
Алгоритм K-ближайших соседей в машинном обучении [с примерами]
Опубликовано: 2020-10-28Оглавление
Введение
Машинное обучение, несомненно, является одной из самых современных и мощных технологий в современном мире, управляемом данными, где каждую секунду мы собираем все больше данных. Это одна из быстрорастущих технологий, где каждая область и каждый сектор имеют свои варианты использования и проекты.
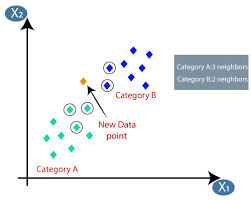
Машинное обучение или разработка моделей — это один из этапов жизненного цикла проекта по науке о данных, который также кажется одним из самых важных. Эта статья предназначена для введения в KNN (K-ближайшие соседи) в машинном обучении.
K-ближайшие соседи
Если вы знакомы с машинным обучением или были частью команды по науке о данных или искусственному интеллекту, то вы, вероятно, слышали об алгоритме k-ближайших соседей, или простом, называемом KNN. Этот алгоритм является одним из самых популярных алгоритмов, используемых в машинном обучении, потому что он прост в реализации, непараметричен, ленив и требует небольшого времени расчета.
Еще одно преимущество алгоритма k-ближайших соседей заключается в том, что его можно использовать как для задач типа классификации, так и для задач регрессии. Если вы не знаете о разнице между этими двумя, позвольте мне пояснить вам, что основное различие между классификацией и регрессией заключается в том, что выходная переменная в регрессии является числовой (непрерывной), а для классификации - категориальной (дискретной).
Читайте: Алгоритмы KNN в R
Как работает k-ближайшие соседи?
Алгоритм K-ближайших соседей (KNN) использует метод «сходства признаков» или «ближайших соседей» для прогнозирования кластера, в который попадает новая точка данных. Ниже приведены несколько шагов, на основе которых мы можем лучше понять работу этого алгоритма.

Шаг 1 — Для реализации любого алгоритма машинного обучения нам нужен очищенный набор данных, готовый к моделированию. Предположим, что у нас уже есть очищенный набор данных, который был разделен на набор данных для обучения и тестирования.
Шаг 2 — Поскольку у нас уже есть готовые наборы данных, нам нужно выбрать значение K (целое число), которое говорит нам, сколько ближайших точек данных нам нужно принять во внимание для реализации алгоритма. Мы можем узнать, как определить значение k на более поздних этапах статьи.
Шаг 3 — Этот шаг является итеративным, и его необходимо применять для каждой точки данных в наборе данных.
I. Рассчитайте расстояние между тестовыми данными и каждой строкой обучающих данных, используя любую из метрик расстояния.
а. Евклидово расстояние
б. Манхэттенское расстояние
в. расстояние Минковского
д. Расстояние Хэмминга.
Многие специалисты по данным склонны использовать евклидово расстояние, но мы можем узнать значение каждого из них на более позднем этапе этой статьи.
II. Нам нужно отсортировать данные на основе метрики расстояния, которую мы использовали на предыдущем шаге.
III. Выберите верхние K строк в преобразованных отсортированных данных.
IV. Затем он присвоит контрольной точке класс на основе наиболее часто встречающегося класса этих строк.
Шаг 4 — Конец
Как определить значение К?
Нам нужно выбрать подходящее значение K для достижения максимальной точности модели, но не существует предопределенных статистических методов для нахождения наиболее благоприятного значения K. Но большинство из них используют метод локтя.
Метод локтя начинается с вычисления суммы квадратов ошибок (SSE) для некоторых значений k. SSE представляет собой сумму квадратов расстояний между каждым членом кластера и его центром тяжести.
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
Если вы нанесете различные значения k на SSE, мы увидим, что ошибка уменьшается по мере того, как значение k становится больше, это происходит потому, что когда количество кластеров увеличивается, кластеры становятся меньше, поэтому искажение также будет меньше. . Идея метода локтя состоит в том, чтобы выбрать k, при котором SSE внезапно уменьшается, что означает форму локтя.
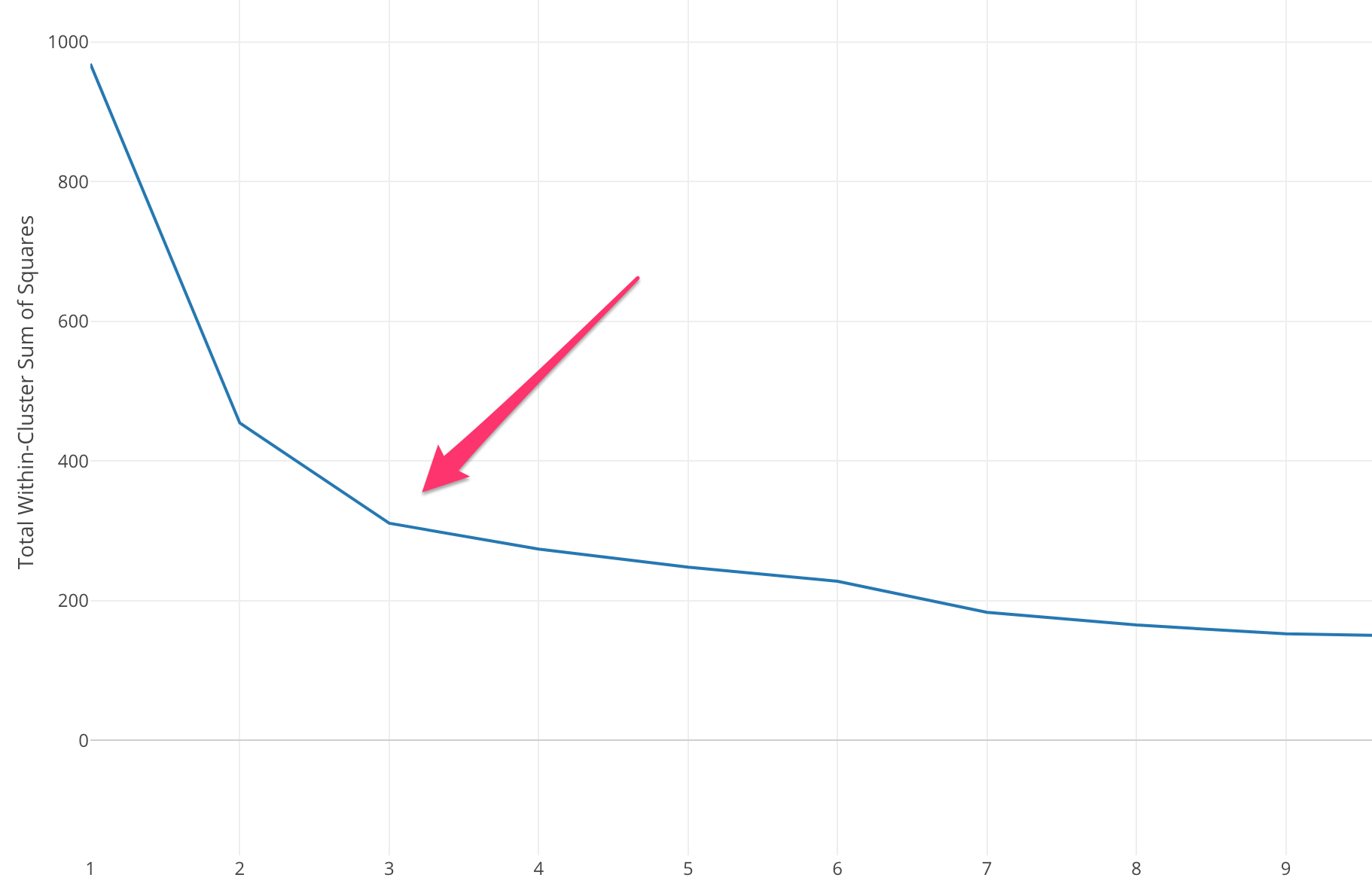
В некоторых случаях имеется более одного локтя или вообще нет локтя. В таких случаях мы обычно заканчиваем вычисление наилучшего k, оценивая, насколько хорошо алгоритм k-means ML работает в контексте проблемы, которую вы пытаетесь решить.
Читайте также: Модели машинного обучения
Типы метрики расстояния
Давайте узнаем о различных показателях расстояния, используемых для расчета расстояния между двумя точками данных одна за другой.

1. Евклидово расстояние. Евклидово расстояние представляет собой квадратный корень из суммы квадратов расстояний между двумя точками.
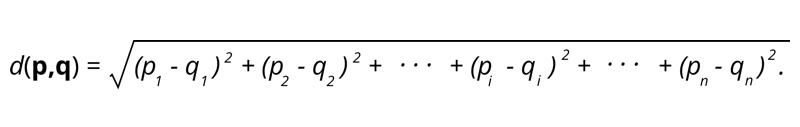 2. Манхэттенское расстояние. Манхэттенское расстояние представляет собой сумму абсолютных значений разностей между двумя точками.
2. Манхэттенское расстояние. Манхэттенское расстояние представляет собой сумму абсолютных значений разностей между двумя точками.
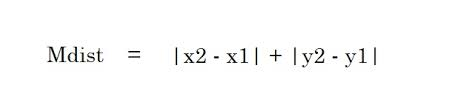 3. Расстояние Минковского. Расстояние Минковского используется для нахождения сходства расстояний между двумя точками. На основе приведенной ниже формулы изменяется либо манхэттенское расстояние (при p = 1), либо евклидово расстояние (при p = 2).
3. Расстояние Минковского. Расстояние Минковского используется для нахождения сходства расстояний между двумя точками. На основе приведенной ниже формулы изменяется либо манхэттенское расстояние (при p = 1), либо евклидово расстояние (при p = 2).
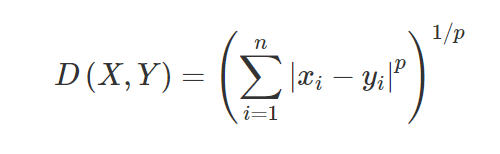 4. Расстояние Хэмминга. Расстояние Хэмминга используется для категориальных переменных. Эта метрика покажет, являются ли две категориальные переменные одинаковыми или нет.
4. Расстояние Хэмминга. Расстояние Хэмминга используется для категориальных переменных. Эта метрика покажет, являются ли две категориальные переменные одинаковыми или нет.
Приложения КНН
Прогнозирование кредитного рейтинга нового клиента на основе уже имеющегося кредитного использования и рейтингов клиентов.
- Одобрять кредит или нет? кандидату.
- Классифицировать данную транзакцию как мошенническую или нет.
- Система рекомендаций (YouTube, Netflix)
- Распознавание рукописного ввода (например, OCR).
- Распознавание изображений.
- Распознавание видео.
Плюсы и минусы КНН
Машинное обучение состоит из множества алгоритмов, поэтому каждый из них имеет свои преимущества и недостатки. В зависимости от отрасли, предметной области и типа данных, а также различных показателей оценки для каждого алгоритма специалист по данным должен выбрать лучший алгоритм, который подходит и отвечает бизнес-задаче. Давайте рассмотрим несколько плюсов и минусов K-ближайших соседей.
Плюсы
- Простота в использовании, понимании и интерпретации.
- Быстрое время расчета.
- Никаких предположений о данных.
- Высокая точность прогнозов.
- Универсальность - может использоваться как для бизнес-задач классификации, так и для регрессии.
- Также может использоваться для многоклассовых задач.
- У нас есть только один гиперпараметр для настройки на этапе настройки гиперпараметра.
Минусы
- Вычислительно дорого и требует большого объема памяти, так как алгоритм хранит все обучающие данные.
- Алгоритм становится медленнее по мере увеличения переменных.
- Он очень чувствителен к несущественным функциям.
- Проклятие размерности.
- Выбор оптимального значения К.
- Несбалансированный набор данных класса вызовет проблемы.
- Отсутствующие значения в данных также вызывают проблемы.
Обязательно к прочтению: идеи проектов машинного обучения
Заключение
Это фундаментальный алгоритм машинного обучения, широко известный простотой использования и быстрым временем вычислений. Это был бы достойный алгоритм, если вы новичок в мире машинного обучения и хотели бы выполнить данную задачу без особых хлопот.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и заданий, IIIT- Статус B Alumni, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Является ли алгоритм K-ближайших соседей дорогим?
В случае огромных наборов данных алгоритм K-ближайших соседей может быть дорогим как с точки зрения времени вычислений, так и с точки зрения хранения. Это связано с тем, что этот алгоритм KNN должен сохранять и хранить все наборы обучающих данных для работы. KNN очень чувствителен к масштабу обучающих данных, поскольку он зависит от расчета расстояний. Этот алгоритм не извлекает результаты на основе предположений об обучающих данных. Несмотря на то, что это может не быть общим случаем, когда вы рассматриваете другие алгоритмы обучения с учителем, алгоритм KNN считается очень эффективным при решении проблем, связанных с нелинейными точками данных.
Каковы некоторые практические применения алгоритма K-NN?
Алгоритм KNN часто используется предприятиями, чтобы рекомендовать продукты людям, которые имеют общие интересы. Например, компании могут предлагать телешоу на основе выбора зрителей, дизайн одежды на основе предыдущих покупок, а также варианты отелей и проживания во время туров на основе истории бронирований. Он также может использоваться финансовыми учреждениями для присвоения кредитных рейтингов клиентам на основе схожих финансовых характеристик. Банки основывают свои решения о выдаче кредита на конкретных заявках, которые, по-видимому, обладают схожими характеристиками с неплательщиками. Расширенные приложения этого алгоритма включают распознавание изображений, обнаружение рукописного ввода с помощью OCR, а также распознавание видео.
Как выглядит будущее для инженеров по машинному обучению?
Благодаря дальнейшим достижениям в области искусственного интеллекта и машинного обучения рынок или спрос на инженеров по машинному обучению выглядит очень многообещающе. Ко второй половине 2021 года в LinkedIn было зарегистрировано около 23 000 вакансий для инженеров по машинному обучению. Глобальные гигантские организации, от Amazon и Google до PayPal, Autodesk, Morgan Stanley, Accenture и других, всегда ищут лучшие таланты. Обладая сильными основами в таких областях, как программирование, статистика, машинное обучение, инженеры также могут взять на себя лидирующие роли в области анализа данных, автоматизации, интеграции ИИ и других областях.