
Algoritmo K-Nearest Neighbors em Machine Learning [com exemplos]
Publicados: 2020-10-28Índice
Introdução
O aprendizado de máquina é, sem dúvida, uma das tecnologias mais poderosas e poderosas no mundo atual orientado a dados, onde coletamos mais quantidade de dados a cada segundo. Esta é uma das tecnologias de rápido crescimento, onde cada domínio e cada setor tem seus próprios casos de uso e projetos.
Aprendizado de máquina ou desenvolvimento de modelo é uma das fases do ciclo de vida de um projeto de ciência de dados que parece ser uma das mais importantes também. Este artigo foi desenvolvido como uma introdução ao KNN (K-Nearest Neighbors) em Machine Learning.
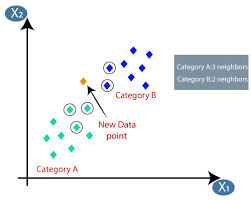
K-vizinhos mais próximos
Se você está familiarizado com aprendizado de máquina ou fez parte da equipe de Data Science ou AI, provavelmente já ouviu falar do algoritmo k-Nearest Neighbors, ou simplesmente chamado de KNN. Esse algoritmo é um dos algoritmos usados em aprendizado de máquina porque é fácil de implementar, não paramétrico, aprendizado preguiçoso e tem baixo tempo de cálculo.
Outra vantagem do algoritmo k-Nearest Neighbors é que ele pode ser usado para problemas do tipo Classificação e Regressão. Se você não tem conhecimento da diferença entre esses dois, deixe-me esclarecer para você, a principal diferença entre Classificação e Regressão é que a variável de saída na regressão é numérica (Contínua) enquanto que para a classificação é categórica (Discreta).
Leia: Algoritmos KNN em R
Como funciona o k-Nearest Neighbors?
O algoritmo K-nearest neighbors (KNN) usa a técnica de 'semelhança de recursos' ou 'vizinhos mais próximos' para prever o cluster no qual um novo ponto de dados se encaixa. Abaixo estão alguns passos com base nos quais podemos entender melhor o funcionamento deste algoritmo

Etapa 1 - Para implementar qualquer algoritmo em Machine Learning, precisamos de um conjunto de dados limpo e pronto para modelagem. Vamos supor que já temos um conjunto de dados limpo que foi dividido em conjunto de dados de treinamento e teste.
Passo 2 − Como já temos os conjuntos de dados prontos, precisamos escolher o valor de K (inteiro) que nos diz quantos pontos de dados mais próximos precisamos levar em consideração para implementar o algoritmo. Podemos saber como determinar o valor de k nas etapas posteriores do artigo.
Etapa 3 - Esta etapa é iterativa e precisa ser aplicada para cada ponto de dados no conjunto de dados
I. Calcule a distância entre os dados de teste e cada linha de dados de treinamento usando qualquer métrica de distância
uma. Distância euclidiana
b. distância de Manhattan
c. distância de Minkowski
d. Distância de Hamming.
Muitos cientistas de dados tendem a usar a distância euclidiana, mas podemos conhecer o significado de cada uma na etapa posterior deste artigo.
II. Precisamos classificar os dados com base na métrica de distância que usamos na etapa acima.
III. Escolha as K linhas superiores nos dados classificados transformados.
4. Em seguida, ele atribuirá uma classe ao ponto de teste com base na classe mais frequente dessas linhas.
Passo 4 - Fim
Como determinar o valor de K?
Precisamos selecionar um valor de K apropriado para obter a máxima precisão do modelo, mas não existem métodos estatísticos pré-definidos para encontrar o valor mais favorável de K. Mas a maioria deles usa o Método do Cotovelo.
O método Elbow começa com o cálculo da Soma do Erro Quadrado (SSE) para alguns valores de k. O SSE é a soma do quadrado da distância entre cada membro do cluster e seu centroide.
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
Se você plotar diferentes valores de k em relação ao SSE, podemos ver que o erro diminui à medida que o valor de k aumenta, isso acontece porque quando o número de clusters aumenta, os clusters tendem a se tornar menores, então a distorção também será menor . A ideia do método do cotovelo é escolher o k no qual o SSE diminui repentinamente, significando a forma do cotovelo.
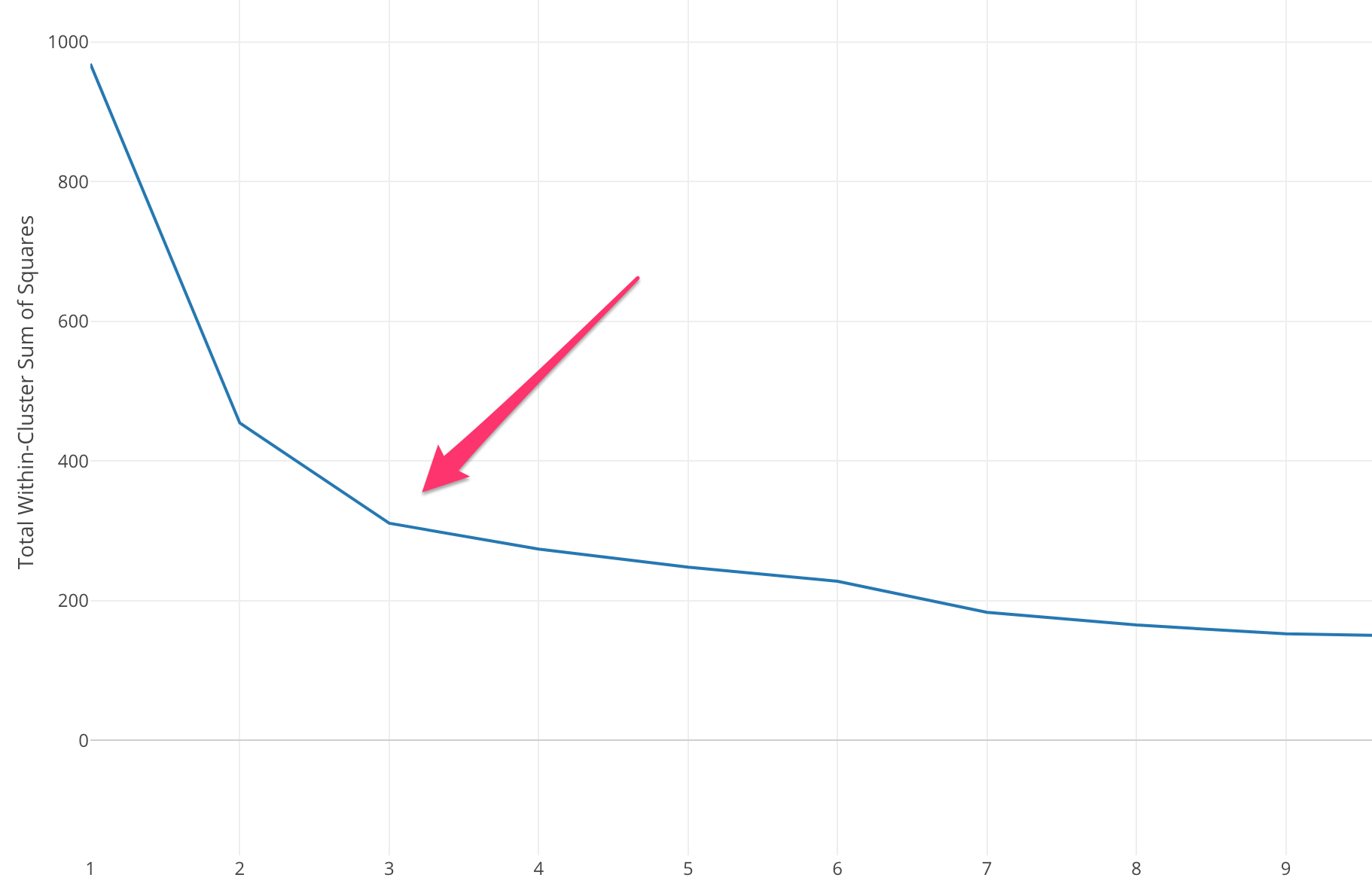
Em alguns casos, há mais de um cotovelo ou nenhum cotovelo. Nesses casos, geralmente acabamos calculando o melhor k avaliando o desempenho do algoritmo ML k-means no contexto do problema que você está tentando resolver.
Leia também: Modelos de aprendizado de máquina
Tipos de métrica de distância
Vamos conhecer as diferentes métricas de distância usadas para calcular a distância entre dois pontos de dados um por um.

1. Distância euclidiana – A distância euclidiana é a raiz quadrada da soma da distância quadrada entre dois pontos.
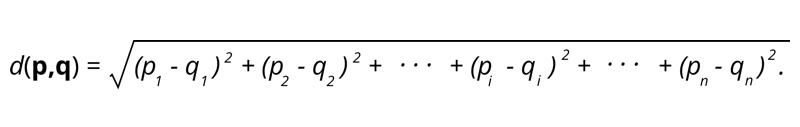 2. Distância de Manhattan – A distância de Manhattan é a soma dos valores absolutos das diferenças entre dois pontos.
2. Distância de Manhattan – A distância de Manhattan é a soma dos valores absolutos das diferenças entre dois pontos.
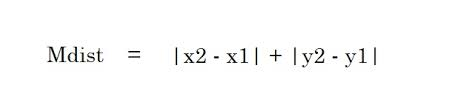 3. Distância de Minkowski – A distância de Minkowski é usada para encontrar a similaridade de distância entre dois pontos. Com base na fórmula abaixo, altera-se a distância de Manhattan (quando p=1) e a distância euclidiana (quando p=2).
3. Distância de Minkowski – A distância de Minkowski é usada para encontrar a similaridade de distância entre dois pontos. Com base na fórmula abaixo, altera-se a distância de Manhattan (quando p=1) e a distância euclidiana (quando p=2).
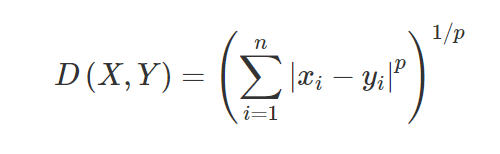 4. Distância de Hamming – A distância de Hamming é usada para variáveis categóricas. Essa métrica informará se duas variáveis categóricas são iguais ou não.
4. Distância de Hamming – A distância de Hamming é usada para variáveis categóricas. Essa métrica informará se duas variáveis categóricas são iguais ou não.
Aplicações de KNN
Prever a classificação de crédito de um novo cliente com base nos usos e classificações de crédito de clientes já disponíveis.
- Sancionar ou não um empréstimo? a um candidato.
- A classificação de determinada transação é fraudulenta ou não.
- Sistema de recomendação (YouTube, Netflix)
- Detecção de manuscrito (como OCR).
- Reconhecimento de imagem.
- Reconhecimento de vídeo.
Prós e contras de KNN
O aprendizado de máquina consiste em muitos algoritmos, portanto, cada um tem suas próprias vantagens e desvantagens. Dependendo do setor, domínio e tipo de dados e diferentes métricas de avaliação para cada algoritmo, um Cientista de Dados deve escolher o melhor algoritmo que se ajuste e responda ao problema de Negócios. Vamos ver alguns prós e contras de K-Nearest Neighbors.
Prós
- Fácil de usar, entender e interpretar.
- Tempo de cálculo rápido.
- Sem suposições sobre os dados.
- Alta precisão das previsões.
- Versátil – Pode ser usado para problemas de negócios de classificação e regressão.
- Também pode ser usado para problemas multiclasse.
- Temos apenas um parâmetro Hyper para ajustar na etapa de ajuste de hiperparâmetro.
Contras
- Computacionalmente caro e requer muita memória, pois o algoritmo armazena todos os dados de treinamento.
- O algoritmo fica mais lento à medida que as variáveis aumentam.
- É muito sensível a recursos irrelevantes.
- Maldição da Dimensionalidade.
- Escolhendo o valor ótimo de K.
- Conjunto de dados de classe desequilibrada causará problemas.
- Valores ausentes nos dados também causam problemas.
Leitura obrigatória: ideias de projetos de aprendizado de máquina
Conclusão
Este é um algoritmo de aprendizado de máquina fundamental que é popularmente conhecido pela facilidade de uso e tempo de cálculo rápido. Este seria um algoritmo decente para escolher se você é muito novo no Machine Learning World e gostaria de concluir a tarefa sem muito aborrecimento.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
O algoritmo K-Nearest Neighbors é caro?
No caso de conjuntos de dados enormes, o algoritmo K-Nearest Neighbors pode ser caro tanto em termos de tempo de computação quanto de armazenamento. Isso ocorre porque esse algoritmo KNN precisa salvar e armazenar todos os conjuntos de dados de treinamento para funcionar. O KNN é altamente sensível à escala dos dados de treinamento, pois depende do cálculo das distâncias. Esse algoritmo não busca resultados com base em suposições sobre os dados de treinamento. Mesmo que esse não seja o caso geral quando você considera outros algoritmos de aprendizado supervisionado, o algoritmo KNN é considerado altamente eficaz na resolução de problemas que vêm com pontos de dados não lineares.
Quais são algumas das aplicações práticas do algoritmo K-NN?
O algoritmo KNN é frequentemente usado por empresas para recomendar produtos a indivíduos que compartilham interesses comuns. Por exemplo, as empresas podem sugerir programas de TV com base nas escolhas dos espectadores, designs de roupas com base em compras anteriores e opções de hotel e acomodação durante os passeios com base no histórico de reservas. Também pode ser empregado por instituições financeiras para atribuir classificações de crédito a clientes com base em características financeiras semelhantes. Os bancos baseiam suas decisões de desembolso de empréstimos em aplicações específicas que parecem compartilhar características semelhantes aos inadimplentes. As aplicações avançadas deste algoritmo incluem reconhecimento de imagem, detecção de manuscrito usando OCR, bem como reconhecimento de vídeo.
Como será o futuro dos engenheiros de aprendizado de máquina?
Com mais avanços em IA e aprendizado de máquina, o mercado ou a demanda por engenheiros de aprendizado de máquina parecem muito promissores. No segundo semestre de 2021, havia cerca de 23.000 empregos listados no LinkedIn para engenheiros de aprendizado de máquina. Organizações gigantes globais, como Amazon e Google, PayPal, Autodesk, Morgan Stanley, Accenture e outras, estão sempre procurando os melhores talentos. Com fortes fundamentos em assuntos como programação, estatística, aprendizado de máquina, os engenheiros também podem assumir papéis de liderança em análise de dados, automação, integração de IA e outras áreas.