
Algoritmo de vecinos más cercanos en aprendizaje automático [con ejemplos]
Publicado: 2020-10-28Tabla de contenido
Introducción
El aprendizaje automático es, sin duda, una de las tecnologías más potentes y de mayor éxito en el mundo actual impulsado por los datos, en el que recopilamos más cantidad de datos cada segundo. Esta es una de las tecnologías de rápido crecimiento donde cada dominio y cada sector tiene sus propios casos de uso y proyectos.
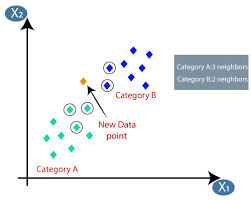
El aprendizaje automático o el desarrollo de modelos es una de las fases del ciclo de vida de un proyecto de ciencia de datos que también parece ser una de las más importantes. Este artículo está diseñado como una introducción a KNN (K-Nearest Neighbors) en Machine Learning.
K-vecinos más cercanos
Si está familiarizado con el aprendizaje automático o ha sido parte del equipo de ciencia de datos o inteligencia artificial, entonces probablemente haya oído hablar del algoritmo k-Nearest Neighbors, o simplemente llamado KNN. Este algoritmo es uno de los algoritmos de referencia utilizados en el aprendizaje automático porque es fácil de implementar, no paramétrico, de aprendizaje perezoso y tiene un tiempo de cálculo bajo.
Otra ventaja del algoritmo k-vecinos más cercanos es que se puede utilizar para problemas de clasificación y regresión. Si no conoce la diferencia entre estos dos, permítame aclararle que la principal diferencia entre la clasificación y la regresión es que la variable de salida en la regresión es numérica (continua), mientras que la de clasificación es categórica (discreta).
Leer: Algoritmos KNN en R
¿Cómo funciona k-vecinos más cercanos?
El algoritmo K-vecinos más cercanos (KNN) utiliza la técnica de 'similitud de características' o 'vecinos más cercanos' para predecir el grupo en el que cae un nuevo punto de datos. A continuación se muestran algunos pasos basados en los cuales podemos comprender mejor el funcionamiento de este algoritmo.

Paso 1 : para implementar cualquier algoritmo en el aprendizaje automático, necesitamos un conjunto de datos limpio y listo para el modelado. Supongamos que ya tenemos un conjunto de datos limpio que se ha dividido en conjuntos de datos de entrenamiento y prueba.
Paso 2 : como ya tenemos los conjuntos de datos listos, debemos elegir el valor de K (entero) que nos dice cuántos puntos de datos más cercanos debemos tener en cuenta para implementar el algoritmo. Podemos llegar a saber cómo determinar el valor de k en las etapas posteriores del artículo.
Paso 3 : este paso es iterativo y debe aplicarse para cada punto de datos en el conjunto de datos
I. Calcule la distancia entre los datos de prueba y cada fila de datos de entrenamiento utilizando cualquiera de las métricas de distancia
un. distancia euclidiana
B. distancia entre manhattan
C. distancia minkowski
D. Distancia de hamming.
Muchos científicos de datos tienden a usar la distancia euclidiana, pero podemos conocer el significado de cada uno en la última etapa de este artículo.
II. Necesitamos ordenar los datos según la métrica de distancia que hemos usado en el paso anterior.
tercero Elija las K filas superiores en los datos ordenados transformados.
IV. Luego, asignará una clase al punto de prueba en función de la clase más frecuente de estas filas.
Paso 4 − Fin
¿Cómo determinar el valor K?
Necesitamos seleccionar un valor de K apropiado para lograr la máxima precisión del modelo, pero no hay métodos estadísticos predefinidos para encontrar el valor de K más favorable. Pero la mayoría de ellos usan el método del codo.
El método del codo comienza con el cálculo de la Suma del error cuadrático (SSE) para algunos valores de k. El SSE es la suma de la distancia al cuadrado entre cada miembro del grupo y su centroide.
SSE=∑Ki=1∑x ∈ cidista(x,ci)2SSE= ∑∑ x ∈ cidista(x,ci)2
Si grafica diferentes valores de k contra el SSE, podemos ver que el error disminuye a medida que el valor de k aumenta, esto sucede porque cuando aumenta el número de grupos, los grupos tenderán a ser más pequeños, por lo que la distorsión también será menor. . La idea del método del codo es elegir la k en la que el SSE disminuye repentinamente, lo que significa la forma del codo.
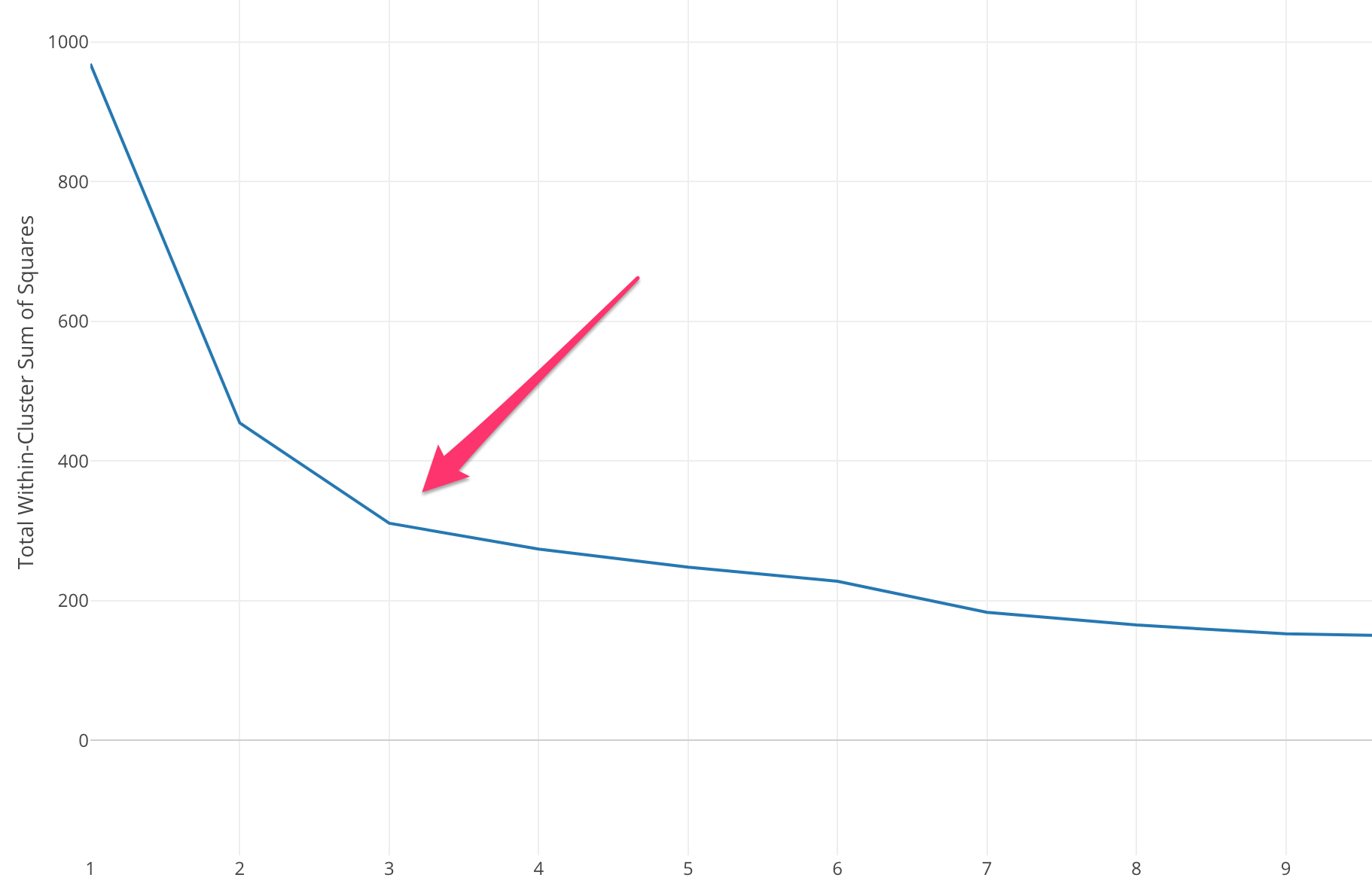
En algunos casos, hay más de un codo o ningún codo. En tales casos, generalmente terminamos calculando el mejor k evaluando qué tan bien se desempeña el algoritmo ML k-means en el contexto del problema que está tratando de resolver.
Lea también: Modelos de aprendizaje automático
Tipos de métrica de distancia
Conozcamos las diferentes métricas de distancia utilizadas para calcular la distancia entre dos puntos de datos uno por uno.

1. Distancia euclidiana: la distancia euclidiana es la raíz cuadrada de la suma de la distancia al cuadrado entre dos puntos.
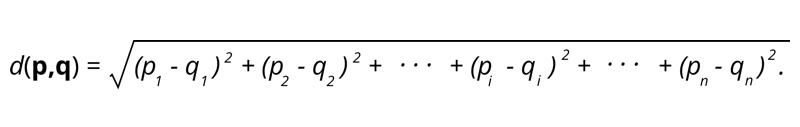 2. Distancia de Manhattan: la distancia de Manhattan es la suma de los valores absolutos de las diferencias entre dos puntos.
2. Distancia de Manhattan: la distancia de Manhattan es la suma de los valores absolutos de las diferencias entre dos puntos.
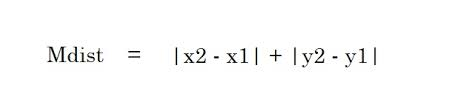 3. Distancia de Minkowski: la distancia de Minkowski se usa para encontrar la similitud de distancia entre dos puntos. Según la fórmula a continuación, cambia a la distancia de Manhattan (cuando p = 1) y la distancia euclidiana (cuando p = 2).
3. Distancia de Minkowski: la distancia de Minkowski se usa para encontrar la similitud de distancia entre dos puntos. Según la fórmula a continuación, cambia a la distancia de Manhattan (cuando p = 1) y la distancia euclidiana (cuando p = 2).
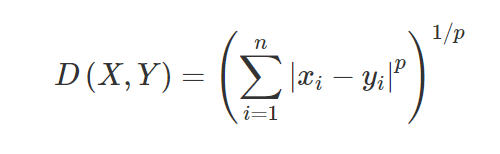 4. Distancia de Hamming: la distancia de Hamming se utiliza para variables categóricas. Esta métrica dirá si dos variables categóricas son iguales o no.
4. Distancia de Hamming: la distancia de Hamming se utiliza para variables categóricas. Esta métrica dirá si dos variables categóricas son iguales o no.
Aplicaciones de KNN
Predecir la calificación crediticia de un nuevo cliente en función de los usos y calificaciones crediticias de los clientes ya disponibles.
- ¿Sancionar o no un préstamo? a un candidato.
- Clasificar una transacción dada es fraudulenta o no.
- Sistema de recomendación (YouTube, Netflix)
- Detección de escritura a mano (como OCR).
- Reconocimiento de imagen.
- Reconocimiento de vídeo.
Pros y contras de KNN
El aprendizaje automático consta de muchos algoritmos, por lo que cada uno tiene sus propias ventajas y desventajas. Dependiendo de la industria, el dominio y el tipo de datos y las diferentes métricas de evaluación para cada algoritmo, un científico de datos debe elegir el mejor algoritmo que se ajuste y responda al problema comercial. Veamos algunos pros y contras de K-vecinos más cercanos.
ventajas
- Fácil de usar, entender e interpretar.
- Tiempo de cálculo rápido.
- Sin suposiciones sobre los datos.
- Alta precisión de las predicciones.
- Versátil: se puede utilizar para problemas comerciales de clasificación y regresión.
- También se puede usar para problemas de clases múltiples.
- Solo tenemos un parámetro Hyper para modificar en el paso de ajuste de hiperparámetros.
Contras
- Computacionalmente costoso y requiere mucha memoria ya que el algoritmo almacena todos los datos de entrenamiento.
- El algoritmo se vuelve más lento a medida que aumentan las variables.
- Es muy sensible a las características irrelevantes.
- Maldición de dimensionalidad.
- Elegir el valor óptimo de K.
- El conjunto de datos de clase desequilibrada causará problemas.
- Los valores faltantes en los datos también causan problemas.
Debe leer: Ideas de proyectos de aprendizaje automático
Conclusión
Este es un algoritmo de aprendizaje automático fundamental que es popularmente conocido por su facilidad de uso y tiempo de cálculo rápido. Este sería un algoritmo decente para elegir si es muy nuevo en Machine Learning World y le gustaría completar la tarea dada sin mucha molestia.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Es caro el algoritmo K-Nearest Neighbors?
En el caso de conjuntos de datos enormes, el algoritmo K-Nearest Neighbors puede ser costoso tanto en términos de tiempo de cómputo como de almacenamiento. Esto se debe a que este algoritmo KNN tiene que guardar y almacenar todos los conjuntos de datos de entrenamiento para que funcione. KNN es muy sensible a la escala de los datos de entrenamiento, ya que depende del cálculo de las distancias. Este algoritmo no obtiene resultados basados en suposiciones sobre los datos de entrenamiento. Aunque este podría no ser el caso general cuando considera otros algoritmos de aprendizaje supervisado, el algoritmo KNN se considera altamente efectivo para resolver problemas que vienen con puntos de datos no lineales.
¿Cuáles son algunas de las aplicaciones prácticas del algoritmo K-NN?
Las empresas suelen utilizar el algoritmo KNN para recomendar productos a personas que comparten intereses comunes. Por ejemplo, las empresas pueden sugerir programas de televisión en función de las elecciones de los espectadores, diseños de ropa en función de compras anteriores y opciones de hotel y alojamiento durante los recorridos en función del historial de reservas. También puede ser empleado por instituciones financieras para asignar calificaciones crediticias a clientes en función de características financieras similares. Los bancos basan sus decisiones de desembolso de préstamos en solicitudes específicas que parecen compartir características similares a las de los morosos. Las aplicaciones avanzadas de este algoritmo incluyen reconocimiento de imágenes, detección de escritura a mano mediante OCR y reconocimiento de video.
¿Cómo se ve el futuro para los ingenieros de aprendizaje automático?
Con nuevos avances en IA y aprendizaje automático, el mercado o la demanda de ingenieros de aprendizaje automático parece muy prometedor. Para la segunda mitad de 2021, había alrededor de 23,000 trabajos listados en LinkedIn para ingenieros de aprendizaje automático. Las organizaciones gigantes globales, desde Amazon y Google hasta PayPal, Autodesk, Morgan Stanley, Accenture y otras, siempre están buscando a los mejores talentos. Con fundamentos sólidos en temas como programación, estadísticas, aprendizaje automático, los ingenieros también pueden asumir roles de liderazgo en análisis de datos, automatización, integración de IA y otras áreas.