
使用 TensorFlow 进行深度学习中的模型验证和正则化实践介绍
已发表: 2020-10-28目录
介绍
机器通过监督学习算法的范式来吸收信息的实践已经彻底改变了一些任务,如序列生成、自然语言处理甚至计算机视觉。 这种方法基于利用具有一组输入特征和一组相应标签的数据集。 然后机器使用以特征和标签形式存在的这些信息来学习数据的分布和模式,从而对看不见的输入进行统计预测。
设计深度学习模型的一个重要步骤是评估模型性能,尤其是在新的和看不见的数据点上。 关键目标是开发超越训练数据的模型。 我们需要能够在现实世界中做出良好且可靠预测的模型。 帮助我们解决这个问题的一个重要概念是我们今天将介绍的模型验证和正则化。
模型验证
构建机器学习模型总是归结为将可用数据分成三组:训练、验证和测试集。 模型使用训练数据来学习分布的怪癖和特征。
这里要知道的一个重点是,模型在训练集上的令人满意的表现并不意味着模型也会在具有相似性能的新数据上泛化,这是因为模型已经偏向于训练集。 因此,验证和测试集的概念用于报告模型对新数据点的泛化程度。
标准程序是使用训练数据拟合模型,使用验证数据评估模型性能,最后使用测试数据评估模型在全新示例上的表现。
验证集用于调整超参数(隐藏层数、学习率、辍学率等) ,以便模型能够很好地泛化。 机器学习新手面临的一个常见难题是了解单独验证和测试集的需求。

对两个不同集合的需求可以通过以下直觉来理解:对于每个需要设计的深度神经网络,都存在多个需要调整以获得令人满意的性能的超参数。
可以使用任一超参数训练多个模型,然后可以根据该模型在验证集上的性能选择具有最佳性能指标的模型。 现在,每次为了在验证集上获得更好的性能而调整超参数时,一些信息就会泄漏/输入到模型中,因此,神经网络的最终权重可能会偏向验证集。
每次调整超参数后,我们的模型在验证集上继续表现良好,因为这是我们优化它的目的。 这就是验证测试不能准确地表示模型的泛化能力的原因。 为了克服这个缺点,测试集开始发挥作用。
模型泛化能力的最准确表示是由测试集上的性能给出的,因为我们没有优化模型以在该集上获得更好的性能,因此,这将表明对模型能力的最实用估计。
必读:您应该了解的顶级深度学习技术
使用 TensorFlow 2.0 实施验证策略
TensorFlow 2.0 提供了一个非常简单的解决方案,可以在单独的保留验证测试中跟踪我们模型的性能。 我们可以在model.fit()方法中传递validation_split关键字参数。
validation_split关键字将输入作为介于0 和 1之间的浮点数,表示要用作验证数据的训练数据的比例。 因此,在关键字中传递0.1的值意味着保留10%的训练数据用于验证。
使用sklearn的糖尿病数据集可以轻松演示验证拆分的实际实现。 该数据集有 442 个实例,其中 10 个基线变量(年龄、性别、BMI 等)作为训练特征,一年后疾病进展的度量作为其标签。
我们使用 TensorFlow 和 sklearn 导入数据集:

数据预处理后的基本步骤是构建具有密集层的顺序前馈神经网络:

在这里,我们有一个神经网络,它有六个带有relu激活的隐藏层和一个带有线性激活的输出层。
然后我们使用Adam优化器和均方误差损失函数编译模型。


然后使用model.fit()方法来训练模型 100 个 epoch, validation_split为 15%。

我们还可以绘制对训练数据和验证数据都观察到的模型损失:
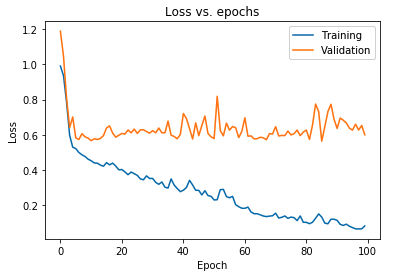
上图显示,验证损失在 10 个 epoch 后持续上升,而训练损失继续减少。 这种趋势是机器学习中一个非常重要的问题的教科书示例,称为过度拟合。
已经进行了许多开创性的研究来克服这个问题,这些解决方案统称为正则化技术。 以下部分将介绍正则化的方面以及正则化任何深度学习模型的过程。
规范我们的模型
在上一节中,我们在训练集和验证集的损失图中观察到了相反的趋势,其中后一组的成本函数图似乎在上升,而前一组的成本函数图继续下降,因此产生了差距(泛化差距)。 详细了解机器学习中的正则化。
两个损失图之间存在这种差距的事实表明,该模型无法很好地泛化验证集(看不见的数据) ,因此该数据集上产生的成本/损失值也将不可避免地很高。
之所以会出现这种特殊性,是因为经过训练的模型的权重和偏差能够很好地共同适应训练数据的分布,以至于它无法预测新的和看不见的特征的标签,从而导致验证损失增加。
基本原理是,配置一个复杂的模型会产生这样的异常,因为模型参数变得对训练数据变得非常健壮。 因此,简化或降低模型的容量/复杂度将减少过拟合效应。 实现这一点的一种方法是在我们的深度学习模型中使用 dropout,我们将在下一节中介绍。
在 TensorFlow 中理解和实现 Dropout
使用 dropouts 背后的关键感知是随机删除隐藏和可见单元,以获得一个不太复杂的模型,该模型限制模型参数的增加,因此,使模型在广义数据集上的性能更加稳健。
这种最近被接受的做法是机器学习从业者用来在任何深度学习模型中诱导正则化效果的强大方法。 Dropout 可以通过 TensorFlow 上的 Keras API 轻松实现,方法是导入dropout层并在其中传递rate参数以指定需要删除的单元的分数。
这些 dropout 层通常在每个密集层之后立即堆叠,以产生密集 dropout层架构的交替潮。
我们可以修改我们之前定义的前馈神经网络,使其包含六个dropout层,每个隐藏层一个:


在这里, dropout_rate设置为0.2 ,这表示在训练模型时将丢弃 20% 的节点。 我们使用相同的优化器、损失函数、指标和 epoch 数来编译和训练模型,以便进行公平比较。
使用 dropout 对模型进行正则化的主要影响可以通过再次绘制在训练集和验证集上获得的模型的损失曲线来解释:
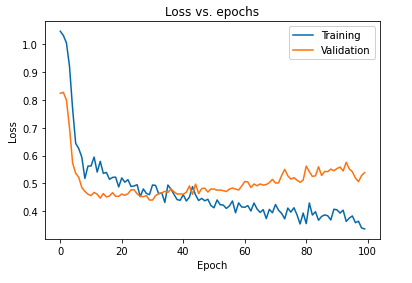
从上图中可以明显看出,对模型进行正则化后得到的泛化差距要小得多,这使得模型不太容易过度拟合训练数据。
另请阅读:深度学习项目理念
结论
模型验证和正则化方面是设计构建任何机器学习解决方案的工作流程的重要部分。 为了即兴监督学习,正在进行大量研究,本动手教程提供了在组装任何学习算法时对一些最被接受的实践和技术的简要了解。
如果您有兴趣了解有关深度学习技术、机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和深度学习 PG 认证,该认证专为在职专业人士设计,提供 240 多个小时的严格培训、5 个以上的案例研究和分配,IIIT-B 校友身份和顶级公司的工作协助。