
Algorithme K-Nearest Neighbors dans l'apprentissage automatique [avec exemples]
Publié: 2020-10-28Table des matières
introduction
L'apprentissage automatique est sans aucun doute l'une des technologies les plus performantes et les plus puissantes dans le monde actuel axé sur les données, où nous collectons plus de données à chaque seconde. C'est l'une des technologies à croissance rapide où chaque domaine et chaque secteur a ses propres cas d'utilisation et projets.
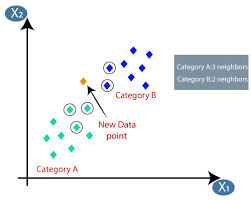
L'apprentissage automatique ou le développement de modèles est l'une des phases du cycle de vie d'un projet de science des données qui semble également être l'une des plus importantes. Cet article est conçu comme une introduction à KNN (K-Nearest Neighbors) dans Machine Learning.
K-Voisins les plus proches
Si vous êtes familier avec l'apprentissage automatique ou avez fait partie de l'équipe Data Science ou AI, vous avez probablement entendu parler de l'algorithme k-Nearest Neighbors, ou simplement appelé KNN. Cet algorithme est l'un des algorithmes de référence utilisés dans l'apprentissage automatique car il est facile à mettre en œuvre, non paramétrique, d'apprentissage paresseux et a un faible temps de calcul.
Un autre avantage de l'algorithme k-Nearest Neighbors est qu'il peut être utilisé à la fois pour les types de problèmes de classification et de régression. Si vous n'êtes pas au courant de la différence entre ces deux, permettez-moi de vous préciser que la principale différence entre la classification et la régression est que la variable de sortie dans la régression est numérique (continue) tandis que celle de la classification est catégorique (discrète).
Lire : Algorithmes KNN dans R
Comment fonctionne k-Nearest Neighbors ?
L'algorithme K-plus proches voisins (KNN) utilise la technique de « similitude des caractéristiques » ou de « plus proches voisins » pour prédire le cluster dans lequel un nouveau point de données tombe. Voici les quelques étapes sur lesquelles nous pouvons mieux comprendre le fonctionnement de cet algorithme

Étape 1 - Pour implémenter n'importe quel algorithme dans l'apprentissage automatique, nous avons besoin d'un ensemble de données nettoyé prêt pour la modélisation. Supposons que nous ayons déjà un ensemble de données nettoyé qui a été divisé en ensemble de données d'apprentissage et de test.
Étape 2 - Comme nous avons déjà les ensembles de données prêts, nous devons choisir la valeur de K (entier) qui nous indique combien de points de données les plus proches nous devons prendre en considération pour implémenter l'algorithme. Nous pouvons apprendre à déterminer la valeur k dans les dernières étapes de l'article.
Étape 3 - Cette étape est itérative et doit être appliquée pour chaque point de données dans l'ensemble de données
I. Calculer la distance entre les données de test et chaque ligne de données d'entraînement à l'aide de l'une des mesures de distance
une. Distance euclidienne
b. Manhattan distance
c. Distance Minkowski
ré. Distance de Hamming.
De nombreux spécialistes des données ont tendance à utiliser la distance euclidienne, mais nous pourrons connaître la signification de chacun dans la dernière étape de cet article.
II. Nous devons trier les données en fonction de la métrique de distance que nous avons utilisée à l'étape ci-dessus.
III. Choisissez les K premières lignes dans les données triées transformées.
IV. Ensuite, il attribuera une classe au point de test en fonction de la classe la plus fréquente de ces lignes.
Étape 4 - Fin
Comment déterminer la valeur K ?
Nous devons sélectionner une valeur K appropriée pour obtenir la précision maximale du modèle, mais il n'existe pas de méthodes statistiques prédéfinies pour trouver la valeur la plus favorable de K. Mais la plupart d'entre elles utilisent la méthode du coude.
La méthode du coude commence par calculer la somme de l'erreur quadratique (SSE) pour certaines valeurs de k. Le SSE est la somme de la distance au carré entre chaque membre du cluster et son centroïde.
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist (x,ci)2
Si vous tracez différentes valeurs de k par rapport au SSE, nous pouvons voir que l'erreur diminue à mesure que la valeur de k augmente, cela se produit parce que lorsque le nombre de clusters augmente, les clusters auront tendance à devenir plus petits, donc la distorsion sera également plus petite . L'idée de la méthode du coude est de choisir le k auquel le SSE diminue soudainement signifiant la forme du coude.
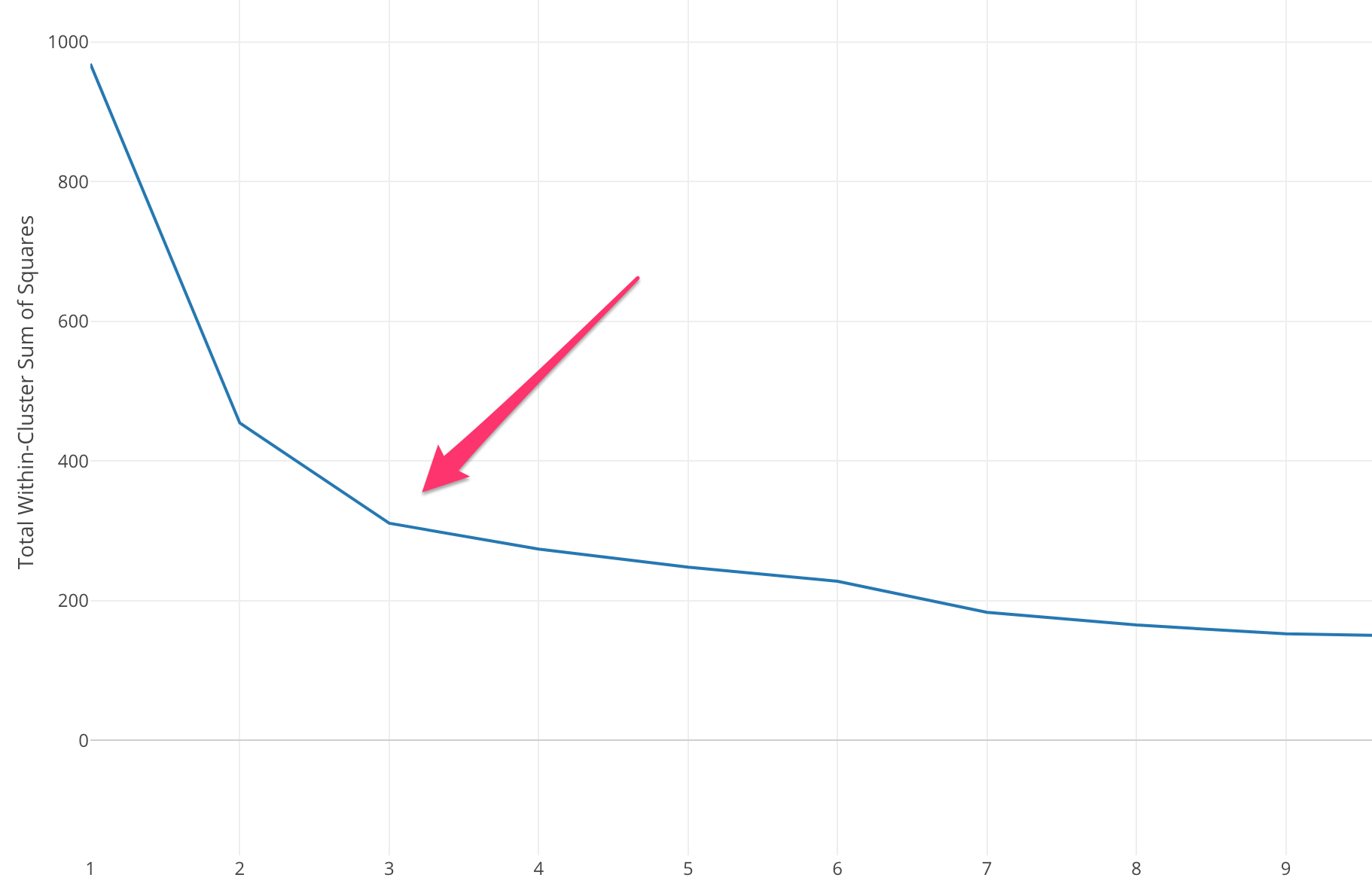
Dans certains cas, il y a plus d'un coude, ou pas de coude du tout. Dans de tels cas, nous finissons généralement par calculer le meilleur k en évaluant les performances de k-means ML Algorithm dans le contexte du problème que vous essayez de résoudre.
Lisez aussi : Modèles d'apprentissage automatique
Types de mesures de distance
Apprenons à connaître les différentes mesures de distance utilisées pour calculer la distance entre deux points de données un par un.

1. Distance euclidienne - La distance euclidienne est la racine carrée de la somme de la distance au carré entre deux points.
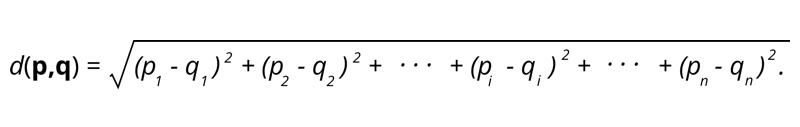 2. Distance de Manhattan – La distance de Manhattan est la somme des valeurs absolues des différences entre deux points.
2. Distance de Manhattan – La distance de Manhattan est la somme des valeurs absolues des différences entre deux points.
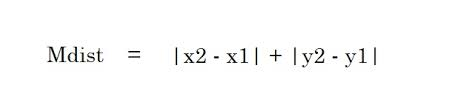 3. Distance de Minkowski - La distance de Minkowski est utilisée pour trouver la similarité de distance entre deux points. Sur la base de la formule ci-dessous, la distance Manhattan (lorsque p = 1) et la distance euclidienne (lorsque p = 2) sont modifiées.
3. Distance de Minkowski - La distance de Minkowski est utilisée pour trouver la similarité de distance entre deux points. Sur la base de la formule ci-dessous, la distance Manhattan (lorsque p = 1) et la distance euclidienne (lorsque p = 2) sont modifiées.
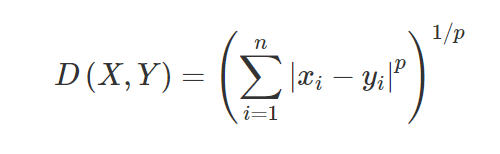 4. Distance de Hamming - La distance de Hamming est utilisée pour les variables catégorielles. Cette métrique indiquera si deux variables catégorielles sont identiques ou non.
4. Distance de Hamming - La distance de Hamming est utilisée pour les variables catégorielles. Cette métrique indiquera si deux variables catégorielles sont identiques ou non.
Applications de KNN
Prédire la cote de crédit d'un nouveau client en fonction des utilisations et des cotes de crédit des clients déjà disponibles.
- Que ce soit pour sanctionner un prêt ou non? à un candidat.
- La classification d'une transaction donnée est frauduleuse ou non.
- Système de recommandation (YouTube, Netflix)
- Détection de l'écriture manuscrite (comme l'OCR).
- Reconnaissance d'images.
- Reconnaissance vidéo.
Avantages et inconvénients de KNN
L'apprentissage automatique se compose de nombreux algorithmes, chacun a donc ses propres avantages et inconvénients. En fonction de l'industrie, du domaine et du type de données et des différentes mesures d'évaluation pour chaque algorithme, un Data Scientist doit choisir le meilleur algorithme qui correspond et répond au problème commercial. Voyons quelques avantages et inconvénients des K-plus proches voisins.
Avantages
- Facile à utiliser, à comprendre et à interpréter.
- Temps de calcul rapide.
- Aucune hypothèse sur les données.
- Haute précision des prédictions.
- Polyvalent - Peut être utilisé pour les problèmes commerciaux de classification et de régression.
- Peut également être utilisé pour les problèmes multi-classes.
- Nous n'avons qu'un seul paramètre Hyper à modifier à l'étape de réglage de l'hyperparamètre.
Les inconvénients
- Coûteux en termes de calcul et nécessitant beaucoup de mémoire car l'algorithme stocke toutes les données d'entraînement.
- L'algorithme devient plus lent à mesure que les variables augmentent.
- Il est très sensible aux fonctionnalités non pertinentes.
- Malédiction de dimensionnalité.
- Choisir la valeur optimale de K.
- Un ensemble de données déséquilibré de classe causera un problème.
- Les valeurs manquantes dans les données causent également des problèmes.
Doit lire : Idées de projets d'apprentissage automatique
Conclusion
Il s'agit d'un algorithme d'apprentissage automatique fondamental qui est connu pour sa facilité d'utilisation et son temps de calcul rapide. Ce serait un algorithme décent à choisir si vous êtes très nouveau dans Machine Learning World et que vous souhaitez terminer la tâche donnée sans trop de tracas.
Si vous souhaitez en savoir plus sur l'apprentissage automatique, consultez le diplôme PG en apprentissage automatique et IA de IIIT-B & upGrad, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et missions, IIIT- Statut B Alumni, plus de 5 projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
L'algorithme K-Nearest Neighbors est-il cher ?
Dans le cas d'énormes ensembles de données, l'algorithme K-Nearest Neighbors peut être coûteux à la fois en termes de temps de calcul et de stockage. En effet, cet algorithme KNN doit enregistrer et stocker tous les ensembles de données d'apprentissage pour fonctionner. KNN est très sensible à l'échelle des données d'entraînement puisqu'elle dépend du calcul des distances. Cet algorithme ne récupère pas les résultats basés sur des hypothèses concernant les données d'apprentissage. Même si ce n'est peut-être pas le cas général lorsque vous considérez d'autres algorithmes d'apprentissage supervisé, l'algorithme KNN est considéré comme très efficace pour résoudre les problèmes liés aux points de données non linéaires.
Quelles sont certaines des applications pratiques de l'algorithme K-NN ?
L'algorithme KNN est souvent utilisé par les entreprises pour recommander des produits à des personnes partageant des intérêts communs. Par exemple, les entreprises peuvent suggérer des émissions de télévision en fonction des choix des téléspectateurs, des conceptions de vêtements en fonction d'achats antérieurs et des options d'hôtel et d'hébergement pendant les visites en fonction de l'historique des réservations. Il peut également être utilisé par les institutions financières pour attribuer des cotes de crédit aux clients en fonction de caractéristiques financières similaires. Les banques fondent leurs décisions de décaissement de prêts sur des demandes spécifiques qui semblent partager des caractéristiques similaires aux défaillants. Les applications avancées de cet algorithme incluent la reconnaissance d'images, la détection d'écriture manuscrite à l'aide de l'OCR ainsi que la reconnaissance vidéo.
À quoi ressemble l'avenir pour les ingénieurs en apprentissage automatique ?
Avec de nouvelles avancées dans l'IA et l'apprentissage automatique, le marché ou la demande d'ingénieurs en apprentissage automatique semble très prometteur. Au second semestre 2021, il y avait environ 23 000 emplois répertoriés sur LinkedIn pour les ingénieurs en apprentissage automatique. Des géants mondiaux comme Amazon et Google, PayPal, Autodesk, Morgan Stanley, Accenture et autres, sont toujours à la recherche des meilleurs talents. Avec de solides bases dans des domaines tels que la programmation, les statistiques, l'apprentissage automatique, les ingénieurs peuvent également assumer des rôles de leadership dans l'analyse de données, l'automatisation, l'intégration de l'IA et d'autres domaines.