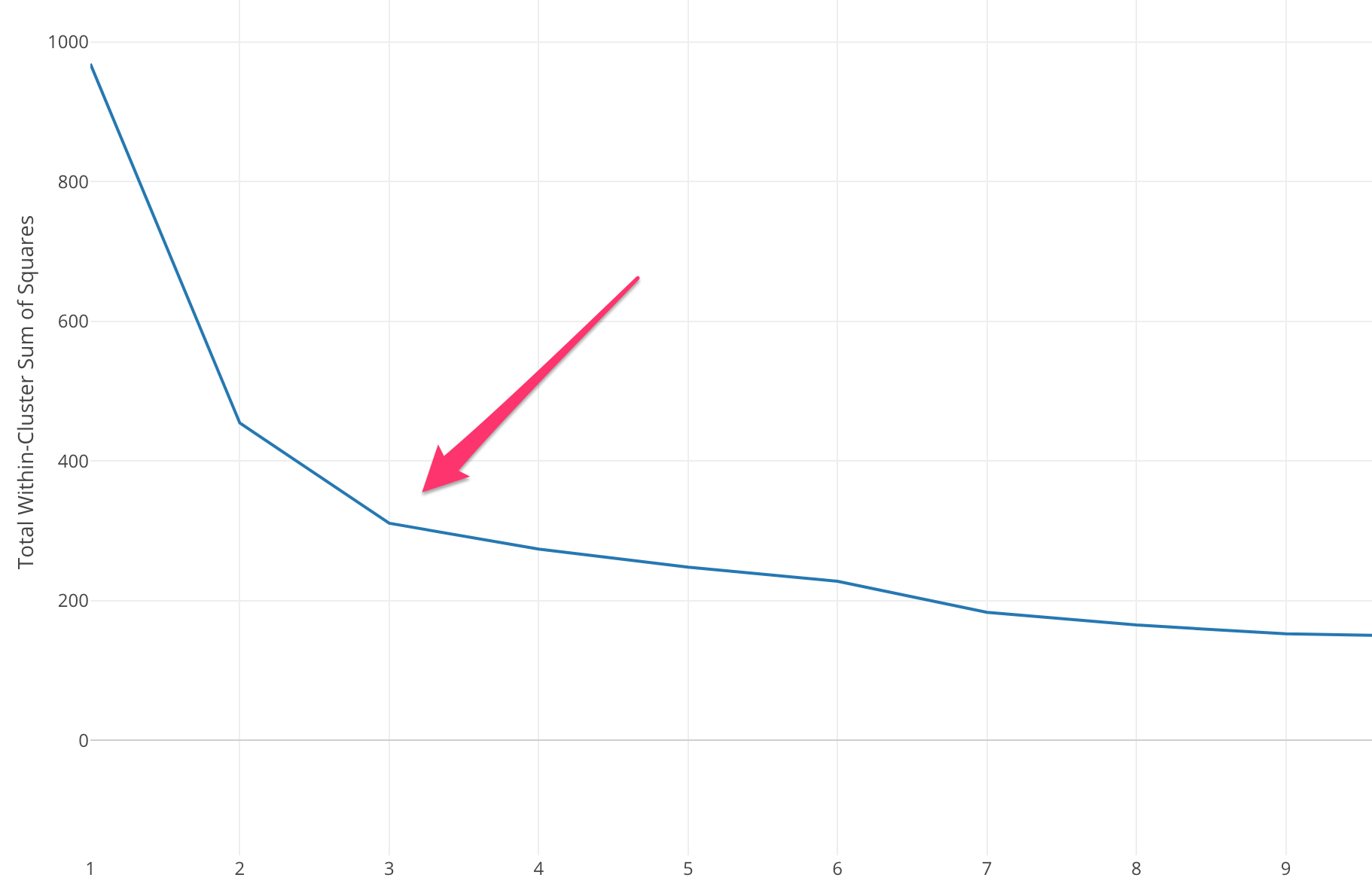
Dalam beberapa kasus, ada lebih dari satu siku, atau tidak ada siku sama sekali. Dalam kasus seperti itu, kami biasanya menghitung k terbaik dengan mengevaluasi seberapa baik kinerja Algoritma ML k-means dalam konteks masalah yang Anda coba selesaikan.
Baca Juga: Model Pembelajaran Mesin
Jenis Metrik Jarak
Mari kita mengenal metrik jarak yang berbeda yang digunakan untuk menghitung jarak antara dua titik data satu per satu.

1. Jarak Euclidean – Jarak Euclidean adalah akar kuadrat dari jumlah kuadrat jarak antara dua titik.
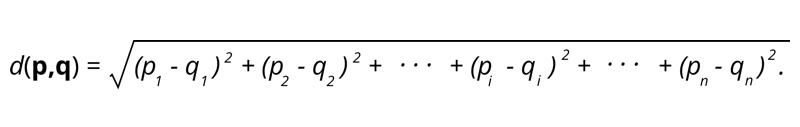 2. Jarak Manhattan – Jarak Manhattan adalah jumlah nilai absolut dari perbedaan antara dua titik.
2. Jarak Manhattan – Jarak Manhattan adalah jumlah nilai absolut dari perbedaan antara dua titik.
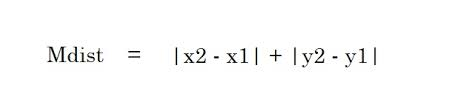 3. Jarak Minkowski – Jarak Minkowski digunakan untuk mencari kesamaan jarak antara dua titik. Berdasarkan rumus di bawah ini berubah menjadi jarak Manhattan (Ketika p=1) dan jarak Euclidean (Ketika p=2).
3. Jarak Minkowski – Jarak Minkowski digunakan untuk mencari kesamaan jarak antara dua titik. Berdasarkan rumus di bawah ini berubah menjadi jarak Manhattan (Ketika p=1) dan jarak Euclidean (Ketika p=2).
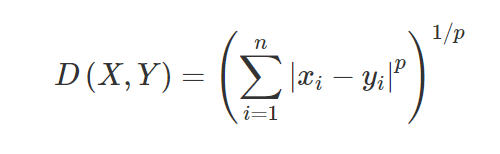 4. Jarak Hamming – Jarak Hamming digunakan untuk variabel kategori. Metrik ini akan memberi tahu apakah dua variabel kategori sama atau tidak.
4. Jarak Hamming – Jarak Hamming digunakan untuk variabel kategori. Metrik ini akan memberi tahu apakah dua variabel kategori sama atau tidak.
Aplikasi KNN
Memprediksi peringkat kredit pelanggan baru berdasarkan penggunaan dan peringkat kredit pelanggan yang sudah tersedia.
- Apakah akan memberikan sanksi pinjaman atau tidak? kepada seorang calon.
- Mengklasifikasikan transaksi yang diberikan adalah penipuan atau tidak.
- Sistem Rekomendasi (YouTube, Netflix)
- Deteksi tulisan tangan (seperti OCR).
- Pengenalan gambar.
- Pengenalan video.
Pro dan Kontra dari KNN
Machine Learning terdiri dari banyak algoritma, sehingga masing-masing memiliki kelebihan dan kekurangannya sendiri. Bergantung pada industri, domain, dan jenis data serta metrik evaluasi yang berbeda untuk setiap algoritme, Ilmuwan Data harus memilih algoritme terbaik yang sesuai dan menjawab masalah Bisnis. Mari kita lihat beberapa Pro dan Kontra dari K-Nearest Neighbors.
kelebihan
- Mudah digunakan, dipahami, dan diinterpretasikan.
- Waktu perhitungan cepat.
- Tidak ada asumsi tentang data.
- Akurasi prediksi yang tinggi.
- Serbaguna – Dapat digunakan untuk Masalah Bisnis Klasifikasi dan Regresi.
- Dapat digunakan untuk Masalah Multi Kelas juga.
- Kami hanya memiliki satu parameter Hyper untuk di-tweak pada langkah Hyperparameter Tuning.
Kontra
- Komputasi mahal dan membutuhkan memori tinggi karena algoritme menyimpan semua data pelatihan.
- Algoritma menjadi lebih lambat ketika variabel meningkat.
- Sangat sensitif terhadap fitur yang tidak relevan.
- Kutukan Dimensi.
- Memilih nilai K yang optimal.
- Dataset kelas tidak seimbang akan menyebabkan masalah.
- Nilai yang hilang dalam data juga menyebabkan masalah.
Harus Dibaca: Ide Proyek Pembelajaran Mesin
Kesimpulan
Ini adalah algoritme pembelajaran mesin dasar yang terkenal karena kemudahan penggunaan dan waktu kalkulasi yang cepat. Ini akan menjadi algoritme yang layak untuk dipilih jika Anda sangat baru di Dunia Pembelajaran Mesin dan ingin menyelesaikan tugas yang diberikan tanpa banyak kesulitan.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pembelajaran mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk para profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, IIIT- B Status alumni, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Apakah algoritma K-Nearest Neighbors mahal?
Dalam kasus kumpulan data yang sangat besar, algoritma K-Nearest Neighbors bisa mahal baik dari segi waktu komputasi maupun penyimpanan. Ini karena algoritma KNN ini harus menyimpan dan menyimpan semua set data pelatihan agar berfungsi. KNN sangat sensitif terhadap skala data latih karena bergantung pada penghitungan jarak. Algoritma ini tidak mengambil hasil berdasarkan asumsi tentang data pelatihan. Meskipun ini mungkin bukan kasus umum ketika Anda mempertimbangkan algoritme pembelajaran terawasi lainnya, algoritme KNN dianggap sangat efektif dalam memecahkan masalah yang datang dengan titik data non-linier.
Apa sajakah aplikasi praktis dari algoritma K-NN?
Algoritma KNN sering digunakan oleh bisnis untuk merekomendasikan produk kepada individu yang memiliki minat yang sama. Misalnya, perusahaan dapat menyarankan acara TV berdasarkan pilihan pemirsa, desain pakaian berdasarkan pembelian sebelumnya, dan pilihan hotel dan akomodasi selama tur berdasarkan riwayat pemesanan. Ini juga dapat digunakan oleh lembaga keuangan untuk memberikan peringkat kredit kepada pelanggan berdasarkan fitur keuangan yang serupa. Bank mendasarkan keputusan pencairan pinjaman mereka pada aplikasi spesifik yang tampaknya memiliki karakteristik yang mirip dengan mangkir. Aplikasi lanjutan dari algoritma ini termasuk pengenalan gambar, deteksi tulisan tangan menggunakan OCR serta pengenalan video.
Seperti apa masa depan bagi para insinyur pembelajaran mesin?
Dengan kemajuan lebih lanjut dalam AI dan pembelajaran mesin, pasar atau permintaan untuk insinyur pembelajaran mesin terlihat sangat menjanjikan. Pada paruh kedua tahun 2021, ada sekitar 23.000 pekerjaan yang terdaftar di LinkedIn untuk insinyur pembelajaran mesin. Organisasi raksasa global mulai dari Amazon dan Google hingga PayPal, Autodesk, Morgan Stanley, Accenture, dan lainnya, selalu mencari talenta terbaik. Dengan dasar-dasar yang kuat dalam mata pelajaran seperti pemrograman, statistik, pembelajaran mesin, insinyur juga dapat mengambil peran kepemimpinan dalam analisis data, otomatisasi, integrasi AI, dan area lainnya.