
機器學習中的 K-Nearest Neighbors 算法 [附示例]
已發表: 2020-10-28目錄
介紹
機器學習無疑是當今數據驅動的世界中最流行和最強大的技術之一,我們每秒鐘都在收集更多的數據。 這是快速發展的技術之一,每個領域和每個部門都有自己的用例和項目。
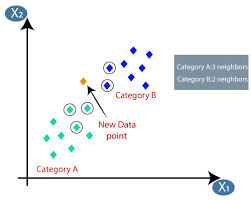
機器學習或模型開發是數據科學項目生命週期中的階段之一,這似乎也是最重要的階段之一。 本文旨在介紹機器學習中的 KNN(K-Nearest Neighbors)。
K-最近鄰
如果您熟悉機器學習或者曾經是數據科學或 AI 團隊的一員,那麼您可能聽說過 k-最近鄰算法,或者簡稱為 KNN。 該算法是機器學習中常用的算法之一,因為它易於實現、非參數、惰性學習並且計算時間短。
k-Nearest Neighbors 算法的另一個優點是它可以用於分類和回歸類型的問題。 如果您不知道這兩者之間的區別,那麼讓我向您說明,分類和回歸之間的主要區別在於回歸中的輸出變量是數值(連續),而分類輸出變量是分類(離散)。
閱讀: R 中的 KNN 算法
k-最近鄰是如何工作的?
K-最近鄰(KNN)算法使用“特徵相似性”或“最近鄰”技術來預測新數據點落入的集群。 以下是我們可以更好地理解該算法的工作的幾個步驟

第 1 步-為了在機器學習中實現任何算法,我們需要準備好用於建模的清潔數據集。 假設我們已經有一個清理過的數據集,該數據集已分為訓練和測試數據集。
第 2 步-由於我們已經準備好數據集,我們需要選擇 K(整數)的值,它告訴我們需要考慮多少最近的數據點來實現算法。 我們可以在文章的後期了解如何確定k值。
Step 3 -此步驟是一個迭代步驟,需要應用於數據集中的每個數據點
I. 使用任意距離度量計算測試數據與每行訓練數據之間的距離
一種。 歐幾里得距離
灣。 曼哈頓距離
C。 閔可夫斯基距離
d。 漢明距離。
許多數據科學家傾向於使用歐幾里得距離,但我們可以在本文的後期了解每一個的意義。
二、 我們需要根據我們在上述步驟中使用的距離度量對數據進行排序。
三、 選擇轉換後的排序數據中的前 K 行。
四。 然後它將根據這些行中最常見的類為測試點分配一個類。
第 4 步-結束
如何確定K值?
我們需要選擇一個合適的 K 值來達到模型的最大精度,但是沒有預先定義的統計方法來找到最有利的 K 值。但大多數使用肘法。
肘部方法首先計算某些 k 值的平方誤差和 (SSE)。 SSE 是集群的每個成員與其質心之間的平方距離之和。
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
如果根據 SSE 繪製不同的 k 值,我們可以看到隨著 k 的值變大,誤差會減小,這是因為當聚類數量增加時,聚類會趨於變小,因此失真也會變小. 肘部法的思想是選擇 SSE 突然下降的 k 值,表示肘部的形狀。
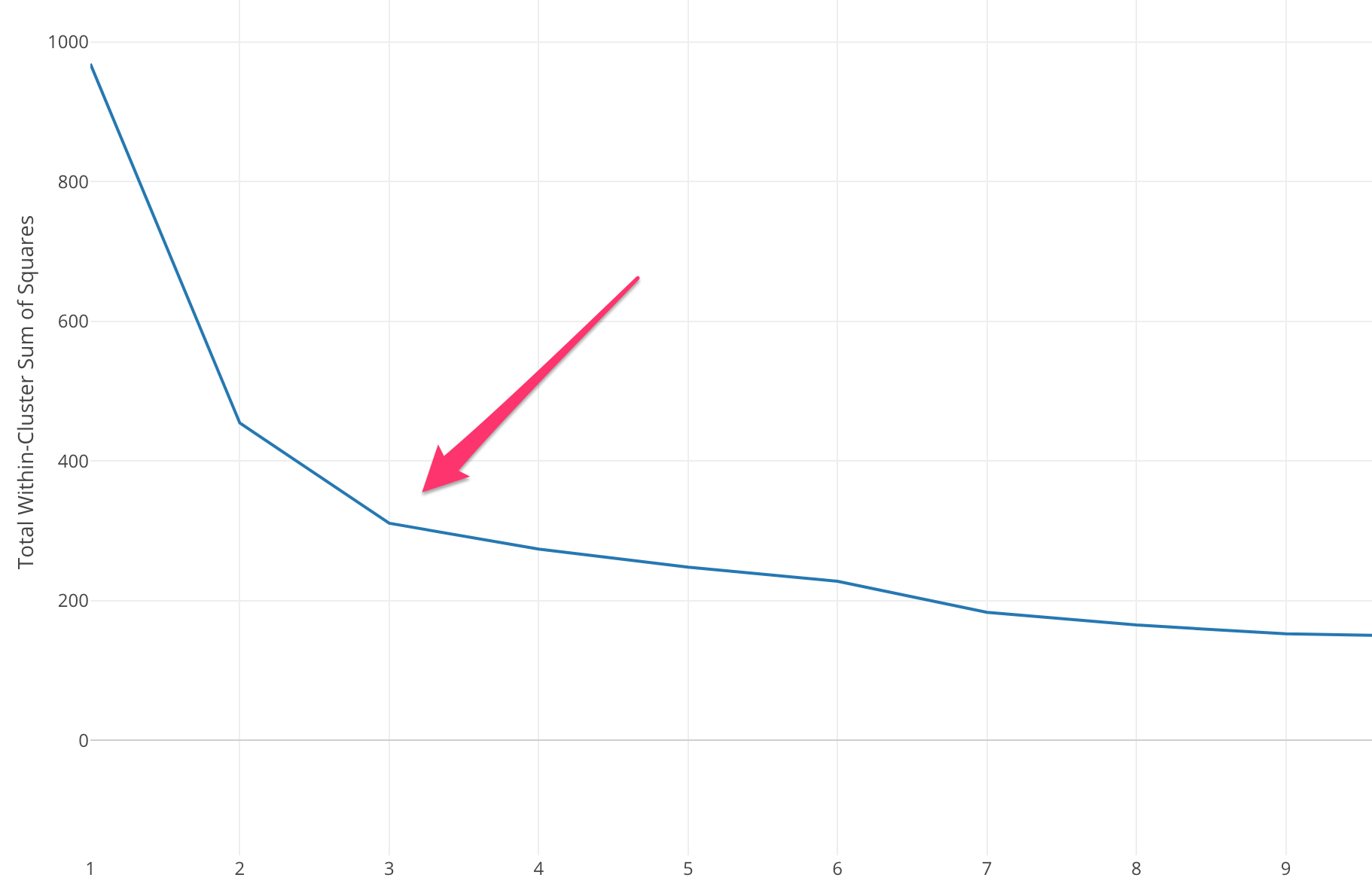
在某些情況下,有不止一個肘部,或者根本沒有肘部。 在這種情況下,我們通常通過評估 k-means ML 算法在您嘗試解決的問題的上下文中的執行情況來計算最佳 k。

另請閱讀:機器學習模型
距離度量的類型
讓我們一一了解用於計算兩個數據點之間距離的不同距離度量。
1.歐幾里得距離——歐幾里得距離是兩點間距離平方和的平方根。
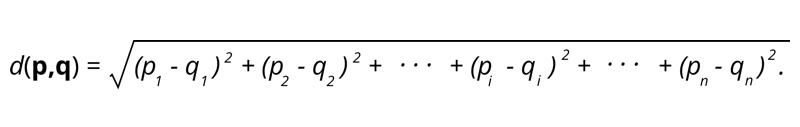 2. 曼哈頓距離——曼哈頓距離是兩點之間差異的絕對值之和。
2. 曼哈頓距離——曼哈頓距離是兩點之間差異的絕對值之和。
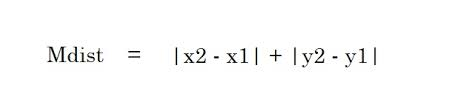 3. 閔可夫斯基距離——閔可夫斯基距離用於查找兩點之間的距離相似度。 根據以下公式更改為曼哈頓距離(當 p=1 時)和歐幾里德距離(當 p=2 時)。
3. 閔可夫斯基距離——閔可夫斯基距離用於查找兩點之間的距離相似度。 根據以下公式更改為曼哈頓距離(當 p=1 時)和歐幾里德距離(當 p=2 時)。
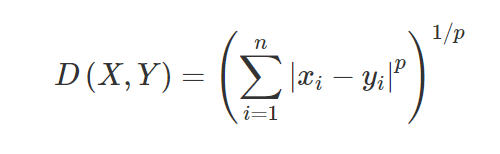 4. 漢明距離——漢明距離用於分類變量。 該指標將判斷兩個分類變量是否相同。
4. 漢明距離——漢明距離用於分類變量。 該指標將判斷兩個分類變量是否相同。
KNN 的應用
根據已有客戶的信用使用情況和評級預測新客戶的信用評級。
- 是否批准貸款? 給候選人。
- 對給定交易進行分類是否具有欺詐性。
- 推薦系統(YouTube、Netflix)
- 手寫檢測(如 OCR)。
- 圖像識別。
- 視頻識別。
KNN 的優缺點
機器學習由許多算法組成,因此每種算法都有自己的優點和缺點。 根據行業、領域和數據類型以及每種算法的不同評估指標,數據科學家應該選擇適合併回答業務問題的最佳算法。 讓我們看看 K-Nearest Neighbors 的一些優點和缺點。
優點
- 易於使用、理解和解釋。
- 計算時間快。
- 沒有關於數據的假設。
- 預測準確率高。
- 多功能——可用於分類和回歸業務問題。
- 也可用於多類問題。
- 在 Hyperparameter Tuning 步驟中,我們只有一個 Hyper 參數需要調整。
缺點
- 由於算法存儲所有訓練數據,因此計算成本高且需要高內存。
- 隨著變量的增加,算法變慢。
- 它對不相關的特徵非常敏感。
- 維度的詛咒。
- 選擇 K 的最優值。
- 類不平衡數據集會導致問題。
- 數據中的缺失值也會導致問題。
必讀:機器學習項目理念
結論
這是一種基本的機器學習算法,以易用性和快速計算時間而聞名。 如果您是機器學習世界的新手,並且希望輕鬆完成給定的任務,這將是一個不錯的算法。
如果您有興趣了解有關機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為工作專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和作業、IIIT- B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
K-Nearest Neighbors 算法成本高嗎?
在大量數據集的情況下,K-Nearest Neighbors 算法在計算時間和存儲方面都可能很昂貴。 這是因為此 KNN 算法必須保存和存儲所有訓練數據集才能工作。 KNN 對訓練數據的規模高度敏感,因為它取決於計算距離。 該算法不會根據有關訓練數據的假設來獲取結果。 儘管在考慮其他監督學習算法時這可能不是一般情況,但 KNN 算法被認為在解決非線性數據點帶來的問題方面非常有效。
K-NN算法有哪些實際應用?
KNN算法經常被企業用來向有共同興趣的個人推薦產品。 例如,公司可以根據觀眾的選擇推薦電視節目,根據之前的購買推薦服裝設計,並根據預訂歷史推薦旅行期間的酒店和住宿選擇。 金融機構也可以使用它根據類似的金融特徵為客戶分配信用評級。 銀行根據似乎與違約者俱有相似特徵的特定申請做出貸款支付決定。 該算法的高級應用包括圖像識別、使用 OCR 的手寫檢測以及視頻識別。
機器學習工程師的未來會是什麼樣子?
隨著人工智能和機器學習的進一步發展,機器學習工程師的市場或需求看起來非常有希望。 到 2021 年下半年,LinkedIn 上列出了大約 23,000 個機器學習工程師職位。 從亞馬遜、谷歌到 PayPal、Autodesk、摩根士丹利、埃森哲等全球巨頭組織,一直在尋找頂尖人才。 憑藉在編程、統計、機器學習等學科的堅實基礎,工程師還可以在數據分析、自動化、人工智能集成和其他領域擔任領導角色。